
近年来,随着深度学习技术的迅速发展,大模型预训练范式通过一次次刷新各种评测基线,证明了其卓越的学习与迁移能力。在这个过程中,研究者们发现通过不断扩大模型参数能持续提升深度学习模型的威力。然而,参数的指数级增长意味着模型体积增大、所需计算资源增多、耗时更长,这在业务方对线上响应效率的要求及机器资源预算等层面,都为大模型落地带来了极大的挑战。

如何在保证效果的前提下压缩模型?如何适配CPU、GPU等多硬件的加速?如何让加速工具触手可及?这是行业内亟待解决的课题。现在,PaddleNLP解答了这些难题。
PaddleNLP是基于深度学习框架飞桨的自然语言处理开发库。本次PaddleNLP 最新开源的预训练模型提供“训-压-推”全流程加速方案,不断拓展大模型性能的边界,且大幅降低了各类模型加速技术的使用门槛:
-
文心ERNIE-Tiny轻量化技术加持
的多个文心ERNIE 3.0轻量级模型刷新了中文小模型的SOTA成绩,均已开源;
-
在下游任务上对模型进行动态裁剪和量化推理,
性能加速3倍
;
-
结合高性能文本处理算子库FasterTokenizer,
性能加速7倍
;
-
提供CPU和GPU、服务器、端侧等
多种部署方案
。
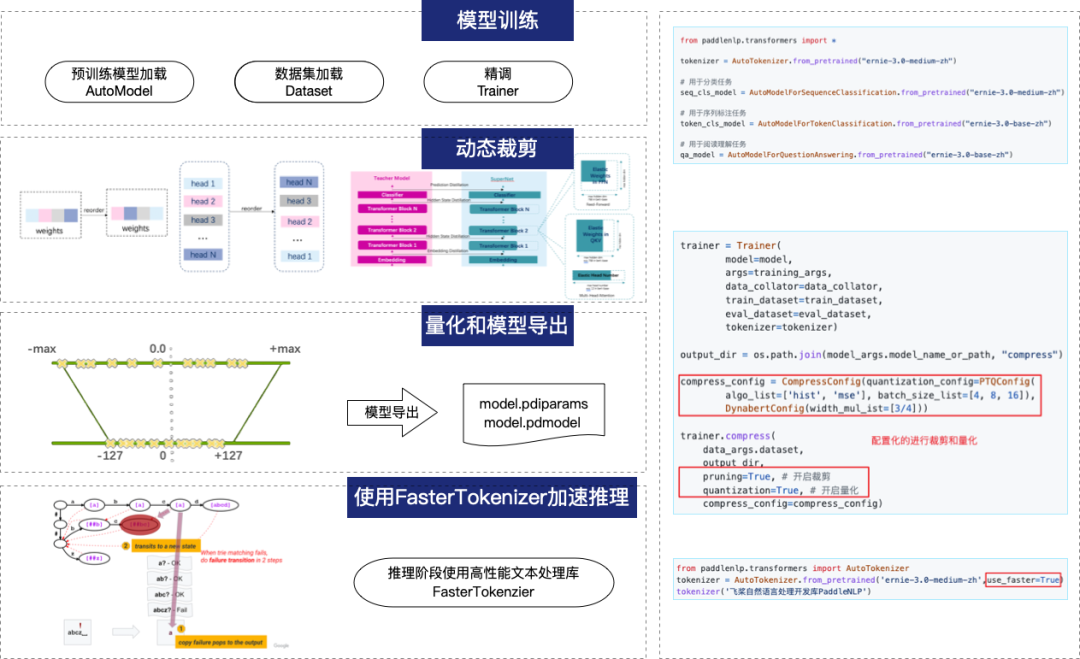
