你是否也曾经幻想能和未来的
自己对话,问问未来的自己过的怎么样,当初的梦想都实现了吗?
现在PaddleHub可以帮你轻松实现,先快速看下效果。
这个项目中用到了PaddleHub中的最新模型,分别用到了
语音识别、图像生成、对话系统、声音克隆、唇纹生成等能力,
通过短短十几行代码实现了和未来的自己进行对话。
那么这么厉害的项目是如何实现的呢?我们先来看下技术拆解。
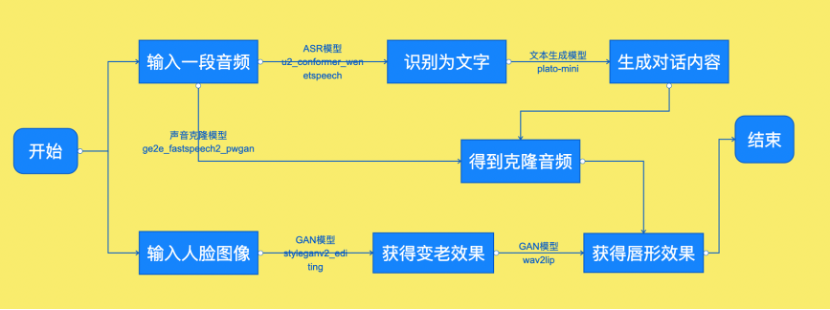
首先我们要模拟未来自己的样貌,也就是生成人脸变老的图像。我们选择了一个能够获得变老效果的模型styleganv2_editing,这个模型是PaddleGAN贡献的一个高质量人脸生成的模型,可以对年龄、性别、眼距等等十几种人脸属性进行编辑,能力十分强大。
第二步,我们要实现人机对话
,需要先将一段音频识别成文字,再根据识别出的文字,生成回应的内容。于是我们在PaddleHub的模型库中选择了来源于PaddleSpeech的效果较好的中文语音识别模型u2_conformer_wenetspeech和来源于PaddleNLP的百度自研的基于十亿级别的中文对话数据plato-mini。
接下来,我们要把回应的内容变成拥有自己音色的语音。
这就要用到来源于PaddleSpeech的最新的声音克隆模型ge2e_fastspeech2_pwgan了,我们输入对未来的寄语的音频和刚刚生成的对话文本,即可得到克隆出来的音频。到这步我们就已经实现跟自己对话了。
最后我们需要将语音和图像结合起来,让变老的我们开口说话。
这步我们用到来源于PaddleGAN的wav2lip模型,经过以下两行代码,载入模型和模型预测,即可把我们未来的样貌和对话的语音,合成一个能对的上口型的视频了。

https://aistudio.baidu.com/aistudio/projectdetail/3216625
PaddleHub
是飞桨官方推出的
预训练模型应用工具
。
入门简单,代码简洁,模型丰富,会python就能用,十行代码搞定预测,场景模型丰富实用。
不论是入门,还是想玩出各种花样的应用项目,PaddleHub都非常合适。
近期,PaddleHub新增了100多个新模型,支持声音克隆、声音分类和检测、语音合成(TTS)、语音识别(ASR)、机器翻译、同声传译、视频多目标追踪、唇纹生成等等任务,让我们一起来看看PaddleHub的效果如何。



