
在5月20日结束的2021深度学习开发者峰会WAVE SUMMIT上,百度文心ERNIE开源了四大预训练模型。本文对这四大开源预训练模型进行了详细的技术解读。
2019年以来,NLP预训练模型在技术创新和工业应用上不断取得突破,但当前预训练模型仍有一些痛点困扰着开发者:
仅考虑单一粒度语义建模,缺乏多粒度知识引入,语义理解能力受限;
受限于Transformer结构的建模长度瓶颈,无法处理超长文本;
聚焦语言等单一模态,缺乏工业真实应用场景针对多个模态如语言、视觉、听觉信息的联合建模能力。
5月20日举办的2021深度学习开发者峰会WAVE SUMMIT上,依托飞桨核心框架,百度文心ERNIE最新开源四大预训练模型:多粒度语言知识增强模型ERNIE-Gram、长文本理解模型ERNIE-Doc、融合场景图知识的跨模态理解模型ERNIE-ViL、语言与视觉一体的模型ERNIE-UNIMO。
针对当前预训练模型现存的难点痛点,此次文心ERNIE开源的四大预训练模型不仅在文本语义理解、长文本建模和跨模态理解三大领域取得突破,还拥有广泛的应用场景和前景,进一步助力产业智能化升级。

文心ERNIE开源版地址:
https://github.com/PaddlePaddle/ERNIE
文心ERNIE官网地址:
https://wenxin.baidu.com/
多粒度语言知识增强模型
ERNIE-Gram
从ERNIE模型诞生起,百度研究者们就在预训练模型中引入知识,通过知识增强的方法提升语义模型的能力。本次发布的ERNIE-Gram模型正是通过显式引入语言粒度知识,从而提升模型的效果。具体来说,ERNIE-Gram提出显式n-gram掩码语言模型,学习n-gram粒度语言信息,相对连续的n-gram掩码语言模型大幅缩小了语义学习空间,(V^n→V_(n-gram),其中 V为词表大小,n为建模的gram长度),显著提升预训练模型收敛速度。
