算法速度优化遇到瓶颈,达不到要求?应用环境没有高性能硬件只有CPU?
是不是直接戳中了各位开发者的痛点!莫慌,今天小编就来为万千开发者破局~
这个破局点就是:针对CPU设备及加速库MKLDNN定制的骨干网络PP-LCNet!
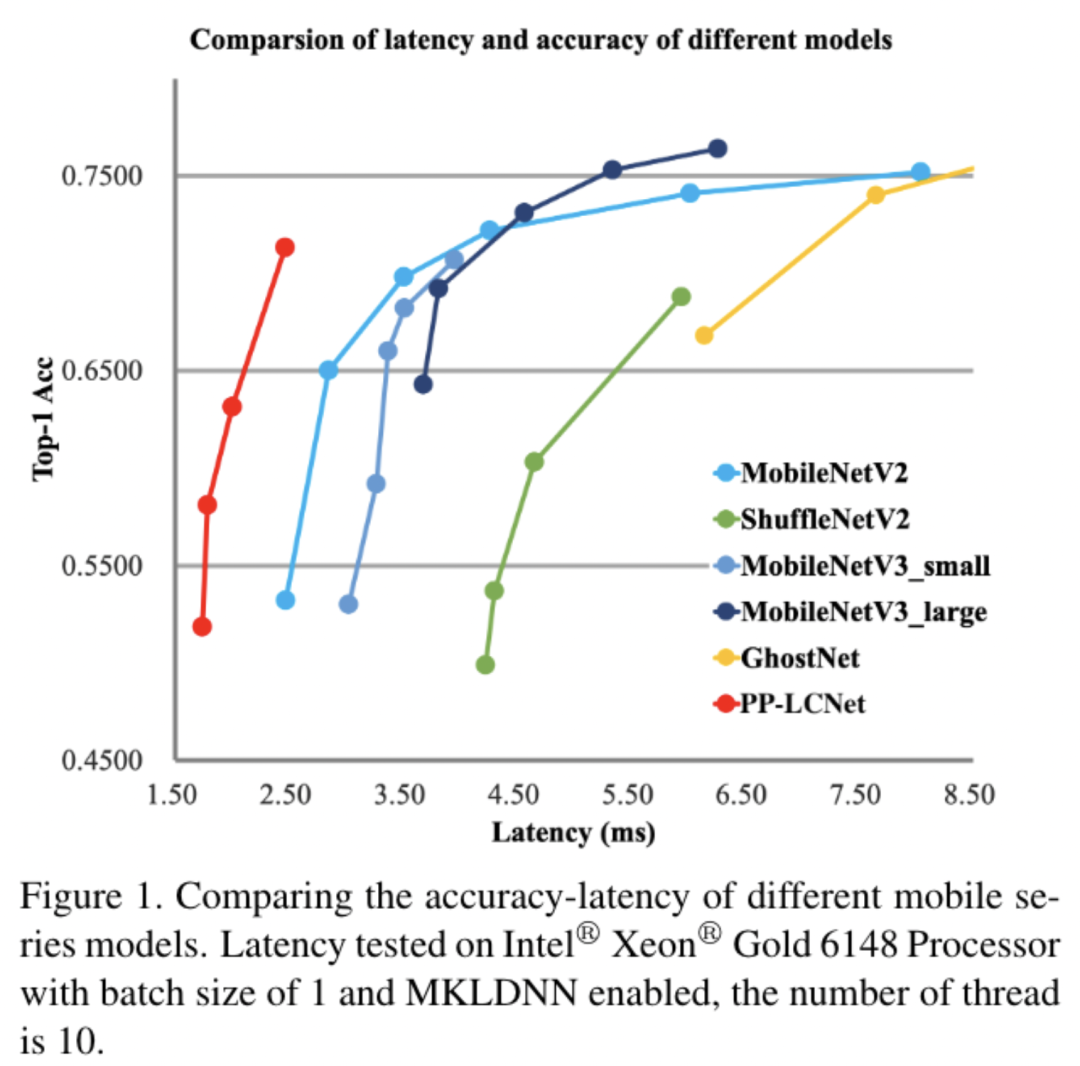
空口无凭,上图为证!