图1 PaddleNLP“训-压-推”全流程加速方案
蒸馏,通俗来说是通过将大模型(可以理解为“教师模型”)的知识传递给小模型(可以理解为“学生模型”),使得大模型的能力能够迁移到小模型上。蒸馏技术大家可能并不陌生,但是如今动辄百亿、千亿的大模型,如何有效蒸馏到小模型,是一个棘手的问题。由于教师模型与学生模型尺寸差距千倍以上,模型蒸馏难度极大,甚至有失效的风险。为此,文心ERNIE-Tiny
[1]
在线蒸馏方案引入了助教模型进行蒸馏,利用助教作为知识传递的桥梁以解决学生模型和大模型表达空间相距过大的问题,从而促进蒸馏效率的提升。
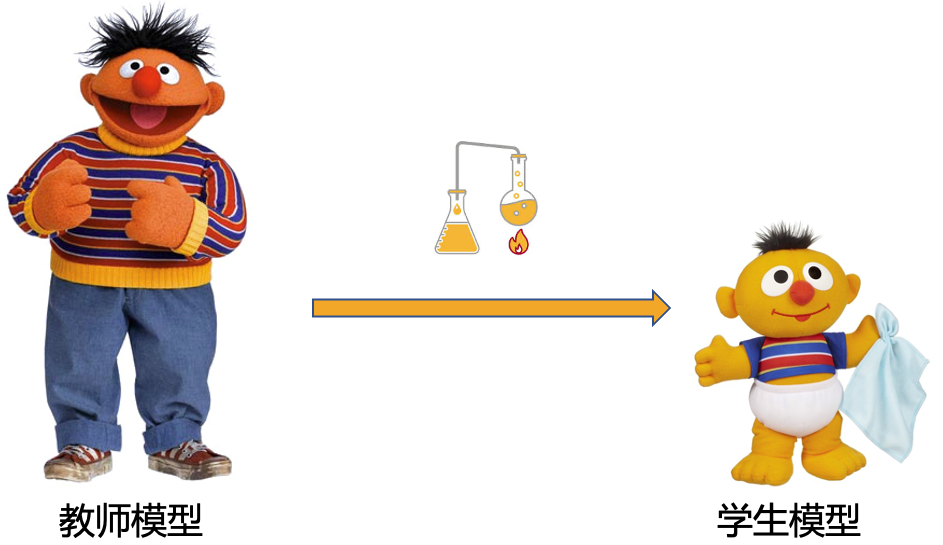
图2 模型蒸馏示意
文心ERNIE-Tiny在线蒸馏技术将教师模型的知识信号传递给若干个学生模型同时训练,从而在蒸馏阶段一次性产出4个不同尺寸的学生模型。此外,本次还开源了12L768H的文心ERNIE 3.0-Base,方便不同性能需求的应用场景使用。
-
文心ERNIE 3.0-Base (12-layer, 768-hidden, 12-heads)
-
文心ERNIE 3.0-Medium (6-layer, 768-hidden, 12-heads)
-
