手势是人类表达信息的重要途径之一,通过手势识别,我们可以获得表达者所要表达信息(例如对方竖起大拇指,表达了对方的表扬之意)。本项目将基于PaddleVideo来训练一个手势识别模型,利用模型对七种手势进行识别,分别是点击、放大、向下滑动、向上滑动、缩小、旋转以及抓取。
什么是PaddleVideo?
PaddleVideo是飞桨官方出品的视频模型开发套件,旨在帮助开发者更好的进行视频领域的学术研究和产业实践。可以简单的将其理解成一套帮助开发者快速完成开发的工具,避免重复造轮子,也会获得更好的精度。
TSN
TSN全称Temporal Segment Network ,是视频分类领域非常经典的模型。其主要思想是将一整段长视频分解为K个片段,每个片段随机抽取一帧,同时将RGB图像与光流分别放入两个神经网络中提取特征。通过片段共识函数,分别融合两个不同分支的结果,最后再将两类共识融合。
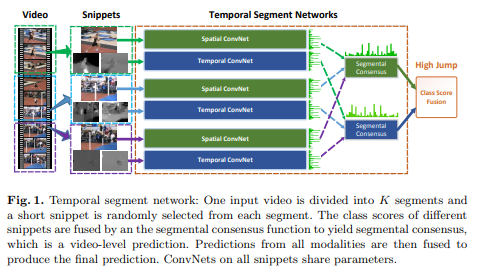
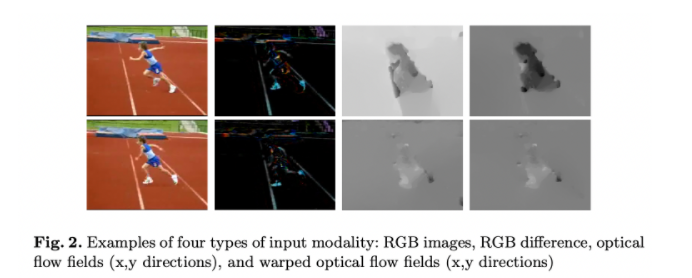
如何准备训练数据?
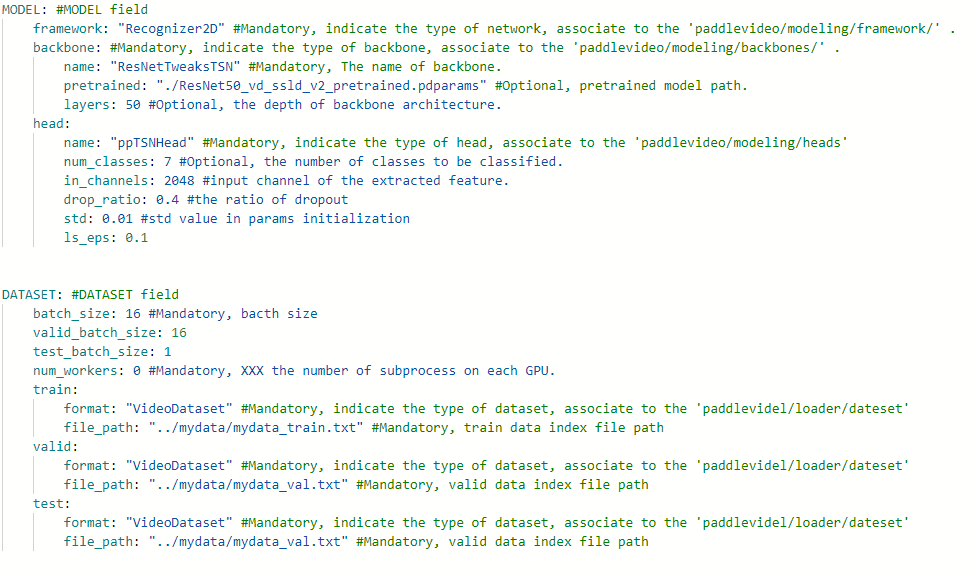
PaddleVideo PP-TSN的训练数据集使用的是由DeepMind 公布的Kinetics-400动作识别数据集。我们可以以其数据集格式作为规范进行数据准备,下面以手势识别训练数据集为例子:

基于PaddleVideo
开始训练模型
大道至简,基于PaddleVideo训练的动作分类任务时基本可以做到0代码完成训练,
!wget https://videotag.bj.bcebos.com/PaddleVideo/PretrainModel/ResNet50_vd_ssld_v2_pretrained.pdparams
!python main.py --validate -c configs/recognition/pptsn/pptsn_k400_videos.yaml
[11/22 17:00:15] epoch:[100/100] val step:0 loss: 0.09835 top1: 1.00000 top5: 1.00000 batch_cost: 0.40634 sec, reader_cost: 0.00000 sec, ips: 39.37611 instance/sec.
[11/22 17:00:16] END epoch:100 val loss_avg: 0.09812 top1_avg: 1.00000 top5_avg: 1.00000 avg_batch_cost: 0.08464 sec, avg_reader_cost: 0.00000 sec, batch_cost_sum: 1.50070 sec, avg_ips: 53.30851 instance/sec.
[11/22 17:00:16] training ppTSN finished预测及模型导出
训练完成后,即可对模型进行测试,可直接执行下列命令:
!python main.py --test -c configs/recognition/pptsn/pptsn_k400_videos.yaml -w "output/ppTSN/ppTSN_best.pdparams"

!python tools/export_model.py -c configs/recognition/pptsn/pptsn_k400_videos.yaml -p output/ppTSN/ppTSN_best.pdparams -o inference/ppTSN
!python tools/predict.py --input_file ../mydata/val/fangda40.avi \
--config configs/recognition/pptsn/pptsn_k400_videos.yaml \
--model_file inference/ppTSN/ppTSN.pdmodel \
--params_file inference/ppTSN/ppTSN.pdiparams \
--use_gpu=True \
--use_tensorrt=False
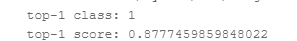

后续发展
至此,我们便完成了基于PaddleVideo训练动态手势识别的过程。项目中所选数据集为个人单独录制,所以会存在过拟合的情况,重新应用时应该收集更完善更多样的数据,这样才能达到更好的效果。希望大家可以多多尝试不同的模型,将会获得更好的效果。
关注公众号,获取更多技术内容~