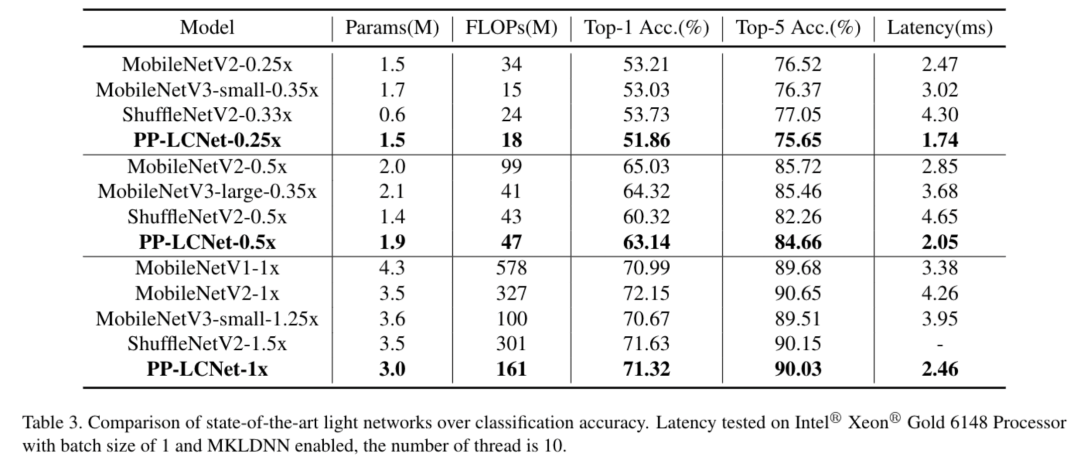
从上图我们可以看出,PP-LCNet在同样精度的情况下,速度远超当前所有的骨架网络,最多可以有2倍的性能优势!它应用在比如目标检测、语义分割等任务算法上,也可以使原本的网络有大幅度的性能提升~
而这个PP-LCNet的论文发布和代码开源后,也着实引来了众多业界开发者的关注,各界大神把PP-LCNet应用在YOLO系列算法上也真实带来了极其可观的性能收益。
这时候是不是有小伙伴已经按耐不住也想直接上手试试了?!
小编识趣地赶紧送上开源代码的传送门 ⬇️ 大家一定要Star收藏以免走失,也给开源社区一些认可和鼓励。
https://github.com/PaddlePaddle/PaddleClas
而这个PP-LCNet到底是如何设计,从而有这么好的性能的呢?下面小编就带大家来领略一下:
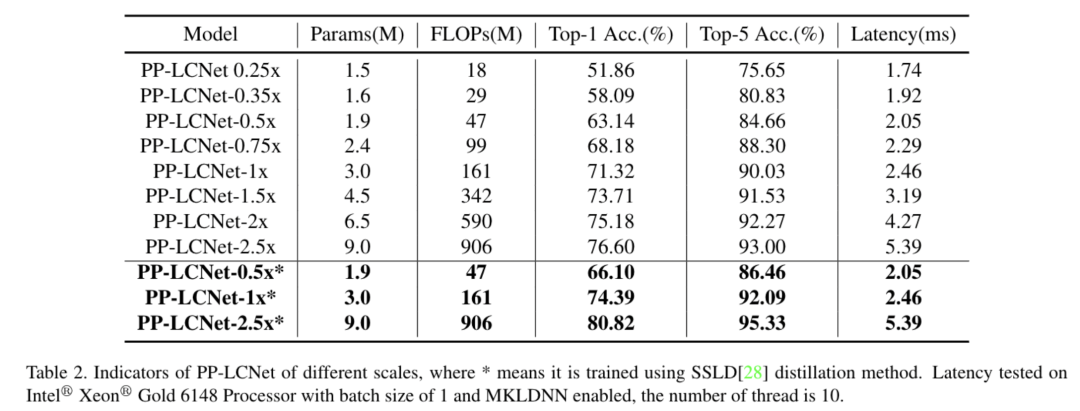
近年来,很多轻量级的骨干网络问世,各种NAS搜索出的网络尤其亮眼。但这些算法的优化都脱离了产业最常用的Intel CPU设备环境,加速能力也往往不合预期。百度飞桨图像分类套件PaddleClas基于这样的产业现状,针对Intel CPU及其加速库MKLDNN定制了独特的高性能骨干网络PP-LCNet。比起其他的轻量级SOTA模型,该骨干网络可以在不增加推理时间的情况下,进一步提升模型的性能,最终大幅度超越现有的SOTA模型。
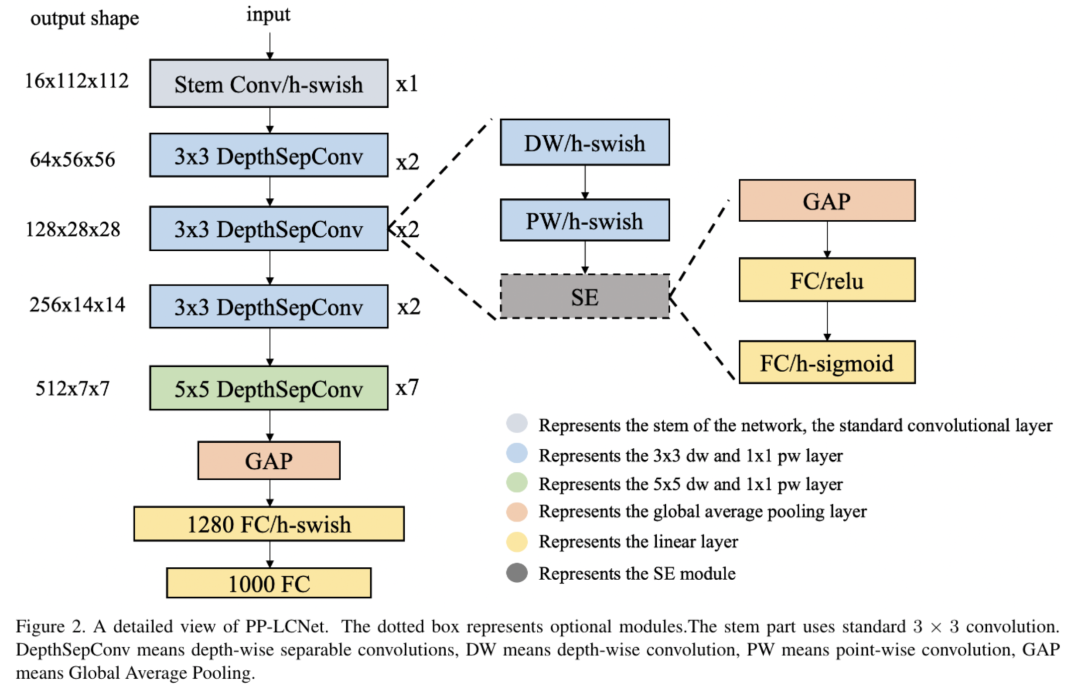