文心ERNIE 3.0-Mini (6-layer, 384-hidden, 12-heads)
-
文心ERNIE 3.0-Micro (4-layer, 384-hidden, 12-heads)
-
文心ERNIE 3.0-Nano (4-layer, 312-hidden, 12-heads)
文心ERNIE-Tiny在线蒸馏方案效果显著,
模型参数压缩率可达99.98%,压缩版模型仅保留0.02%参数规模就能与原有模型效果相当
,刷新了中文小模型的SOTA成绩。具体对比数据见如下模型“精度-时延”图,横坐标表示性能(Latency,单位毫秒,在长文本分类数据集IFLYTEK上测试,单个样本的推理时长),纵坐标表示模型在CLUE10个任务上的平均精度。图中模型名称下方标注了模型的参数量。
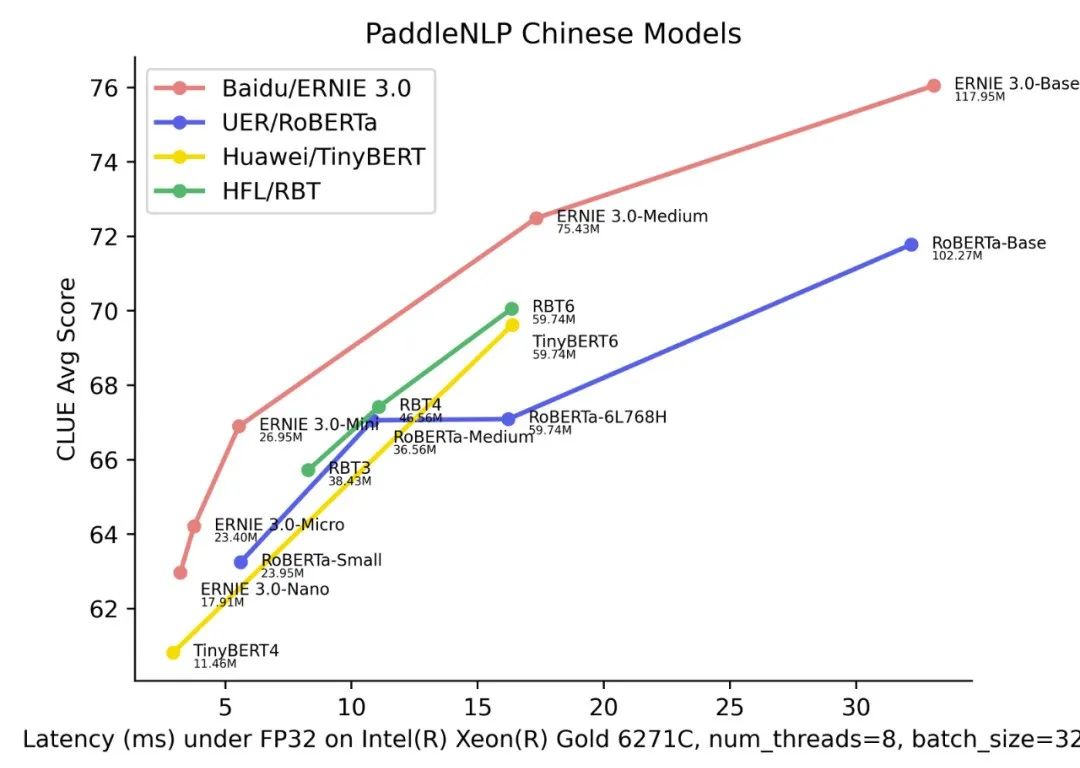
图3 CPU下文心ERNIE 3.0轻量级模型时延与效果图
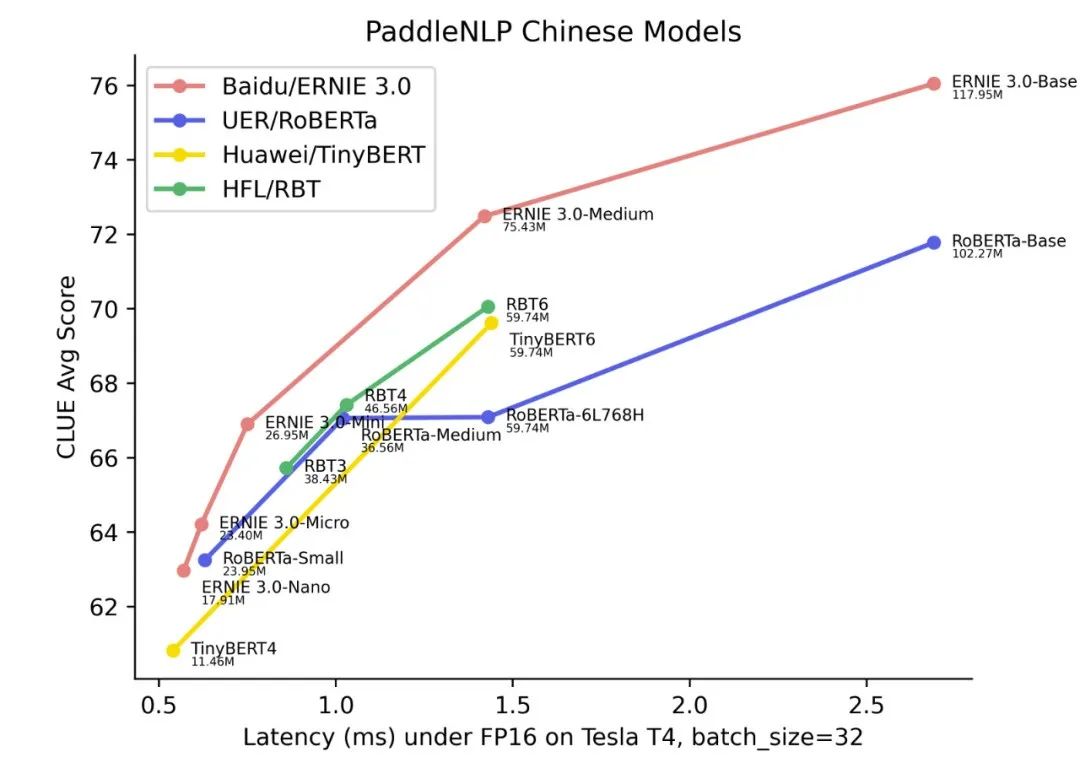
图4 GPU下文心ERNIE 3.0轻量级模型时延与效果图
图中,越偏左上方的模型越优秀,可以看到文心ERNIE 3.0轻量级模型在同等规模的开源模型中,综合实力领先其他同类型轻量级模型,这波开源厉害了!
