随着线下零售与互联网电商的快速发展,日益复杂的开放场景对商品识别搜索技术提出新的挑战。百度视觉技术团队发布商品图文预训练大模型文心VIMER-UMS,一举刷新4项国际权威检索任务纪录。
统一视觉与多源图文表征的商品
多模态预训练模型文心VIMER-UMS
现有多模态图文预训练方法主要面向图文跨模态搜索、多模态理解与生成任务,侧重对图文模态特征的关系表征,对单模态视觉下游任务效果支持不足。以OpenAI CLIP、Google Align为代表的大规模图文预训练方法依赖大量训练资源及亿级大数据,高昂成本制约多模态大模型的规模化应用。
此外,现有多模态图文预训练方案的训练数据主要为图文对数据,但真实场景中的多模态关联数据不仅限于简单的图文对,更有多维度的信息来源,即多源信息。以商品搜索场景为例,多源信息就包括文本模态(搜索输入、场景文字、文本标题、类目标签)、视觉模态(商品图、同款标签)的多维多模态信息。多源蕴含丰富的语义关联,具有极大的挖掘利用潜力与应用价值。但是,多源商品信息通常存在模态信息缺失的问题,是多源信息模态建模应用面临的重要挑战。
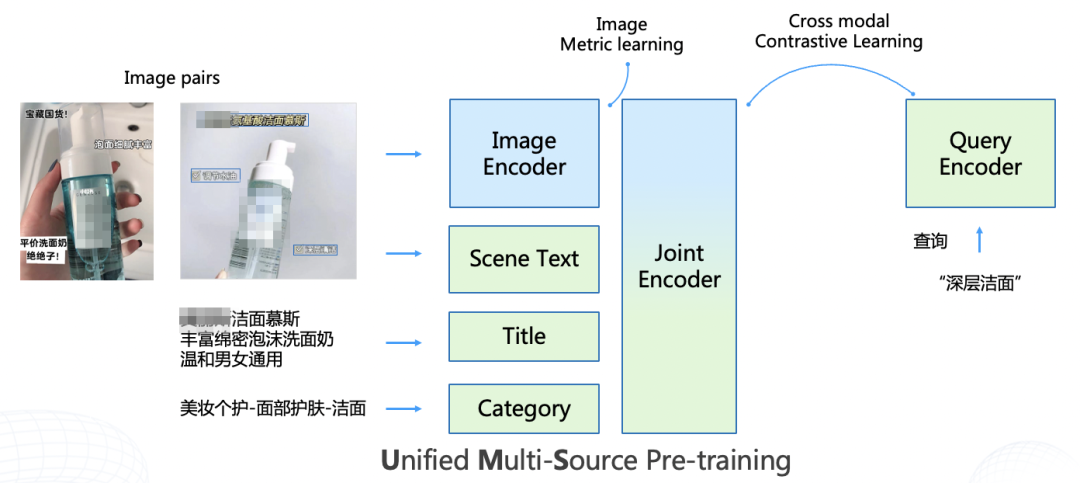
针对以上问题,百度面向商品搜索场景,提出了多源信息统一建模的商品图文表征预训练模型文心VIMER-UMS,旨在统一视觉模态、图文多模态搜索表征任务,克服多源信息场景下模态信息残缺的问题,同时提升视觉、多模态搜索任务效果。
统一的商品视觉与图文表征
