
all_reduce
- paddle.distributed. all_reduce ( tensor: Tensor, op: _ReduceOp = 0, group: Group | None = None, sync_op: bool = True ) task [source]
-
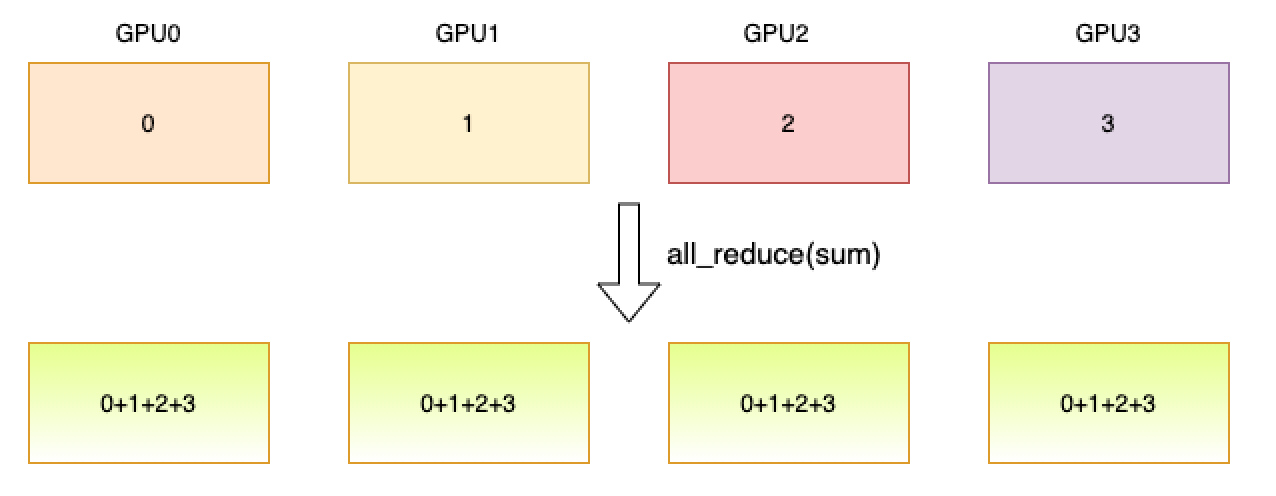
Reduce a tensor over all ranks so that all get the result. As shown below, one process is started with a GPU and the data of this process is represented by its group rank. The reduce operator is sum. Through all_reduce operator, each GPU will have the sum of the data from all GPUs.
- Parameters
-
tensor (Tensor) – The input Tensor. It also works as the output Tensor. Its data type should be float16, float32, float64, int32, int64, int8, uint8 or bool.
op (ReduceOp.SUM|ReduceOp.MAX|ReduceOp.MIN|ReduceOp.PROD|ReduceOp.AVG, optional) – The operation used. Default value is ReduceOp.SUM.
group (Group|None, optional) – The group instance return by new_group or None for global default group.
sync_op (bool, optional) – Whether this op is a sync op. Default value is True.
- Returns
-
Return a task object.
Examples
>>> >>> import paddle >>> import paddle.distributed as dist >>> dist.init_parallel_env() >>> if dist.get_rank() == 0: ... data = paddle.to_tensor([[4, 5, 6], [4, 5, 6]]) >>> else: ... data = paddle.to_tensor([[1, 2, 3], [1, 2, 3]]) >>> dist.all_reduce(data) >>> print(data) >>> # [[5, 7, 9], [5, 7, 9]] (2 GPUs)