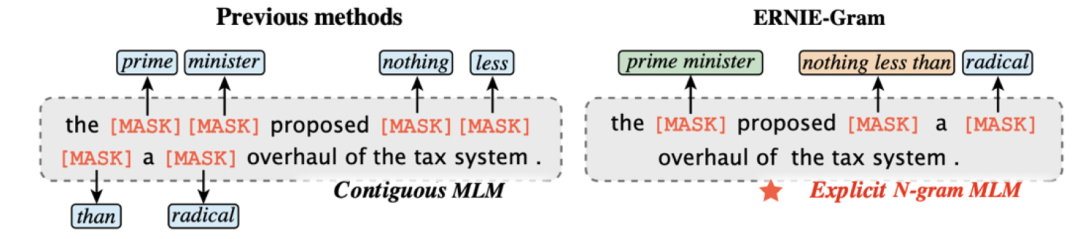
图1-1 连续n-gram掩码语言模型vs显式n-gram掩码语言模型
此外,在显式n-gram语义粒度建模基础上,ERNIE-Gram提出多层次 n-gram语言粒度学习,利用two-stream双流机制,实现同时学习n-gram语言单元内细粒度(fine-grained)语义知识和n-gram语言单元间粗粒度(coarse-grained)语义知识,实现多层次的语言粒度知识学习。
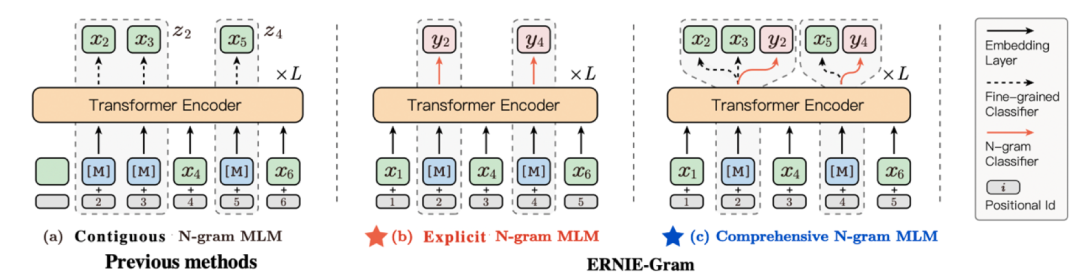
图1-2 n-gram多层次语言粒度掩码学习
ERNIE-Gram在不增加任何计算复杂度的前提下,在自然语言推断任务 、短文本相似度任务、阅读理解任务等多个典型中文任务上,效果显著超越了业界主流开源预训练模型。此外,ERNIE-Gram英文预训练模型也在通用语言理解任务、阅读理解任务上效果超越主流模型。
ERNIE-Gram的方法被NAACL 2021主会长文录用,论文地址:
https://arxiv.org/abs/2010.12148
长文本理解模型
ERNIE-Doc
Transformer是ERNIE预训练模型所依赖的基础网络结构,但由于其计算量和空间消耗随建模长度呈平方级增加,导致模型难以建模篇章、书籍等长文本内容。受到人类先粗读后精读的阅读方式启发,ERNIE-Doc首创回顾式建模技术,突破了Transformer在文本长度上的建模瓶颈,实现了任意长文本的双向建模。
通过将长文本重复输入模型两次,ERNIE-Doc在粗读阶段学习并存储全篇章语义信息,在精读阶段针对每一个文本片段显式地融合全篇章语义信息,从而实现双向建模,避免了上下文碎片化的问题。
