作者有话说
解题思路
设计思路
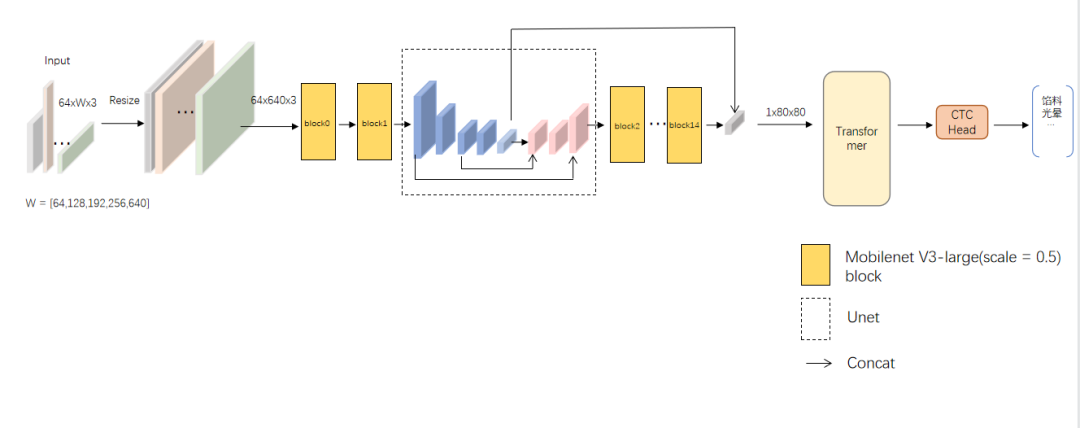
1.整体流程
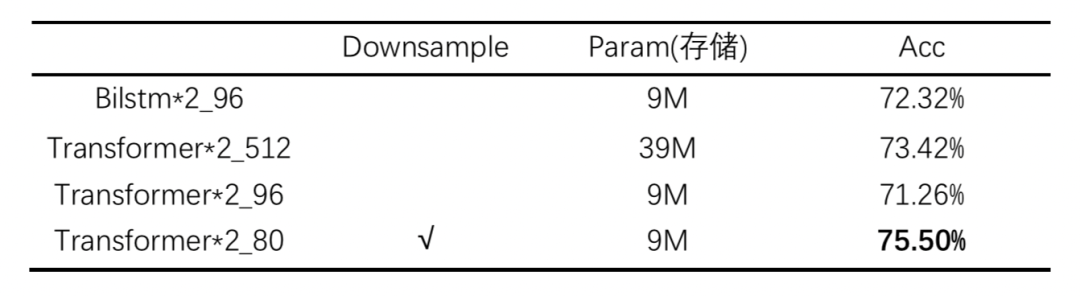
这里产生了第一个问题,Transformer模型的参数量极大。Transformer模型分为Encoder和Decoder两个模块,我们这里只取了Encoder模块。诚然Decoder模块的类 Attention机制可以为识别增强强大的语义信息,但对于参数量和精度来说,性价比并不高。CTC会是一个简洁高效且性价比更高的选择。所以我们在编码部分选择了Transformer的Encoder,在解码部分选择了CTC。针对数据集中存在的图片模糊、遮挡、多字体等情况,我们选择Backbone去增强这方面的特征提取能力,并在初始阶段选择Mobilenet。
2.Transformer
class TransformerPosEncoder(nn.Layer):
def __init__(self, max_text_length=35, num_heads=8,
num_encoder_tus=2, hidden_dims=96,width=80):
super(TransformerPosEncoder, self).__init__()
self.max_length = max_text_length
self.num_heads = num_heads
self.num_encoder_TUs = num_encoder_tus
self.hidden_dims = hidden_dims
self.width =width
# Transformer encoder
t = 35 #256
c = 96
self.wrap_encoder_for_feature = WrapEncoderForFeature(
#... 省略部分配置参数...
d_key=int(self.hidden_dims / self.num_heads),
d_value=int(self.hidden_dims / self.num_heads),
d_inner_hid=self.hidden_dims*2, #2,
#... 省略部分配置参数...