PP-LCNet的网络结构整体如上图所示。我们经过大量的实验发现,在基于Intel CPU的设备上,尤其当启用MKLDNN加速库后,很多看似不太耗时的操作反而会增加延时,比如elementwise-add操作、split-concat结构等。所以最终我们选用了结构尽可能精简、速度尽可能快的block组成我们的BaseNet(类似MobileNetV1)。基于BaseNet,我们通过实验,总结出四条几乎不增加延时但又能够提升模型精度的方法,下面将对这四条策略进行详细介绍:
更好的激活函数
自从卷积神经网络使用了ReLU激活函数后,网络性能得到了大幅度提升。近些年ReLU激活函数的变体也相继出现,如Leaky-ReLU、P-ReLU、ELU等。2017年,谷歌大脑团队通过搜索的方式得到了swish激活函数,该激活函数在轻量级网络上表现优异。在2019年,MobileNetV3的作者将该激活函数进一步优化为H-Swish,该激活函数去除了指数运算,速度更快,网络精度几乎不受影响。我们也经过很多实验发现该激活函数在轻量级网络上有优异的表现。所以在PP-LCNet中,我们选用了该激活函数。
合适的位置添加SE模块
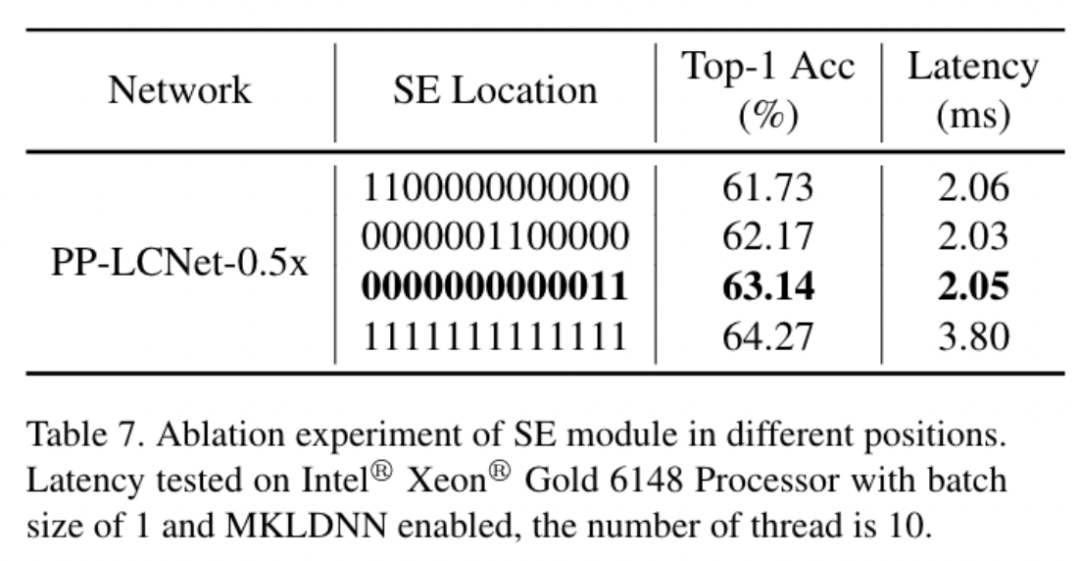
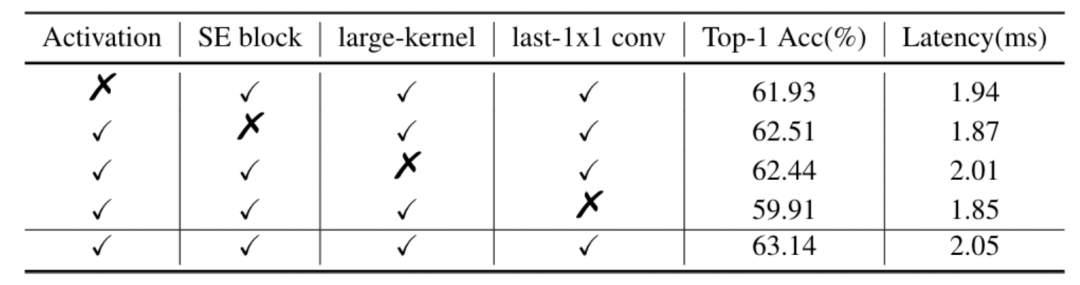
SE模块是SENet提出的一种通道注意力机制,可以有效提升模型的精度。但是在Intel CPU端,该模块同样会带来较大的延时,如何平衡精度和速度是我们要解决的一个问题。虽然在MobileNetV3等基于NAS搜索的网络中对SE模块的位置进行了搜索,但是并没有得出一般的结论。我们通过实验发现,SE模块越靠近网络的尾部对模型精度的提升越大。下表也展示了我们的一些实验结果:
最终,PP-LCNet中的SE模块的位置选用了表格中第三行的方案。
更大的卷积核
在MixNet的论文中,作者分析了卷积核大小对模型性能的影响,结论是在一定范围内大的卷积核可以提升模型的性能,但是超过这个范围会有损模型的性能,所以作者组合了一种split-concat范式的MixConv,这种组合虽然可以提升模型的性能,但是不利于推理。我们通过实验总结了一些更大的卷积核在不同位置的作用,类似SE模块的位置,更大的卷积核在网络的中后部作用更明显,下表展示了5x5卷积核的位置对精度的影响:
实验表明,更大的卷积核放在网络的中后部即可达到放在所有位置的精度,与此同时,获得更快的推理速度。PP-LCNet最终选用了表格中第三行的方案。
GAP后使用更大的1x1卷积层
在GoogLeNet之后,GAP(Global-Average-Pooling)后往往直接接分类层,但是在轻量级网络中,这样会导致GAP后提取的特征没有得到进一步的融合和加工。如果在此后使用一个更大的1x1卷积层(等同于FC层),GAP后的特征便不会直接经过分类层,而是先进行了融合,并将融合的特征进行分类。这样可以在不影响模型推理速度的同时大大提升准确率。
BaseNet经过以上四个方面的改进,得到了PP-LCNet。下表进一步说明了每个方案对结果的影响:
下游任务
性能惊艳提升
图像分类
图像分类我们选用了ImageNet数据集,相比目前主流的轻量级网络,PP-LCNet在相同精度下可以获得更快的推理速度。当使用百度自研的SSLD蒸馏策略后,精度进一步提升,在Intel CPU端约5ms的推理速度下ImageNet的Top-1 Acc竟然超过了80%,Amazing!!!
目标检测
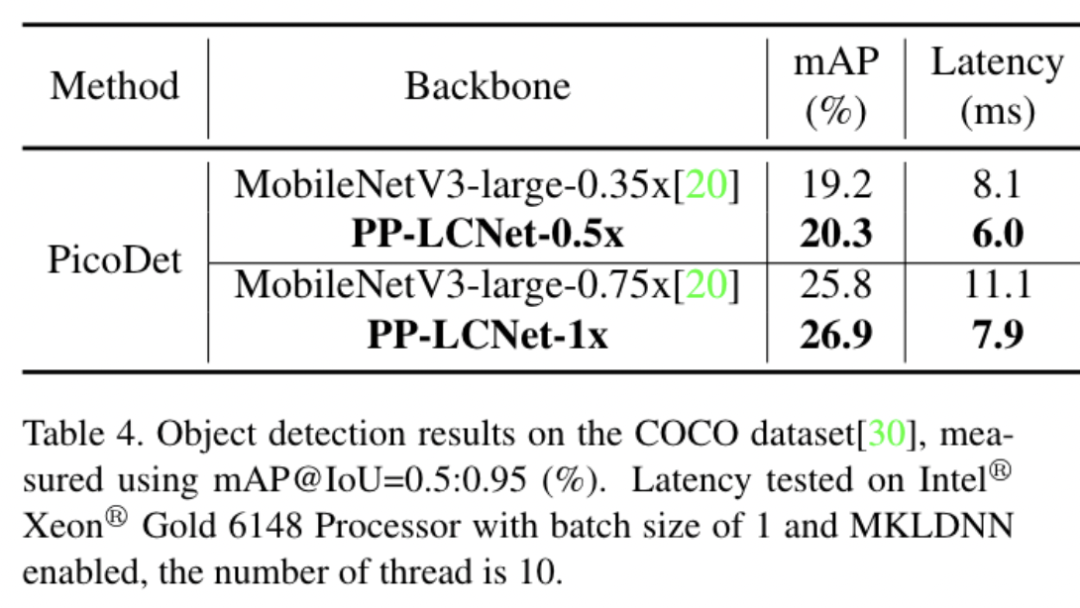
目标检测的方法我们选用了百度自研的PicoDet,该方法主打轻量级目标检测场景。下表展示了在COCO数据集上、backbone选用PP-LCNet与MobileNetV3的结果的比较。无论在精度还是速度上,PP-LCNet的优势都非常明显。
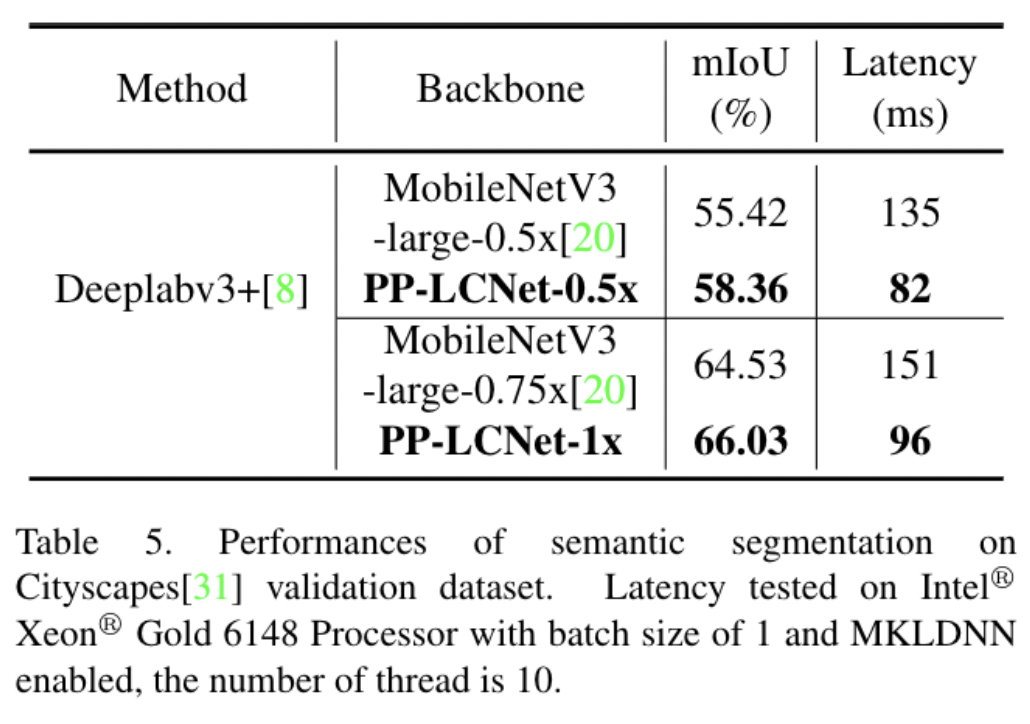
语义分割
语义分割的方法我们选用了DeeplabV3+。下表展示了在Cityscapes数据集上、backbone选用PP-LCNet与MobileNetV3的比较。在精度和速度方面,PP-LCNet的优势同样明显。
实际拓展应用结果说明
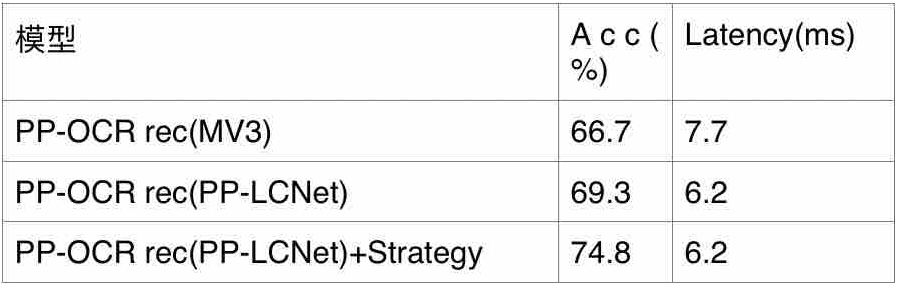
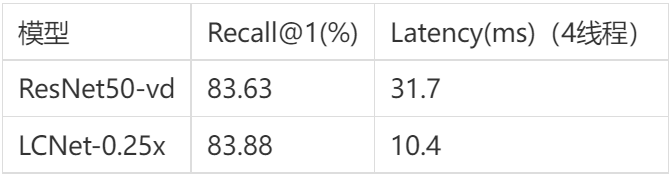
PP-LCNet在计算机视觉下游任务上表现很出色,那在真实的使用场景如何呢?本节简述其在PP-OCR v2、PP-ShiTu上的表现。
在PP-OCR v2上,只将识别模型的backbone由MobileNetV3替换为PP-LCNet后,在速度更快的同时,精度可以进一步提升。
在PP-ShiTu中,将Backbone的ResNet50_vd替换为PP-LCNet-2.5x后,在Intel-CPU端,速度快3倍,recall@1基本和ResNet50_vd持平。