此外,传统长文本模型(Transformer-XL等)中Recurrence Memory结构的循环方式限制了模型的有效建模长度。ERNIE-Doc将其改进为同层循环,使模型保留了更上层的语义信息,具备了超长文本的建模能力。
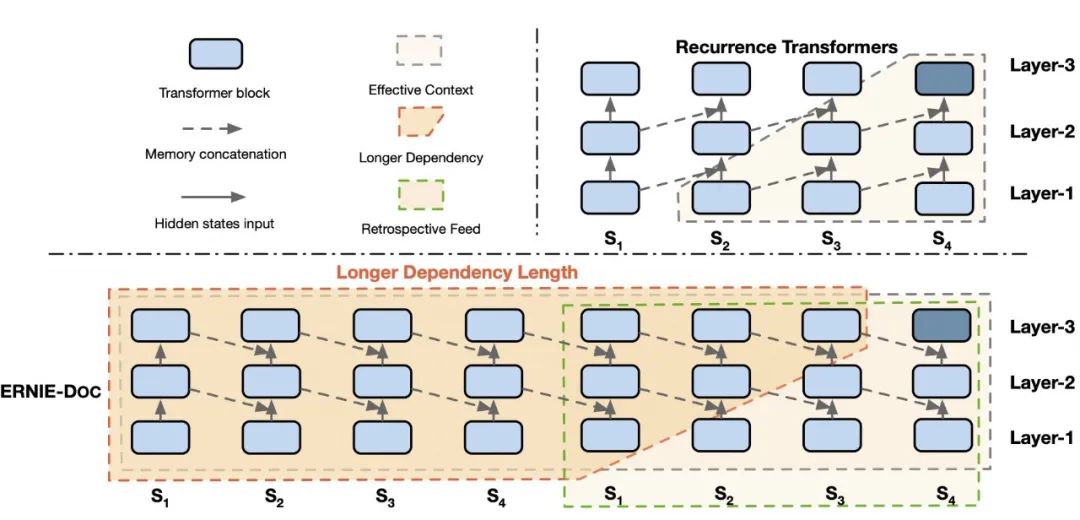
图2-1 ERNIE-Doc中的回顾式建模与增强记忆机制
通过让模型学习篇章级文本段落间的顺序关系,ERNIE-Doc可以更好地建模篇章整体信息。
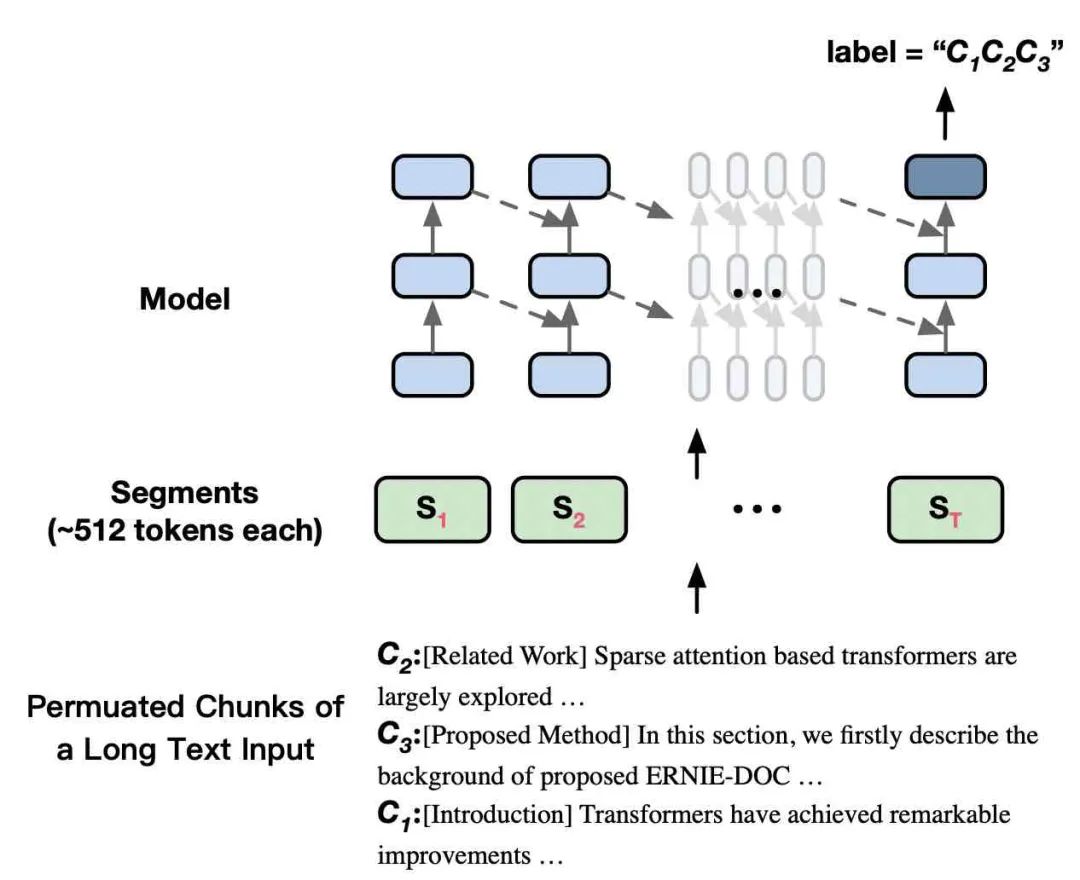
图2-2 篇章重排序学习
ERNIE-Doc显著提升了长文本的建模能力,可以解决很多传统模型无法处理的应用难题。例如在搜索引擎中,ERNIE-Doc可以对网页整体理解,返回用户更加系统的结果。在智能创作中,ERNIE-Doc可以用来生成更加长篇、语义丰富的文章。
超长文本理解模型ERNIE-Doc在包括阅读理解、信息抽取、篇章分类、语言模型等不同类型的13个典型中英文长文本任务上取得最优的效果。
ERNIE-Doc的方法被ACL 2021主会长文录用,论文链接:
https://arxiv.org/abs/2012.15688
融合场景图知识的
跨模态理解模型
ERNIE-ViL
跨模态的信息处理能力需要人工智能模型深入理解并综合语言、视觉、听觉等模态的信息。当前,基于预训练的跨模态语义理解技术,通过对齐语料学习跨模态的联合表示,将语义对齐信号融合到联合表示中,从而提升跨模态语义理解能力。ERNIE-ViL提出了知识增强的视觉-语言预训练模型,将包含细粒度语义信息的场景图(Scene Graph)知识融入预训练过程,构建了物体预测、属性预测、关系预测三个预训练任务,使得模型在预训练过程中更加关注细粒度语义知识,学习到能够刻画更好跨模态语义对齐信息,得到更好的跨模态语义表示。
