
项目背景与相关介绍
SimNet:百度自研的语义匹配框架,使用BOW、CNN、GRU、LSTM等核心网络作为表示层,在百度内搜索、推荐等多个应用场景得到广泛应用。
ernie-matching:基于ERNIE/ERNIE-Gram使用语义匹配数据集LCQMC完成中文句对匹配任务,提供了Pointwise和Pairwise两种类型学习方式。
Sentence-Transformers:基于Siamese双塔网络结构的文本匹配模型,可以使用ERNIE/BERT/RoBERTa等模型获取文本的向量化表示。
什么是文本匹配?
信息检索:在信息检索领域的很多应用中,都需要根据原文本来检索与其相似的其他文本,使用场景非常普遍。
新闻推荐:通过用户刚刚浏览过的新闻标题,自动检索出其他的相似新闻,个性化地为用户做推荐,从而增强用户粘性,提升产品体验。
智能客服:用户输入一个问题后,自动为用户检索出相似的问题和答案,节约人工客服的成本,提高效率。
让我们来看一个简单的例子,比较各候选句子哪句和原句语义更相近
原句:“车头如何放置车牌”
比较句1:“前牌照怎么装”
比较句2:“如何办理北京车牌”
比较句3:“后牌照怎么装”
(1)比较句1与原句,虽然句式和语序等存在较大差异,但是所表述的含义几乎相同。
(2)比较句2与原句,虽然存在“如何” 、“车牌”等共现词,但是所表述的含义完全不同。
(3)比较句3与原句,二者讨论的都是如何放置车牌的问题,只不过一个是前牌照,另一个是后牌照。二者间存在一定的语义相关性。
什么是文本相似度任务?
文本相似度任务流程包含如下6个步骤:
数据读取:根据网络接收的数据格式,完成相应的预处理操作,保证模型正常读取;
模型构建:设计基于ERNIE的文本相似度模型,判断两句话是否相似;
训练配置:实例化模型,选择模型计算资源(CPU或GPU),指定模型迭代的优化算法;
模型训练与保存:执行多轮训练不断调整参数,以达到较好的效果,保存模型;
模型评估:训练好的模型在验证集上进行评估;
模型预测:加载训练好的模型,并进行预测;
准备工作
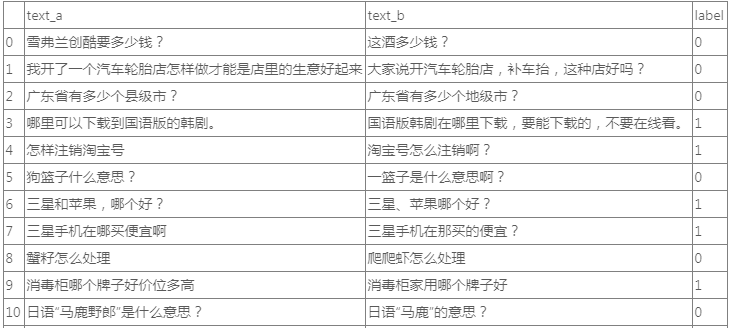
数据集格式
index text_a text_b label
1 经济适用房能贷款吗? 经济适用房能贷款吗 1
2 兔子有什么颜色 兔子是什么颜色的? 1
3 您是要注册支付宝的账户吗 注销成功就可以认证其他的支付宝账户了 0
4 建议您在联系卖家看看的哦 满就送彩票业务代发代扣.建议您联系淘宝的客服核实. 0
5 支付宝如何解冻? 支付宝怎样提现 1
6 怎样让自己快速长高 怎样可以快速长高? 1
7 这图片是什么电影? 这是什么电影的图片 1
8 红楼梦的主题曲是什么? 红楼梦的主题曲是什么 1
9 写合肥春节习俗,短一点的,语言简洁 春节的习俗,短一点的,100字以下的 0
本项目基于PaddlePaddle/ERNIE进行模型训练和预测,安装ERNIE代码如下:
!pip install paddle-ernie==0.0.4.dev1
定义数据集,包括数据集路径、tokenizer、batch_size等参数。
class Classification_Dataset():
def __init__(self, dataset_dir, max_seq_len=128, batch_size=8):
self.dataset_dir = dataset_dir
self.dataset_name = dataset_dir.split('/')[-1]
self.train_datas = self.loader(os.path.join(dataset_dir, 'data/data90036/baidu_train.tsv'))
self.dev_datas = self.loader(os.path.join(dataset_dir, 'data/data90036/baidu_dev.tsv'))
self.test_datas = self.loader(os.path.join(dataset_dir, 'data/data90036/test_forstu.tsv'), True)
self.tokenizer = ErnieTokenizer.from_pretrained('ernie-1.0')
self.max_seq_len = max_seq_len
self.batch_size = batch_size模型训练
设置模型参数,可以自行尝试对下述参数进行修改调试,提高模型的效果。
configs = {
'batch_size': 128, # 数据批大小
'max_seq_len': 128, # 最大文本长度
'epoch': 10, # 训练轮数
'dataset_dir': './', # 数据集文件夹
'warmup_proportion': 0.01, # 模型预热比例设置
'max_steps': 5000, # 最大步数
'weight_decay': 0.1, # 权重衰减比例
'learning_rate': 5e-5, # 学习率
'use_gpu': True, # 是否使用GPU训练
'log_step': 20, # 打印log间隔
'eval_step': 200, # 评估间隔
'save_dir': 'save', # 模型保存路径, 包含模型文件和测试集预测输出文件
'load_model': 'best_model', # 预测时加载的模型:最佳模型best_model, 最终模型final_model
}
模型训练代码
# 导入需要用到的模块,包括ernie中的优化器和模型等
import paddle.nn as nn
from ernie.optimization import AdamW, LinearDecay
from ernie.modeling_ernie import ErnieModel, ErnieModelForSequenceClassification