与RoBERTa-Base相比,12L768H的文心ERNIE 3.0-Base平均精度绝对提升了1.9个点,比同等规模的BERT-Base-Chinese提升3.5个点;6L768H的文心ERNIE 3.0-Medium相比12L768H的UER/Chinese-RoBERTa,在节省一倍运算时间基础上,获得比两倍大的RoBERTa更好的效果
;另外值得一提的是,这些小模型能够直接部署在CPU上,可以称得上是CPU开发者的“希望之光”。
在PaddleNLP中,可一键加载以上模型。

图5 代码展示
此外,PaddleNLP还提供了CLUE Benchmark的一键评测脚本,并提供了大量中文预训练模型在CLUE上的效果。PaddleNLP接入了Grid Search策略,支持在超参列表范围内自动搜索超参,保留最佳结果和对应的超参数,方便一键复现模型效果,且打通了CLUE各个任务“数据处理-训练-预测-结果提交”的流程,方便用户快速提交CLUE榜单[2]。
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-3.0
上一节介绍了任务无关的模型蒸馏技术,如果想要进一步提升模型性能,还可以在下游任务上对模型Fine-tune后,通过裁剪、量化等手段,获得更小、更快的模型。
结合飞桨模型压缩工具PaddleSlim,PaddleNLP发布了裁剪、量化级联压缩方案。基于PaddleNLP Trainer API的模型压缩API,可大幅降低开发成本。压缩API支持对文心ERNIE、BERT等Transformers类下游任务微调模型进行裁剪和量化。只需要简单地调用compress()即可一键启动裁剪量化流程,并自动保存压缩后的模型。

图6 PaddleNLP模型裁剪、量化使用示例
速度领先的文本处理库
FasterTokenizer
文心ERNIE-Tiny在线蒸馏技术加持的文心ERNIE 3.0轻量级模型本身已经“又快又准”,再加上裁剪、量化策略以及飞桨高性能文本处理算子库FasterTokenizer就能实现更强大的加速效果,如下图所示:
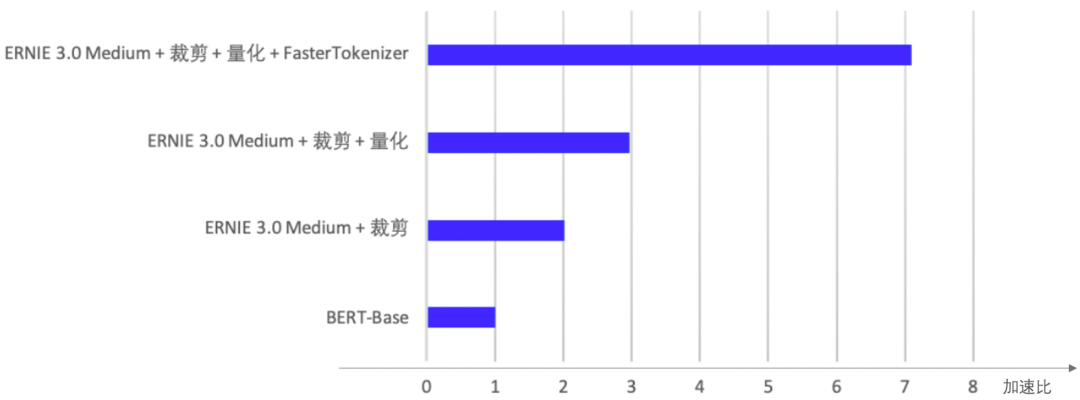
图7 GPU下多种性能优化策略的加速比展示
如图,FasterTokenizer在文心ERNIE 3.0轻量级模型裁剪、量化基础上性能加速达到7倍。仔细研读一番代码,我们会发现,PaddleNLP已将Google于去年底发布的LinMaxMatch[3]算法,集成至FasterTokenizer。该算法通过结合Aho-Corasick字符串匹配算法,保证字符串在失配时可以将遍历过的字符保存为若干个tokens,并快速跳至失配节点,避免从头匹配,计算复杂度MaxMatch的O(N2) 优化至O(N)。
与Hugging Face的中文切词效率进行对比,PaddleNLP FasterTokenizer速度显著领先。例如在iflytek数据集(平均长度289)上,FasterTokenizer比Hugging Face Tokenizers加速3倍以上
。
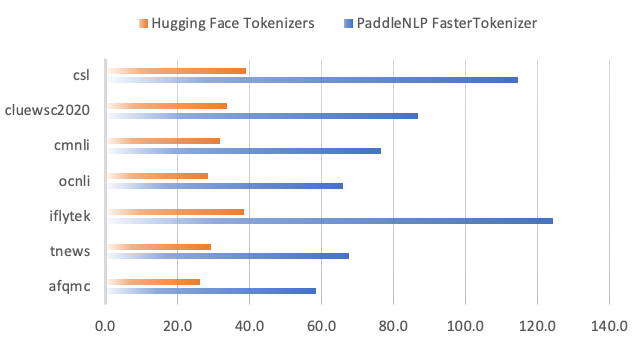
图8 同类产品中文切词效率对比
为了降低开发门槛,把“酷炫”的底层技术大范围普及,PaddleNLP做出了出色的设计。在调用AutoTokenizer时,只需进行参数配置,即可开启 FasterTokenizer,方便大家使用。

图9 FasterTokenizer调用方法
飞桨提供了服务端、移动端、网页前端等丰富的部署工具。PaddleNLP本次围绕文心ERNIE 3.0发布了一系列高性能部署方案,且通过Paddle2ONNX转换工具进一步拓宽了飞桨模型的部署通路,适用于多场景的部署需求。用户可参照官方提供的完整示例,快速部署上线,包括Python服务端部署、Triton Inference Server服务化部署、Paddle Serving服务化部署、ONNXRuntime部署等多个示例。
 图10 飞桨部署方案说明
图10 飞桨部署方案说明
-
某医疗行业用户使用通用信息抽取技术UIE,结合文心ERNIE 3.0-Medium提升了效果和性能:
A同学使用UIE对医疗领域的病历文本进行实体抽取和关系抽取,在其特定数据集上,使用6L768H的文心ERNIE 3.0-Medium获得与12L768H模型相当的效果,速度提升一倍。
B同学部门没有GPU资源,一直都在使用RNN模型进行文档自动归档工作。替换成文心ERNIE 3.0-Mini模型后,顺利部署到CPU机器上。使用PaddleNLP,仅用一天时间就完成了模型的部署上线。
-
某互联网行业用户使用文心ERNIE 3.0-Base实现效果、性能双提升:
C同学在公司文本分类和阅读理解任务上,分别使用了文心ERNIE 1.0和文心ERNIE-Gram模型,之后替换成文心ERNIE 3.0-Base模型,再配套PaddleNLP中的裁剪、量化策略,效果和性能双双提升。