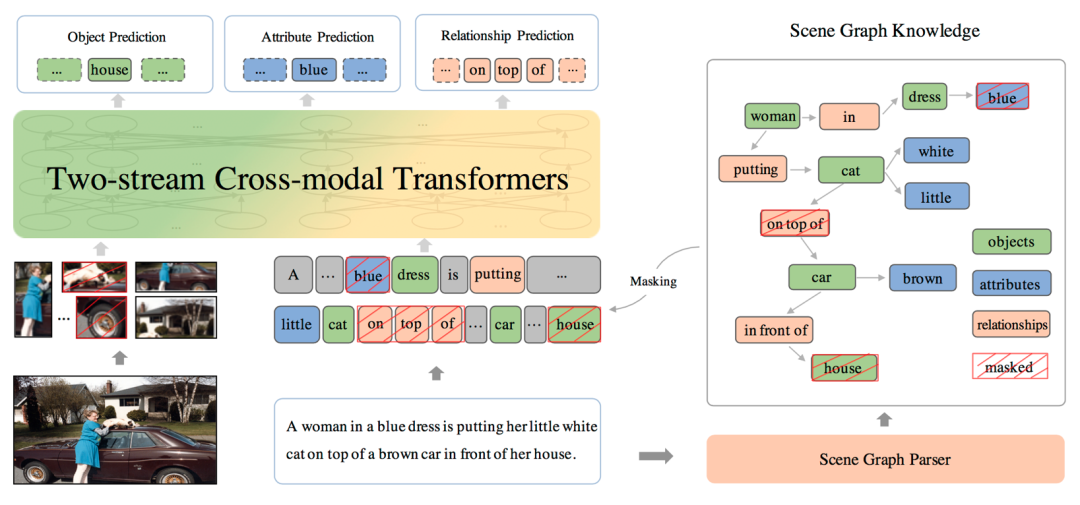
图3-1知识增强的跨模态预训练ERNIE-ViL框架
ERNIE-ViL首次将场景图知识融入跨模态模型的预训练过程,为跨模态语义理解领域研究提供了新的思路。该模型在视觉问答、视觉常识推理、引用表达式理解、跨模态文本&图像检索等5个典型跨模态任务上取得了领先的效果。ERNIE-ViL模型也逐步在视频搜索等真实工业应用场景中落地。
ERNIE-ViL的方法被AAAI-2021主会长文录用,论文地址:
https://arxiv.org/abs/2006.16934
语言与视觉一体的模型
ERNIE-UNIMO
大数据是深度学习取得成功的关键基础之一。当前的预训练方法,通常分别在各种不同模态数据上分别进行,难以同时支持各类语言和图像的任务。基于深度学习的AI系统是否也能像人一样同时学习各种单模、多模等异构模态数据呢?如果能够实现,无疑将进一步打开深度学习对大规模数据利用的边界,从而进一步提升AI系统的感知与认知的通用能力。
为此,语言与视觉一体的模型ERNIE-UNIMO提出统一模态学习方法,同时使用单模文本、单模图像和多模图文对数据进行训练,学习文本和图像的统一语义表示,从而具备同时处理多种单模态和跨模态下游任务的能力。此方法的核心模块是一个Transformer网络,在具体训练过程中,文本、图像和图文对三种模态数据随机混合在一起,其中图像被转换为目标(object)序列,文本被转换为词(token)序列,图文对被转换为目标序列和词序列的拼接。统一模态学习对三种类型数据进行统一处理,在目标序列或者词序列上基于掩码预测进行自监督学习,并且基于图文对数据进行跨模态对比学习,从而实现图像与文本的统一表示学习。进一步的,这种联合学习方法也让文本知识和视觉知识互相增强,从而有效提升文本语义表示和视觉语义表示的能力。
