如何用AI赋能服装设计行业,这是飞桨开发者技术专家洪力一直在思考的事。设计师构思并绘制出一件衣服后,如果可以一键生成衣服整体的效果,就可以帮助其根据成品的版型、款式等因素做出更好的设计。项目的基本思路确定以后,洪力在AI Studio平台使用飞桨框架开始实践。目前本项目可以实现服装生成,期待与更多开发者一起探讨更多可优化的地方(例如设计呈现的多样性),以下是洪力的分享。
项目背景
为了确立服装生成项目的基本设计目标,我需要寻找相关的技术。服装生成任务和其他生成任务区别之一,就是要求输出一个“干净”的衣服,不能出现花里胡哨的背景——也即要求生成器把注意力放在衣服上,而不是生成出一个完整的图片。因此在loss设计的部分,我考虑了衣服的mask蒙版部分——对于模型来说,输入的是语义分割信息,而输出的是服装图片。我在视频网站上偶然看到了SPADE的展示效果,这种“马良神笔”一般的呈现效果让我感到十分亲切,并意识到SPADE架构满足了我对模型的大概需求。但当我使用SPADE训练的时候,发现模型训练比较困难,在机缘巧合下,我又发现了一篇新的论文Semantically Multi-modal Image Synthesis。
项目实践
GET项目详细地址
https://aistudio.baidu.com/aistudio/projectdetail/3405079
问题与数据调优
一是训练集的选取问题。
二是模型训练很慢,1个batch需要耗费几十秒。
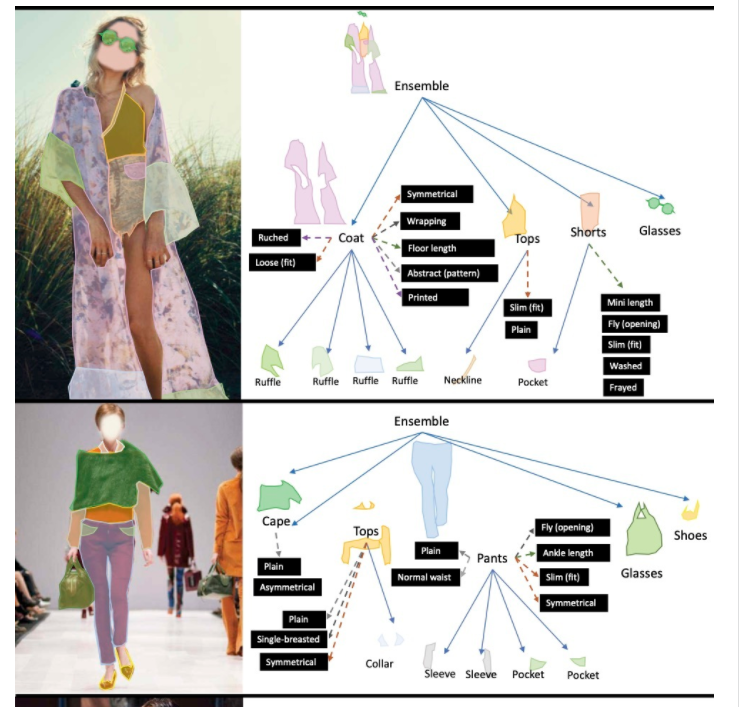
图1 FGVC数据集展示[1]
5. 由于我输入的数据格式要求是256*256,因此需要把图片和语义分割信息resize,让H和W都为256。原先数据集的图片尺寸过大,H和W值甚至上千,导致resize操作消耗了很多时间。如果有疑惑的朋友问我,为什么不用crop裁剪呢?在这里有几点原因:
首先,我设计的是服装生成项目,所以模型考虑的是衣服这个整体,要尽量少地给局部信息,防止管中窥豹,让模型有自己的“格局”。
其次,一张真实的图片中,衣服本身所占的位置并不大且位置不固定,很大概率在2500*2500上裁剪出一个256*256的区域是全黑的,无法提供信息。
最后,用crop裁剪的方式处理数据,很容易导致一些标签模型可见机率很小,比如鞋子所占比例很小,容易造成生成效果的不准确。
对模型训练及损失的思考
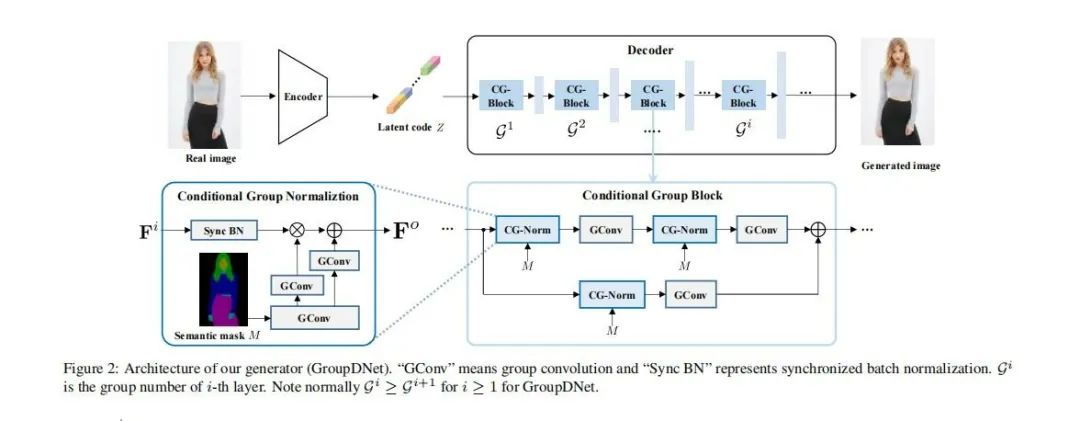