PaddleNLP还提供了一系列围绕文心ERNIE 3.0的Notebook交互式教程,方便大家快速上手实践,可进入官方地址自取。

图11 ERNIE 3.0应用示例
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-3.0

图12 PaddleNLP学习大礼包
PaddleNLP:不忘初心
感谢广大开发者的支持
PaddleNLP一路陪伴着广大开发者的成长。今年5月,PaddleNLP开源的通用信息抽取技术UIE颇受好评,被应用上线到金融、医疗、法律、互联网、泛工业等各行各业。PaddleNLP团队针对模型轻量化、部署便捷化等社区高频需求不断迭代产品功能,希望能够持续给大家带来惊喜。社区开发者们也始终伴随PaddleNLP的成长,给予我们真诚的反馈,并积极投入到PaddleNLP的项目建设中,感谢大家,我们一起在路上!
-
PaddleNLP频频登上GitHub Trending榜单,广受国内外开发者欢迎;
-
社群氛围活跃,信息抽取UIE技术发布一个月后热度不减,频获好评;
-
版本持续更新,100多位开发者贡献,入选《2021中国开源年度报告》最活跃产品榜单。
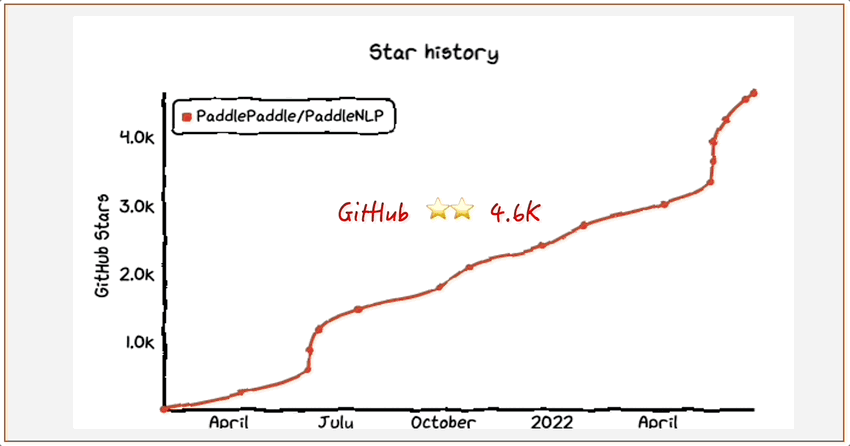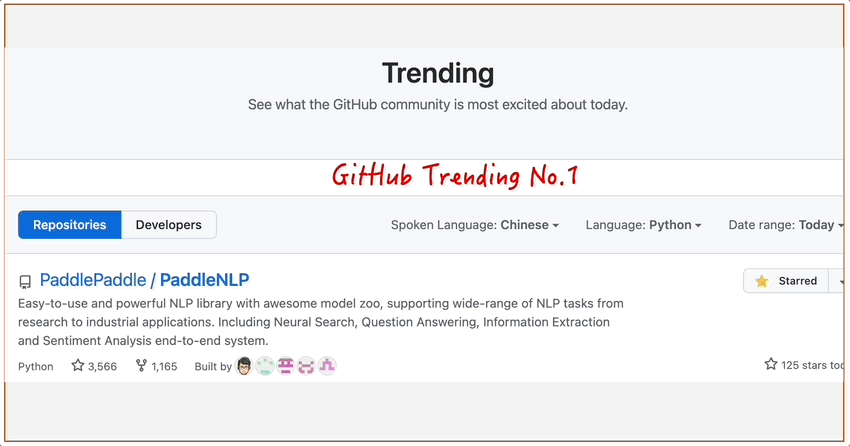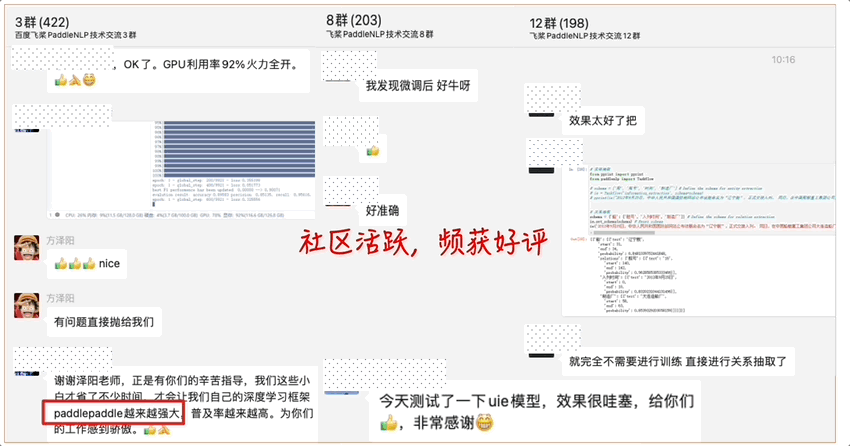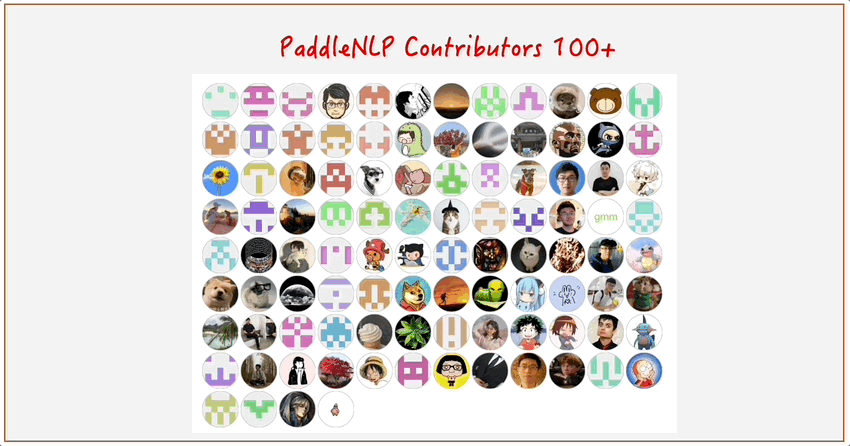
图13 PaddleNLP影响力动图
https://www.paddlepaddle.org.cn
GitHub:
https://github.com/PaddlePaddle/PaddleNLP
Gitee:
https://gitee.com/paddlepaddle/PaddleNLP
[1] ERNIE-Tiny: A Progressive Distillation Framework for Pretrained Transformer Compression.
见
https://arxiv.org/abs/2106.02241
[2] https://www.cluebenchmarks.com/
[3] Fast WordPiece Tokenization.
见
https://arxiv.org/abs/2012.15524
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
