
本文来自公众号Jina AI
ODQA全称Open Domain Question Answering,即开放域问答,是NLP领域长期研究的重要课题,在搜索引擎、智能客服、智能助手等行业应用广泛。
在实际应用中,RocketQA引入cross-attention encoder,对检索结果排序;同时利用一个包含4步的pipeline,改进训练程序。
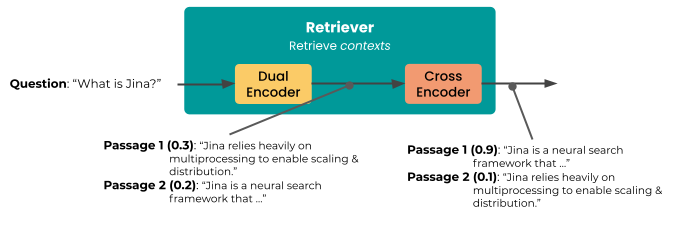
Cross Encoder:
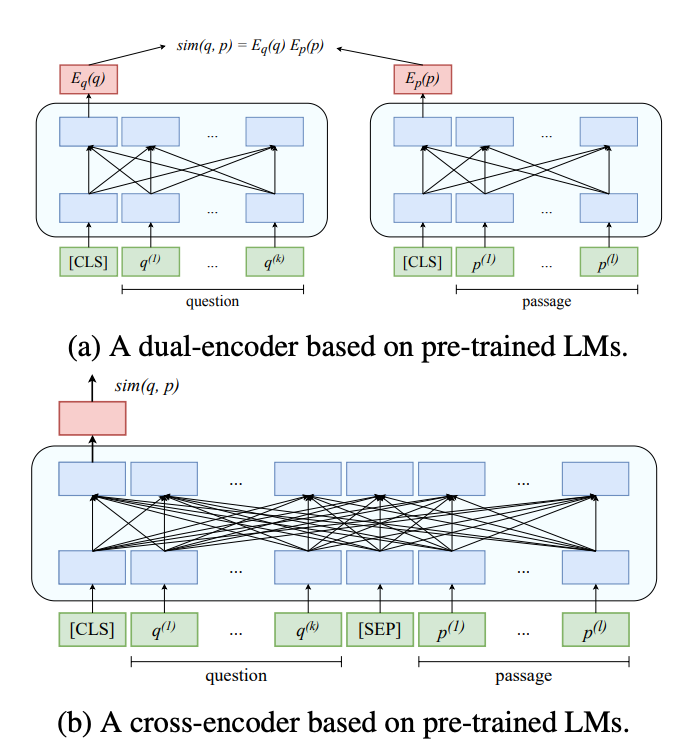
Dual Encoder 和 Cross Encoder 的原理演示
Cross-Encoder 交叉关联验证,使得结果更加准确
4 个步骤完成训练过程
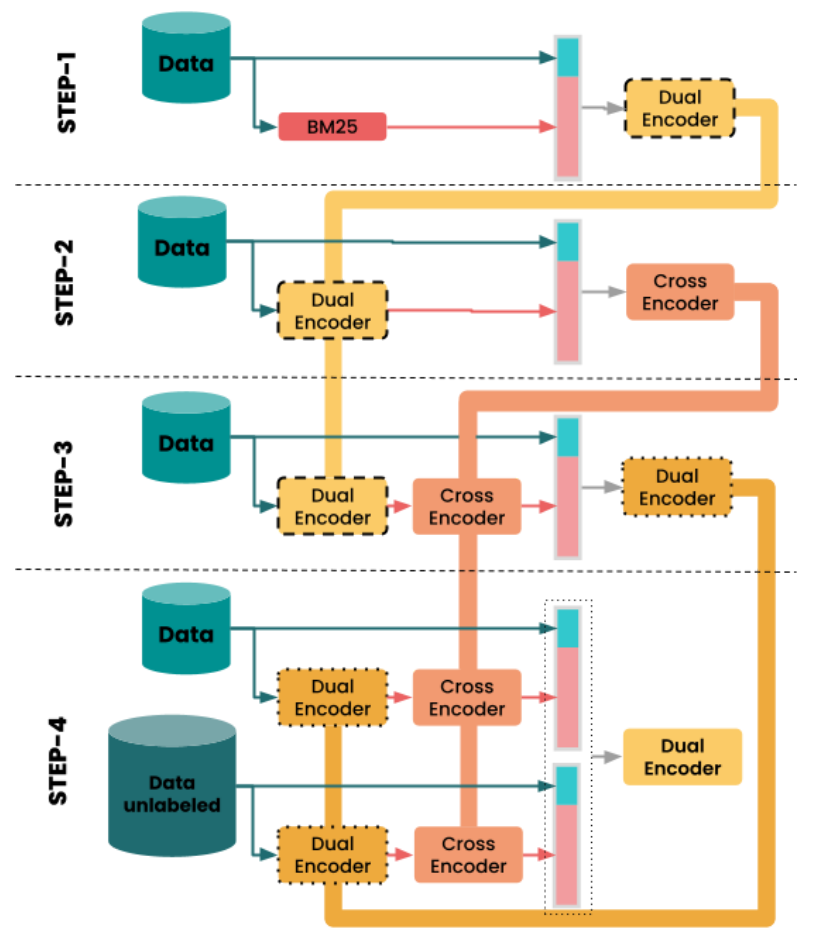
在Jina中
使用RocketQA
doc = Document(tags={'title': title, 'para': para})
f = (Flow()
.add(
uses='jinahub+docker://RocketQADualEncoder',
uses_with={'use_cuda': False})
.add(
uses='jinahub://SimpleIndexer',
uses_metas={'workspace': 'workspace_rocketqa'}))
with f:
f.post(on='/index', inputs=[doc,])
from jina import Flow
f = (Flow(use_cors=True, protocol='http', port_expose=45678)
.add(uses='jinahub+docker://RocketQADualEncoder',
uses_with={'use_cuda': False})
.add(uses='jinahub://SimpleIndexer',
uses_metas={'workspace': 'workspace_rocketqa'},
uses_with={'match_args': {'limits': 10}})
.add(uses='jinahub+docker://RocketQAReranker',
uses_with={'model': 'v1_marco_ce', 'use_cuda': False}))
总结
百度提出的RocketQA训练方法,通过对经典对偶模型进行优化训练,显著提升了模型的检索能力,为实现端到端问答迈出了重要一步。目前,RocketQA已逐步应用在百度搜索、广告等核心业务中,并将在更多场景中发挥作用。
RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering, Qu et al., NAACL 2021
https://arxiv.org/abs/2010.08191

关注公众号,获取更多技术内容~