部署"桨"坛栏目聚焦AI硬件部署,分享多款厂商硬件部署方案及教程,帮助开发者们实现模型训练与推理的一体化开发和多硬件设备间的无缝切换。
近年来,伴随着移动端和边缘端处理器能力上限的不断被突破,越来越多的深度学习算法被工程师们部署应用到该类型平台上。硬件方面,Arm作为该领域关键厂商,持续引领和推动该领域创新。软件方面,飞桨轻量化推理引擎Paddle Lite一直持续提升基于Arm技术的平台支持能力。因此,飞桨与Arm在建设移动端和边缘端软硬件生态方面展开了长期的深度合作。
在过去的一段时间,为了提升Paddle Lite在Arm Cortex-A系列的CPU和Arm Mali系列GPU上的综合性能,使用户获得更好的开发体验,飞桨研发团队与ARM Compute Library团队开展了更加紧密的合作,并针对不同的Arm架构的指令特性,开展了多场景下计算与访存优化等方面的技术交流协作。
在此基础上,飞桨研发团队基于对Paddle Lite中部分重点算子的分析,结合Arm Compute Library团队的既有经验,从多个可能的维度尝试优化算子实现,包括但不限于:
1.针对Arm Cortex-A CPU场景:
考虑到Cortex-A53/A35所对应的mul指令特性,对汇编实现进行了指令重排优化。
根据不同处理器中寄存器数目的差异,在特定计算中实现了多种自适应分块策略。
结合数据特点,优化逻辑并调整计算策略来减少冗余计算量。
2.针对Arm Mali GPU场景:
根据Mali GPU架构的数据访问特点,利用Buffer-Object实现算子高效存取。
特化1x1Conv的实现,优化多线程计算逻辑。
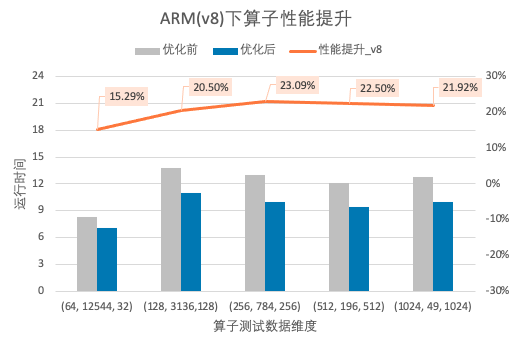
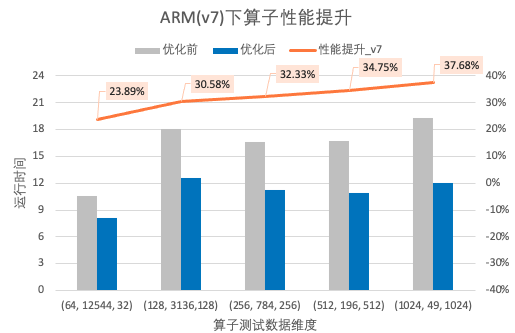
通过上述几点优化以及其它通用/非通用的优化手段,Paddle Lite模型在Cortex-A CPU和Mali GPU上获得了非常可观的性能提升,同时部分模型的精度也相较优化前有了一定改善。经测试,算子性能在v7与v8架构的Cortex-A CPU下最高分别有23.09%和23.33%的提升;典型模型的性能提升也比较明显。
