部署"桨"坛栏目聚焦AI硬件部署,分享多款厂商硬件部署方案及教程,帮助开发者们实现模型训练与推理的一体化开发和多硬件设备间的无缝切换。(往期文章链接见文末)
概述
本文以钢卷捆带检测项目为例(详细案例介绍请看文末),分享如何基于OpenVINO实现飞桨模型的CPU推理加速,主要包括:
Windows及Linux平台下的OpenVINO源码编译;
(1)模型训练部分:
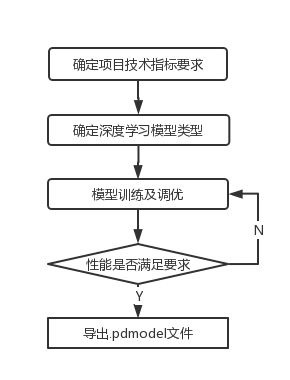
搭建飞桨开发环境及模型训练
1.配置飞桨框架
python -m pip install paddlepaddle-gpu==2.1.3.post112 -f https://www.paddlepaddle.org.cn/whl/windows/mkl/avx/stable.html
2.1安装pycocotools
PaddleDetection依赖pycocotools工具,所以需要提前安装。如果使用的是Windows系统,由于原版cocoapi不支持Windows,pycocotools依赖可能安装失败,可采用第三方实现版本,该版本仅支持Python3,本文所安装的pycocotools版本为2.0。
pipinstallgit+https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI
官方文档推荐了以下两种方式进行安装,本文采用了方式一。
方式一:通过pip安装,pip安装方式只支持Python3
# pip安装PaddleDetection
pip install paddledet==2.1.0 -i https://mirror.baidu.com/pypi/simple
# 下载使用源码中的配置文件和代码示例
git clone https://github.com/PaddlePaddle/PaddleDetection.git
cd PaddleDetection
# 克隆PaddleDetection仓库
cd <path/to/clone/PaddleDetection>
git clone https://github.com/PaddlePaddle/PaddleDetection.git
# 编译安装PaddleDetection
cd PaddleDetection
python setup.py install
# 安装其他依赖
pip install -r requirements.txt
3.模型训练及导出
“30分钟快速上手PaddleDetection”。
在进行模型训练时,损失函数、mAP等指标的变化情况也可通过VisualDL可视化工具监测。
在模型训练过程中保存的模型文件是包含前向预测和反向传播的过程,在实际的工业部署则不需要反向传播,因此需要将模型进行导出并转换成部署需要的模型格式。在PaddleDetection中提供了 tools/export_model.py脚本来导出模型。
├── inference_model/yolov3
│ ├── infer_cfg.yml
│ ├── model.pdiparams
│ ├── model.pdiparams.info
│ └── model.pdmodel
OpenVINO源码编译
1.Windows平台编译
1.1软件需求
1.2编译步骤
1)拉取OpenVINO的source安装包
git clone https://github.com/openvinotoolkit/openvino.git
2)进入OV目录
cd openvino
3)下载所需的sub模块
git submodule update --init --recursive
4)创建 build 文件夹
mkdir build
5)进入build目录
cd build
6)创建cmake文件(如果此步失败,重新执行前请务必把build文件夹里的生成文件清除)注意加粗处需修改。
cmake -CMAKE_USE_WIN32_THREADS_INIT=0N -DNGRAPH_PDPD_FRONTEND_ENABLE=ON -DENABLE_SAMPLES=OFF -DENABLE_CLDNN=OFF -DENABLE_PYTHON=ON -DNGRAPH_PYTHON_BUILD_ENABLE=ON -DNGRAPH_ONNX_IMPORT_ENABLE=ON -DCMAKE_INSTALL_PREFIX="D:\Openvino\openvino\build\install" -DNGRAPH_UNIT_TEST_ENABLE=ON -DNGRAPH_USE_SYSTEM_PROTOBUF=OFF -DPYTHON_EXECUTABLE="D:\Anaconda3\envs\ov\python.exe" -DPYTHON_LIBRARY="D:\Anaconda3\envs\ov\libs\python36.lib" -DPYTHON_INCLUDE_DIR="D:\Anaconda3\envs\ov\include" -DCMAKE_EXPORT_COMPILE_COMMANDS=ON -DENABLE_GNA=OFF -DENABLE_CLANG_FORMAT=ON -DENABLE_TESTS=ON -DENABLE_FUNCTIONAL_TESTS=ON -DENABLE_STRICT_DEPENDENCIES=OFF -DENABLE_MYRIAD=OFF -DENABLE_FASTER_BUILD=ON -DDNNL_LIBRARY_TYPE=SHARED -G "Visual Studio 16 2019" -A x64 -DCMAKE_BUILD_TYPE=Release ..