目前,PaddleHub中的模型已经覆盖
5大领域、包含数十种任务、囊括360+模型
,都是精选效果好又实用的模型,而且所有模型,都可以在10行代码以内完成预测。
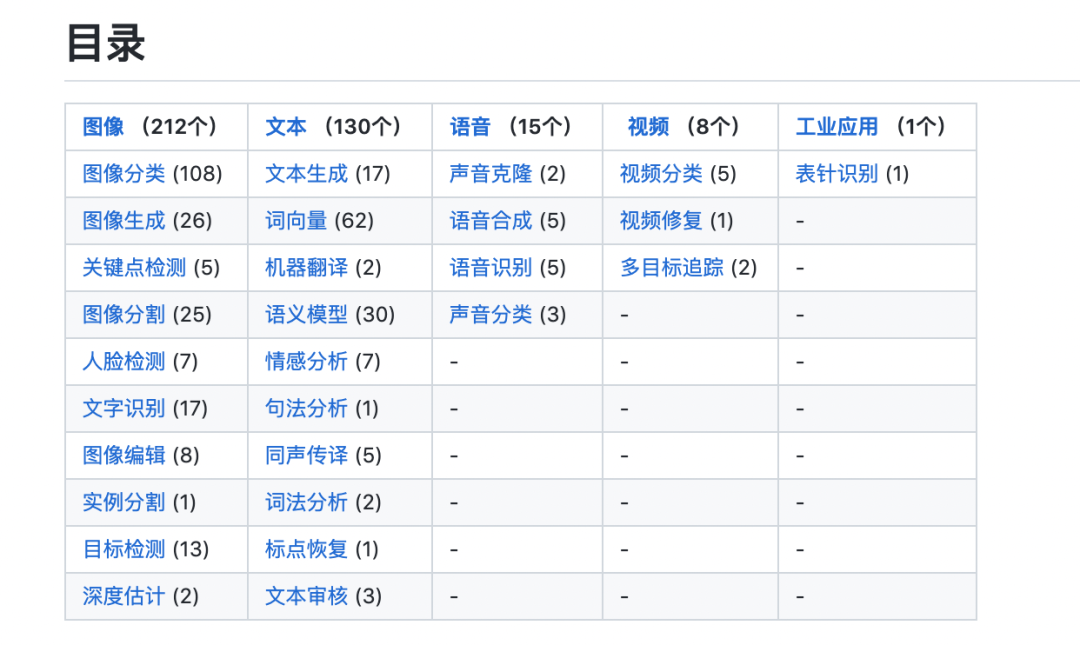
新增模型库索引页,360+模型全景概览,分类清晰明了,让你能够迅速找到心仪模型。
文档中的预测代码和API信息整洁清晰,复制即用。
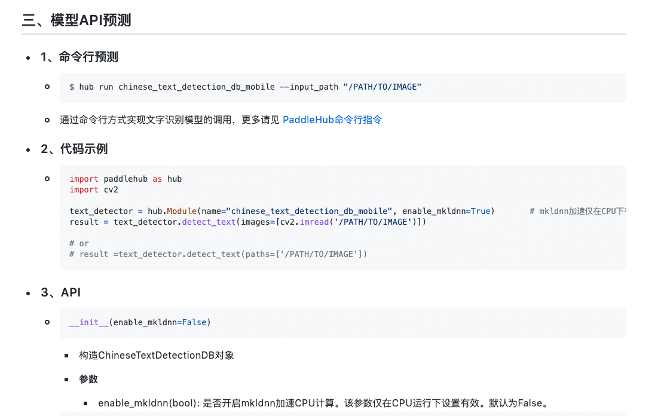
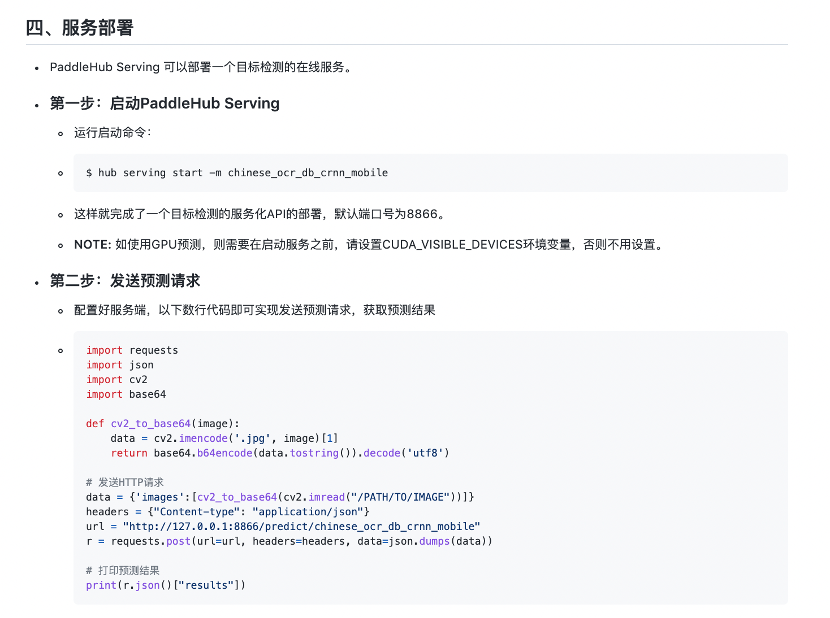
部署指令简单,教程详细,轻松部署。
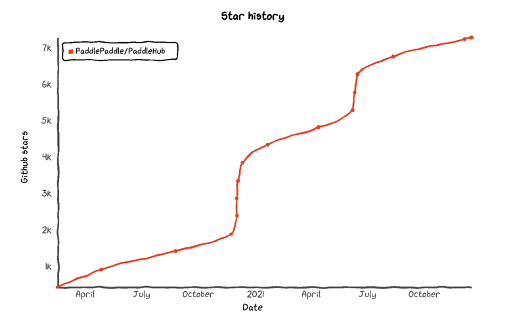
PaddleHub目前累计star数量已超过7.2K,频频登上Github Trending日榜月榜,used by 570+,还有不少小伙伴频频贡献,也是深受开发者喜爱
同时也项目目前有很多外部开发者参与建设,也欢迎大家一起参与和贡献

如果觉得效果不错,也欢迎给项目点点star加个关注。
https://github.com/PaddlePaddle/PaddleHub
另外,repo中也贴心的给出了官方微信群,有问题可以添加“飞桨小助手”回复“hub”获得进群链接,技术讨论与答疑更高效。
同时,对PaddleHub感兴趣也希望做出更多有趣事情的同学也可以回复“sig”加入PPSIG Addons-Hub小组。

https://github.com/PaddlePaddle/PaddleHub
https://gitee.com/paddlepaddle/PaddleHub
https://www.paddlepaddle.org.cn/hub
关注公众号,获取更多技术内容~