1. 我采取了GAN作为模型主体形式:生成器主体为Semantically Multi-modal Image Synthesis的模型架构;判别器使用的是Multihead Discriminator,这样可以支持判别器的特征对齐。
2. 判别器有三个任务,它需要判别Ground Truth为True,判别生成器生成出的图片为False,同时要求判别语义分割可视化为False(改进点),这是为了帮助生成器生成更加复杂真实的纹理。
3. 为了将模型中心侧重于有衣服的区域,生成器的featloss只考虑有衣服二值(0,1)mask的部分。
4. 我将spade.py中nn.conv2d(46,128)变成普通的卷积,没有使用分组卷积,理由是46不能除尽group_num = 4。
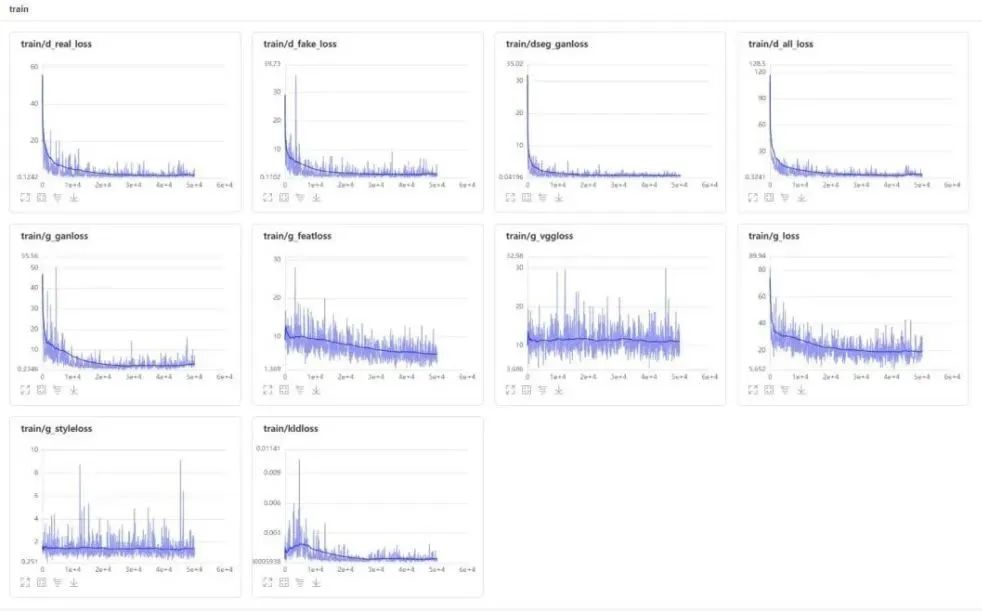
loss可视化
d_real_loss:判别器判别真实的图片为True;
d_fake_loss:判别器判别生成器生成的图片为False;
d_seg_ganloss:判别器判别语义分割可视化为False;
d_all_loss: d_real_loss + d_fake_loss + d_seg_ganloss;
g_ganloss:要求生成器生成的图片能被判别器判别为True;
g_featloss:在判别器中生成器生成的图像和真实图像特征对齐;
g_vggloss:生成器生成的图片和GT通过VGG算感知损失;
g_styleloss:生成器和GT通过Gram矩阵算风格损失;
kldloss:算一个与标准正太分布的kl散度;
g_loss:g_ganloss+g_featloss+g_vggloss+g_styleloss+kldloss。
效果展示
 图4 效果展示
图4 效果展示
回顾与思考
本项目还有很多值得改进的地方,如是否可以通过模型框架的优化,给衣服提供更细腻的特征控制,或者更好地提高所生成模型的多样性。我会继续在图像生成这个领域学习研究,期待未来带来更好的公开项目,也欢迎大家与我交流。
参考文献
[1] Semantic Image Synthesis with Spatially-Adaptive Normalization
[2] Semantically Multi-modal Image Synthesis

关注【飞桨PaddlePaddle】公众号