其中:
-DPYTHON_EXECUTABLE="C:\Users\abc\AppData\Local\Programs\Python\Python36\python.exe"
-DPYTHON_LIBRARY="C:\Users\abc\AppData\Local\Programs\Python\Python36\libs\python36.lib"
-DPYTHON_INCLUDE_DIR="C:\Users\abc\AppData\Local\Programs\Python\Python36\include"
以上需要根据你的python安装路径进行修改为你的路径。
-DCMAKE_INSTALL_PREFIX="C:\openvino\openvino\build\install"
以上需要修改为你的build的文件夹的位置。
注意:若以上编译方式一直失败,无法解决问题,可尝试使用只加python相关参数进行编译。
cmake -DENABLE_PYTHON=
ON -DNGRAPH_PYTHON_BUILD_ENABLE=
ON -DPYTHON_EXECUTABLE=
"D:\Anaconda3\envs\ov\python.exe" -DPYTHON_LIBRARY=
"D:\Anaconda3\envs\ov\libs\python36.lib" -DPYTHON_INCLUDE_DIR=
"D:\Anaconda3\envs\ov\include" -G
"Visual Studio 16 2019" -A x64 -DCMAKE_BUILD_TYPE=Release ..
cmake --build . --config Release --verbose -j8
j后面的数字需要根据自己电脑CPU核数来修改,本文所用电脑为8核。
如果编译过程中遇到中文字符不可识别的报错问题,定位到源码中的相关行,把报错的中文字符行直接注释掉即可。
编译完成后只要是没有报错(红色error),应该就是成功了。编译过程中会有大量的警告(黄色warning),忽略即可。
将以下路径添加至系统环境变量中,以便OpenVINO能找到他们:
进入到scripts/setupvars路径,在cmd中运行setupvars.bat,显示[setupvars.bat] OpenVINO environment initialized,则表示完成环境变量的初始化。
至此,Windows平台下的编译安装就完成了,可以使用OpenVINO了。
2.Linux平台编译
1)按照官方文档1-4步骤进行
2)编译
cmake -DNGRAPH_PDPD_FRONTEND_ENABLE=ON -DENABLE_SAMPLES=OFF -DENABLE_CLDNN=OFF -DENABLE_PYTHON=ON -DNGRAPH_PYTHON_BUILD_ENABLE=ON -DENABLE_MYRIAD=OFF -DNGRAPH_ONNX_IMPORT_ENABLE=ON -DCMAKE_INSTALL_PREFIX=`pwd`/install -DNGRAPH_UNIT_TEST_ENABLE=ON -DNGRAPH_USE_SYSTEM_PROTOBUF=OFF -DPYTHON_EXECUTABLE=$(which python3) -DCMAKE_EXPORT_COMPILE_COMMANDS=ON -DENABLE_GNA=OFF -DENABLE_CLANG_FORMAT=ON -DENABLE_TESTS=ON -DENABLE_FUNCTIONAL_TESTS=ON -DENABLE_STRICT_DEPENDENCIES=OFF \
-DENABLE_FASTER_BUILD=ON \
-DDNNL_LIBRARY_TYPE=SHARED \
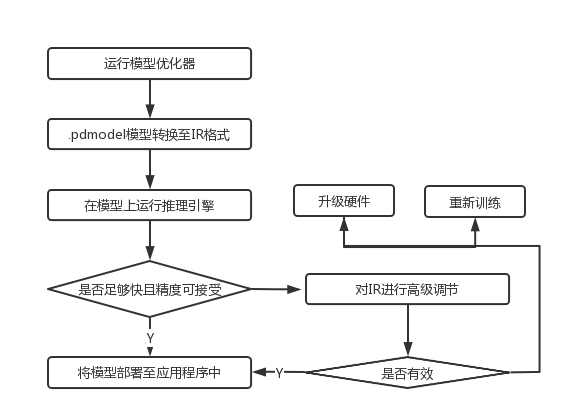
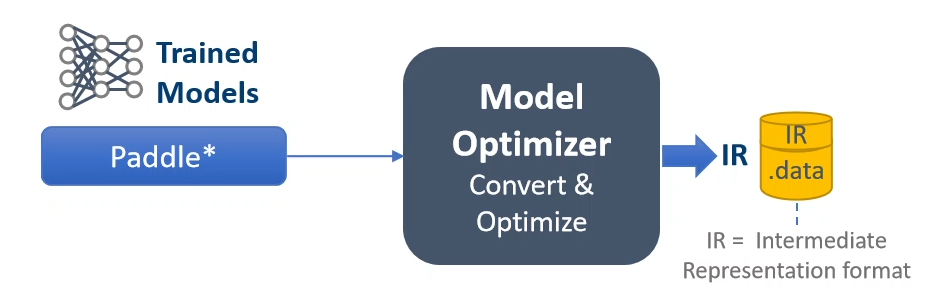
模型转换
1.进入到openvino/model-optimizer路径
2.模型转换
目前OpenVINO对飞桨的支持度较好,无需中间格式转换,可通过mo.py脚本直接将飞桨模型转换成IR格式,需要我们做的就是指定模型类型、模型的输入输出、路径等各项参数,整个过程非常地高效和便捷。示例代码如:
python mo.py --model_name yolov3_mobilenet_v1_270e_coco \
--output_dir <PATH_TO_OUTPUT_DIR> \
--framework=paddle \
--data_type=FP32 \
--reverse_input_channels \
--input_shape=[2,3,608,608],[1,2],[1,2] \
--input=image,im_shape,scale_factor \
--output=save_infer_model/scale_0.tmp_1,save_infer_model/scale_1.tmp_1 \
--input_model= < PATH_TO_MODEL_DIR\model.pdmodel>
推理加速测试
import os, sys, os.path
os.environ['Path'] += r'D:\openvino\bin\intel64\Release\python_api\python3.6;'
import numpy as np
import cv2
from openvino.inference_engine import IENetwork, IECore, ExecutableNetwork