图1. Arm(v8) CPU算子性能提升
图2. Arm(v7) CPU算子性能提升
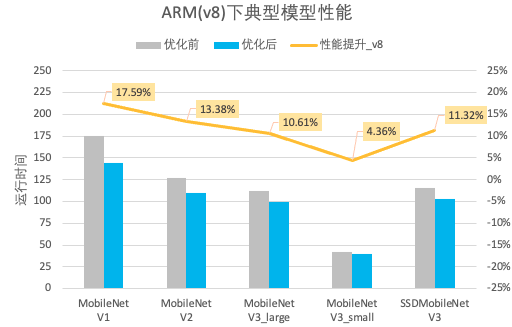
图3. Arm(v8) 典型模型性能提升
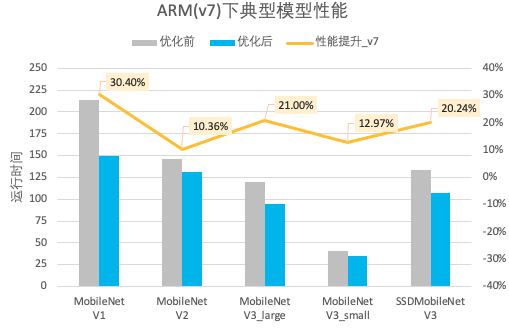
图4. Arm(v7) 典型模型性能提升
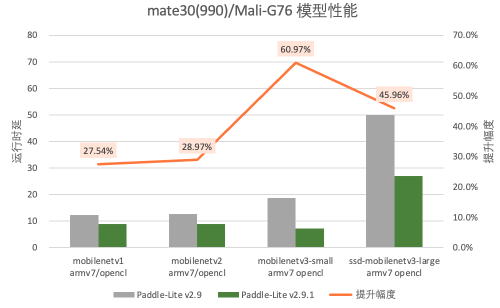
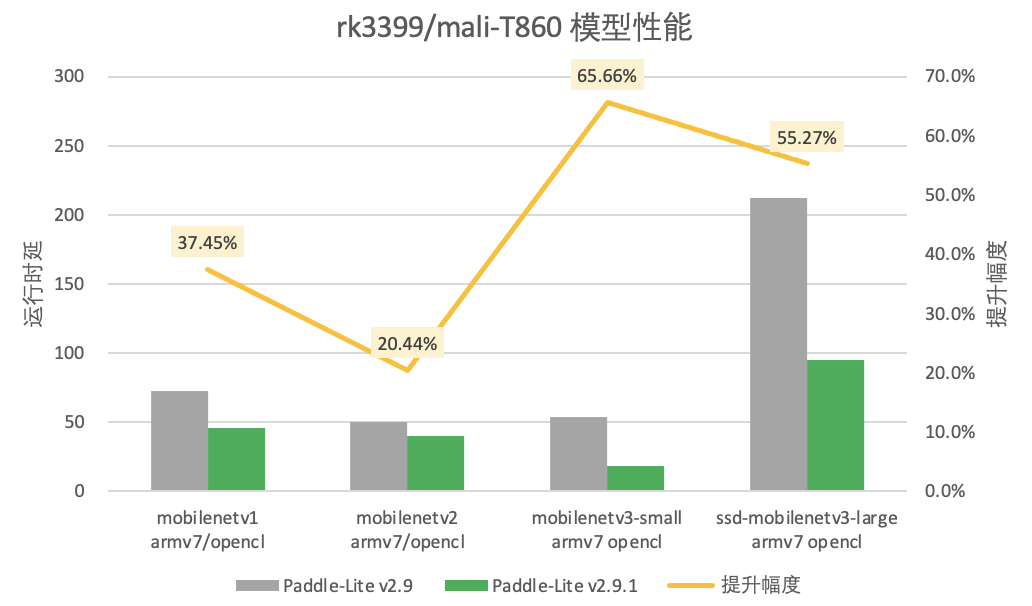
而在Mali-GPU推理的场景下,Mali-G76和Mali-T860上运行模型的整体性能最高提升了60.97%和65.66%。
图5. Mali-G76(OpenCL)在Mate30中的模型性能提升
图6. Mali-T860(OpenCL)在rk3399中的模型性能提升
受益于双方合作所带来的性能提升,飞桨轻量化推理引擎Paddle Lite作为承载众多移动端与边缘端推理任务的重要平台,其模型运行效率的提升明显改善了实际业务应用中最终用户的体验。反映在实际的手机端业务中,我们以长按识图、扫一扫二维码等功能入口中最为重要的通用视觉检测模型为例,经过本次优化,该模型获得了22%的性能加速以及3.4个点的精度提升。而Paddle Lite在端侧的算子数量、运行效率、框架稳定性方面不断增强的绝对能力,也使今后更多拥有更复杂结构和更高性能要求的算法模型在移动端与边缘端的部署成为了可能。
目前所有的优化成果已在 Paddle Lite v2.9及以后版本中对外发布,飞桨研发团队会在今后的工作中继续与Arm联手,持续优化Arm Cortex-A及Mali GPU上的算子和模型性能,为我们的开发者和用户提供更高性能更易用的推理平台。
在今天公众号的二条中,会带来在“周易”AIPU上部署飞桨模型(基于R329开发板)的教程,欢迎感兴趣的朋友继续阅读。
为了向大家提供更易用、更好用的AI推理部署工具,我们诚邀您参与调研,点击“阅读原文”欢迎分享您使用推理部署工具时的需求和期待!
如有相关AI硬件部署的技术问题,欢迎加入飞桨硬件部署交流群提问交流:609865659 (QQ群)
部署“桨”坛第一期回顾: