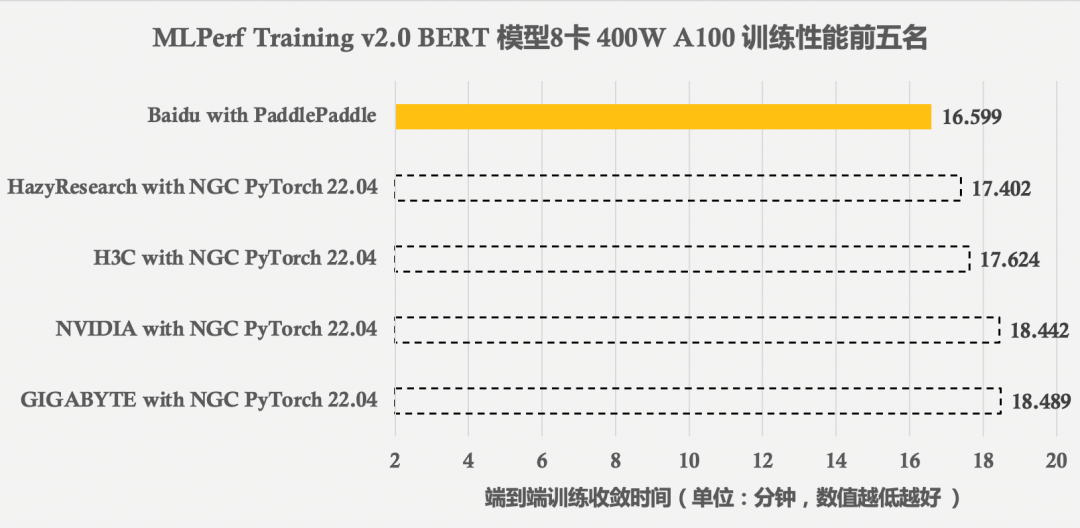
图1 MLPerf Training v2.0 BERT模型效能前五名训练成果
数据读取和模型训练的负载均衡
变长序列输入模型的计算加速
针对变长序列输入模型大多采用的padding填充对齐方式带来的冗余计算问题,提供对变长输入和对应模型结构的高效支持,让GPU算力资源专注于有效计算,尤其是对Transformer类模型计算效率提升明显。
高性能算子库和融合优化技术
针对框架基础性能优化的极致需求,研发了高性能算子库PHI,充分优化GPU内核实现,提升算子内部计算的并行度,并通过算子融合降低仿存开销,发挥GPU的极限性能。
高加速比的混合并行训练策略
全流程异步调度
针对模型训练过程各环节存在的同步频率高、时间重叠度低等问题,设计异步调度机制,保证模型收敛的同时去除大部分同步操作,实现数据处理、训练和集合通信等各环节近乎全异步调度,提升端到端极致性能。
助力大模型
技术创新和产业落地
百度一直重视大模型的技术研发,并致力于推动大模型的产业落地。大模型训练需要深度学习框架在高性能分布式训练方面提供强有力支撑。
结语
飞桨在MLPerf Training v2.0榜单中获得了BERT模型训练性能世界第一的瞩目成绩。这不仅得益于飞桨框架在性能优化领域的长期耕耘,更离不开硬件生态的助力。近年来,飞桨的技术实力深受广大硬件厂商认可,合作日趋紧密,软硬一体协同发展,生态共创硕果累累。前不久(5月26日),NVIDIA与飞桨合作推出的NGC-Paddle正式上线。同时在本次MLPerf榜单中,Graphcore也通过使用飞桨框架取得了优异成绩。未来,飞桨将继续打造性能优势,在软硬协同性能优化和大规模分布式训练方面持续技术创新,为广大用户提供更加便捷、易用、性能优异的深度学习框架。
MLPerf介绍
MLPerf是由AI领域世界知名的学术研究者和产业专家发起的人工智能领域基准测试标杆。MLPerf旨在提供一个公平、实用的基准测试平台,展示业界领先的AI软硬件系统的最佳性能,其测试结果已获得AI领域的普遍认可。世界上几乎所有主流的硬件生产商和软件服务提供商都会参考MLPerf发布的结果构建自己的基准测试系统,以测试其开发的新的AI加速芯片和深度学习框架在MLPerf模型上的性能表现。
直播预告


关注【飞桨PaddlePaddle】公众号
获取更多技术内容~