import time
import urllib, shutil, json
import yaml
from yaml.loader import SafeLoader
## 图像处理
def image_preprocess(input_image, size):
img = cv2.resize(input_image, (size,size))
img = np.transpose(img, [2,0,1]) / 255
img = np.expand_dims(img, 0)
##NormalizeImage: {mean: [0.485, 0.456, 0.406], std: [0.229, 0.224, 0.225], is_scale: True}
img_mean = np.array([0.485, 0.456,0.406]).reshape((3,1,1))
img_std = np.array([0.229, 0.224, 0.225]).reshape((3,1,1))
img -= img_mean
img /= img_std
return img.astype(np.float32)
## 绘制矩形框
def draw_box(img, results, label_text, scale_x, scale_y):
for i in range(len(results)):
#print(results[i])
bbox = results[i, 2:]
label_id = int(results[i, 0])
score = results[i, 1]
if(score>0.20):
xmin, ymin, xmax, ymax = [int(bbox[0]*scale_x), int(bbox[1]*scale_y),
int(bbox[2]*scale_x), int(bbox[3]*scale_y)]
cv2.rectangle(img,(xmin, ymin),(xmax, ymax),(0,255,0),3)
font = cv2.FONT_HERSHEY_SIMPLEX
label_text = label_list[label_id];
cv2.rectangle(img, (xmin, ymin), (xmax, ymax), (0,255,0), 2)
cv2.putText(img, label_text + ":" + str(score) ,(xmin,ymin+50), font, 1.5,(255,255,255), 2,cv2.LINE_AA)
return img
device = 'CPU'
ie = IECore()
yolov3_path = r"C:\Users\uzel\Desktop\openvino_workspace\mo_output\yolov3_mobilenet_v1_091511.xml" #指定模型路径
net = ie.read_network(yolov3_path)
exec_net = ie.load_network(net, "CPU")
label_list = []
pdmodel_config = r"C:\Users\uzel\Desktop\openvino_workspace\mo_output\infer_cfg.yml"
with open(pdmodel_config) as f:
data = yaml.load(f, Loader=SafeLoader)
label_list = data['label_list']
input_image = cv2.imread(r"C:\Users\uzel\Desktop\openvino_workspace\demo\images\Image__2021-05-14__10-28-55.bmp")
test_image = image_preprocess(input_image, 608)
test_im_shape = np.array([[608, 608]]).astype('float32')
test_scale_factor = np.array([[1, 2]]).astype('float32')
inputs_dict = {'image': test_image, "im_shape": test_im_shape,
"scale_factor": test_scale_factor}
start_time = time.time()
output = exec_net.infer(inputs_dict)
end_time = time.time()
print("time: %.2f ms" % (1000 * (end_time-start_time)) )
time = str(np.round(1000 * (end_time-start_time))) + "ms"
cv2.putText(input_image, "cost time :" + time ,(20,50), cv2.FONT_HERSHEY_SIMPLEX, 2,(0,0,0), 2,cv2.LINE_AA)
result_ie = list(output.values())
result_image = draw_box(input_image, result_ie[0], label_list,input_image.shape[1]/608*2, input_image.shape[0]/608*2)
cv2.imwrite("test.png", result_image)


案例介绍