)
def forward(self, conv_features):
# feature_dim = conv_features.shape[1]
feature_dim = self.width
encoder_word_pos = paddle.to_tensor(np.array(range(0, feature_dim)).reshape(
(feature_dim, 1)).astype('int64'))
enc_inputs = [conv_features, encoder_word_pos, None]
out = self.wrap_encoder_for_feature(enc_inputs)
return out3.Downsample Neck
1.通过最大池化(2,2)-> (2*160*640)
class Im2Seq_downsample(nn.Layer):
def __init__(self, in_channels, out_channels=80, patch=2*160, conv_name='conv_patch',**kwargs):
super().__init__()
self.out_channels = out_channels
self.patch = patch
if out_channels == 512:
self.use_resnet = True
else:
self.use_resnet = False
self.conv1 = ConvBNLayer(
in_channels=in_channels,
out_channels=self.out_channels, #make_divisible(scale * cls_ch_squeeze),
kernel_size=1,
stride=1,
padding=0,
groups=1,
if_act=True,
act='hardswish',
name=conv_name)
self.pool = nn.MaxPool2D(kernel_size=2, stride=2, padding=0)
def forward(self, x):
x = self.pool(x)
B, C, H, W = x.shape
if H != 1 :
pool2 = nn.MaxPool2D(kernel_size=2, stride=2, padding=0)
x = pool2(x)
x = self.conv1(x)
# C = 240
# H = 1
# W = 80
assert H == 1
conv_out = paddle.reshape(x=x, shape=[-1, self.out_channels, self.patch])
conv_out = conv_out.transpose([0, 2, 1])
# (NTC)(batch, width, channels)
out = conv_out
return out,H*W
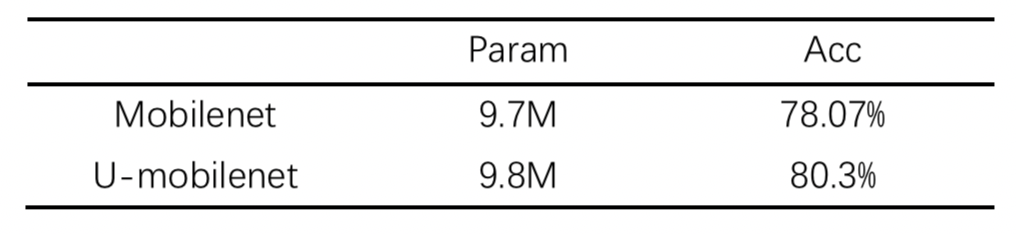
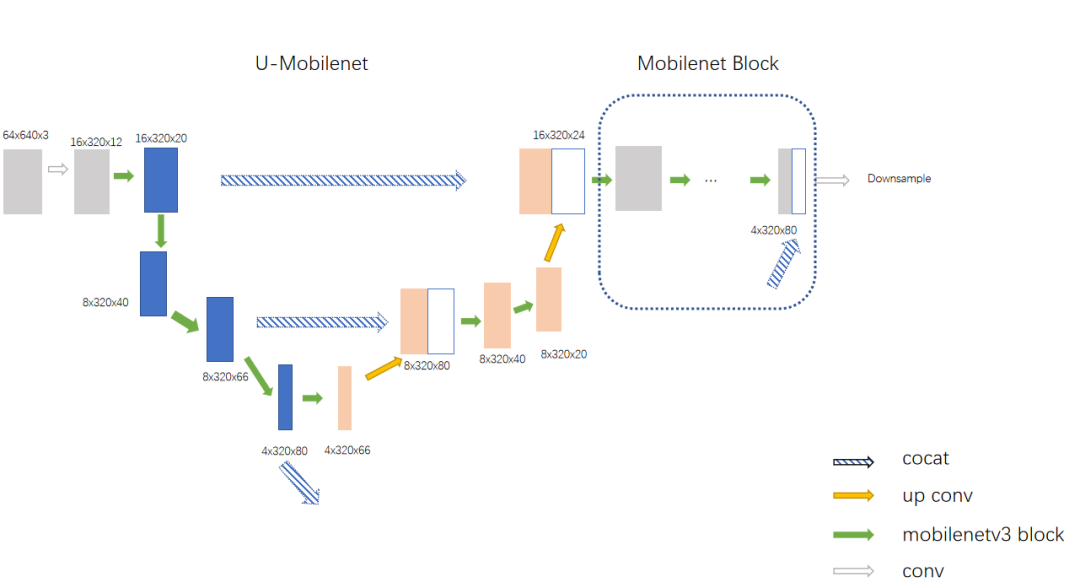
4.Umobilenet设计
数据增强方面,我们增加了mixup和cutout方法,以及SRN的尺寸resize;
参数调整方面,我们使用了64*640尺寸,并将max_len调整到35;
数据增强方面,实验证明有1%左右的稳定提升,在不同尺寸上收益并不一致。
总结与完善方向
对PaddleOCR的想法