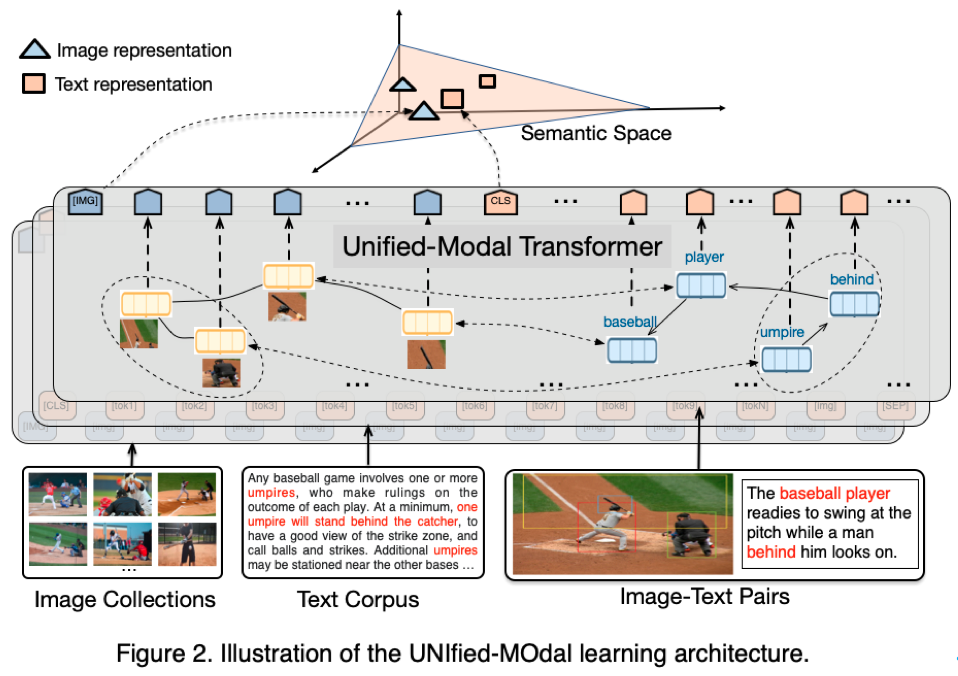
此方法在语言理解与生成、多模理解与生成,4类场景、共13个任务上超越主流的文本预训练模型和多模预训练模型,同时登顶权威视觉问答榜单VQA、文本推理榜单aNLI。首次验证了通过非平行的文本与图像单模数据,能够让语言知识与视觉知识相互增强。
此工作被ACL2021主会长文录用,论文地址:
https://arxiv.org/abs/2012.15409
破解NLP技术难题
助力产业智能化
文心ERNIE全新开源发布4大预训练模型,不断推动NLP模型技术研究层面的创新与应用。
语言与知识技术被看作是人工智能认知能力的核心。2019年以来,百度凭借在自然语言处理领域的深厚积累取得了系列世界突破,发布了文心ERNIE语义理解平台,该平台广泛用于金融、通信、教育、互联网等行业,助力产业智能化升级。
作为“人工智能皇冠上的明珠”,NLP领域向来是人工智能技术研发与落地实践的前沿。百度文心平台基于领先的语义理解技术,帮助企业在NLP赛道上跨过技术、工具、算力、人才等门槛,对开发者和企业进行开放,全面加速NLP技术助力全产业智能化升级进程,为AI工业大生产插上智能的“翅膀”。
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,是中国首个开源开放、技术领先、功能完备的产业级深度学习平台,包括飞桨开源平台和飞桨企业版。飞桨开源平台包含核心框架、基础模型库、端到端开发套件与工具组件,持续开源核心能力,为产业、学术、科研创新提供基础底座。飞桨企业版基于飞桨开源平台,针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END