PP-LCNet并不是追求极致的FLOPs与Params,而是着眼于深入技术细节,耐心分析如何添加对Intel CPU友好的模块来提升模型的性能来更好地进行准确率和推理时间的平衡,其中的实验结论也很适合其他网络结构设计的研究者,同时也为NAS搜索研究者提供了更小的搜索空间和一般结论。
自论文发出以来,PP-LCNet引起了国内外学术界和产业界的广泛关注,无论是各类版本的复现,还是极具探索意义和实用价值的各类视觉任务应用和技术分析文章层出不穷,将简单模型的实用性优化方案重新带入大家的视野,真正践行技术让“生活”更美好的初心,期待PP-LCNet在实际落地和应用中的更多表现。
前面提到的论文,链接如下:
https://arxiv.org/pdf/2109.15099.pdf
本论文工作的总体研究思路由飞桨PaddleClas团队提出并实施。PaddleClas提供全球首个开源通用图像识别系统,并力求为工业界和学术界提供更高效便捷的开发工具,为开发者带来更流畅优质的使用体验,训练出更好的飞桨视觉模型,实现行业场景实现落地应用。想要获取更多PaddleClas相关介绍及教程文档可前往⬇️:
GitHub:
https://github.com/PaddlePaddle/PaddleClas
长按下方二维码立即
Star

更多信息:
飞桨官方QQ群:793866180
飞桨官网网址:
www.paddlepaddle.org.cn/
飞桨开源框架项目地址:
GitHub:
github.com/PaddlePaddle/Paddle
Gitee:
gitee.com/paddlepaddle/Paddle
欢迎在飞桨论坛讨论交流~~
http://discuss.paddlepaddle.org.cn