# 根据模型选择预训练模型进行加载
model = ErnieModelForSequenceClassification.from_pretrained(
'ernie-1.0',
num_labels=2,
name='')
# 学习率与优化器设置
learning_rate = LinearDecay(
configs['learning_rate'],
int(configs['warmup_proportion'] * configs['max_steps']),
configs['max_steps'])
optimizer = AdamW(
learning_rate=learning_rate,
parameter_list=model.parameters(),
weight_decay=configs['weight_decay'])
# 记录总步数和运行时间
global_step = 0
tic_train = time.time()
# 开始训练
for epoch in range(configs['epoch']):
model.train()
for step, data in enumerate(dataset.get_data('train')):
input_ids, token_type_ids, labels = data
probs = model(input_ids=input_ids, token_type_ids=token_type_ids)
loss = criterion(probs, labels)
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
global_step += 1
if global_step % 20 == 0:
print("global step %d, epoch: %d, batch: %d, loss: %.5f, accu: %.5f, speed: %.2f step/s" % (global_step, epoch, step, loss, acc, 10 / (time.time() - tic_train)))
tic_train = time.time()
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
# 每间隔 500 step 在验证集上进行评估
if global_step % 500 == 0:
evaluate(model, criterion, metric, dataset.get_data('dev', False))
# 保存模型参数
save_dir = os.path.join(configs['save_dir'], "model_%d" % global_step)
os.makedirs(configs['save_dir'])
save_param_path = os.path.join(configs['save_dir'], 'model_state.pdparams')
paddle.save(model.state_dict(), save_param_path)
tokenizer.save_pretrained(configs['save_dir'])
模型预测
加载训练完成的模型参数进行预测
# 模型加载
model = ErnieModelForSequenceClassification.from_pretrained(
'ernie-1.0',
num_labels=2,
name='')
# 读取保存的模型参数
para_state_dict, _ = paddle.load (join(configs['save_dir'], configs['load_model']))
# 设置模型参数
print('loading the model params...')
model.set_dict(para_state_dict)
# 模型推理
model.eval()
results = []
for step, data in enumerate(dataset.get_data('test', False)):
input_ids, token_type_ids = data
input_ids = paddle.to_tensor(input_ids)
token_type_ids = paddle.to_tensor(token_type_ids)
batch_prob = model(input_ids=input_ids, token_type_ids=token_type_ids).numpy()
result = np.argmax (batch_prob, axis=1) \
results.append(result)
results = np.concatenate(results, 0)
最后的预测结果都保存在results中,根据results生成提交文件
import pandas as pd
import csv
# 读取测试集文件
test_file = 'data/data90036/test_forstu.tsv'
data = pd.read_csv(test_file, sep='\t')
print(data.shape)
# 将预测结果写入输出文件中
data['label'] = results
print(data.shape)
data.to_csv('result.csv',sep='\t')提交csv内容大致如下:
总结

飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体,是中国首个自主研发、功能丰富、开源开放的产业级深度学习平台。飞桨企业版针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END