支持丰富的下游检索任务
文心VIMER-UMS基于端到端Transformer训练方式,通过视觉编码、文本编码、融合编码、搜索查询编码,提供多源商品信息的统一表达结构。由于现有多模态预训练方法依靠语言作为弱监督关联信号,视觉表征能力存在被弱化现象,往往需要相比视觉有标注数据百倍以上的图文样本才能达到接近的训练效果。为了解决该问题,文心VIMER-UMS通过建立视觉与多源图文对比多任务预训练,实现视觉特征与图文多模态特征的统一增强表征。
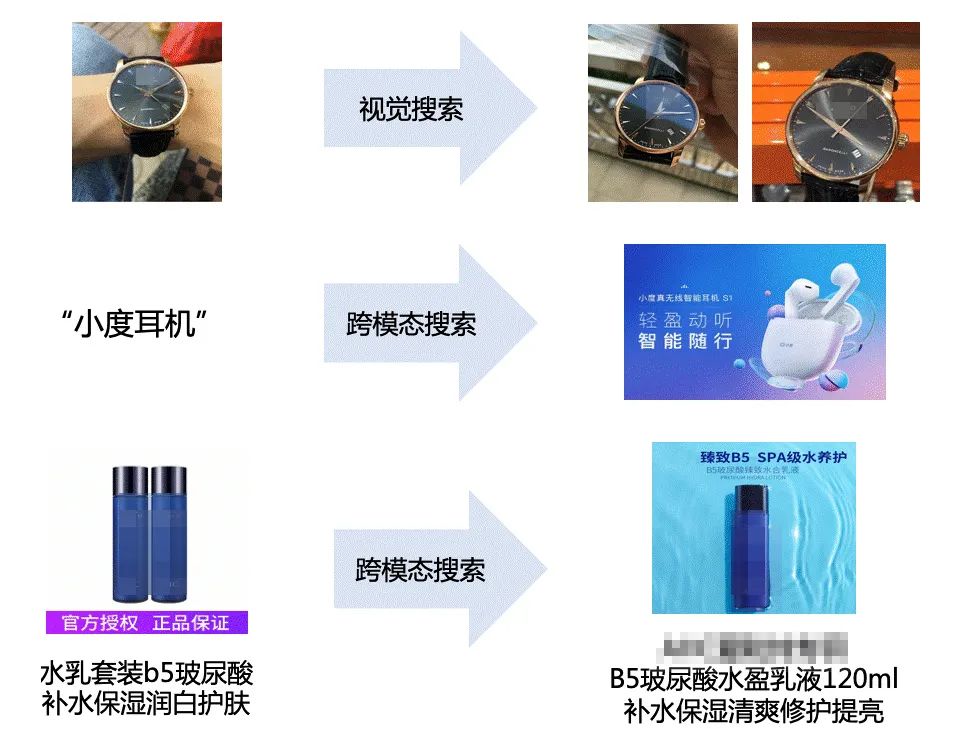
针对实际业务应用,基于文心VIMER-UMS商品图文表征预训练模型,使用少量标注或无标注数据,即可高效实现下游商品视觉搜索、跨模态/多模态搜索能力:
下游商品视觉搜索、跨模态/多模态搜索任务
文心VIMER-UMS
效果全面领先
基于多源信息统一的商品视觉与图文表征建模文心VIMER-UMS,实现4个商品下游视觉、跨模态检索任务取得业界领先效果。
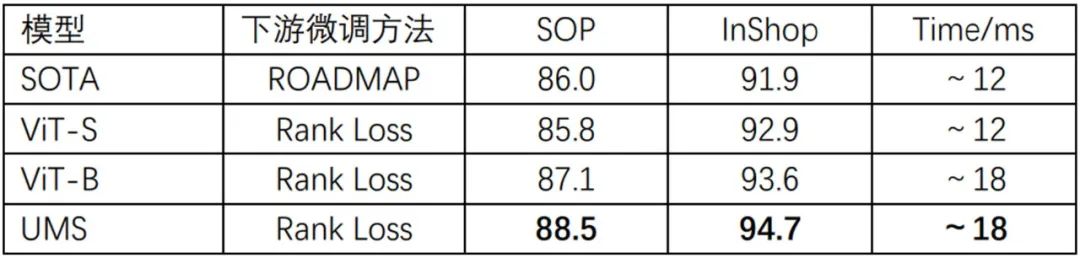
商品视觉检索任务
在商品SOP、服饰InShop的视觉检索下游任务中,文心VIMER-UMS模型Top1检索效果显著优于已有方法,如下表所示。
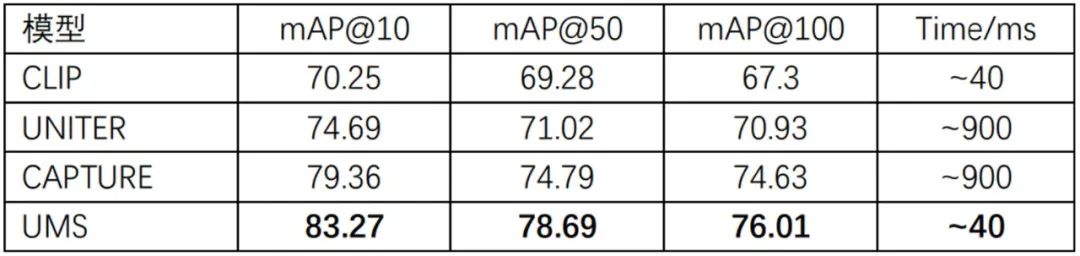
商品多模态检索任务
商品多模态检索Product1M任务中,mAP指标刷新业界最佳效果,如下表所示。
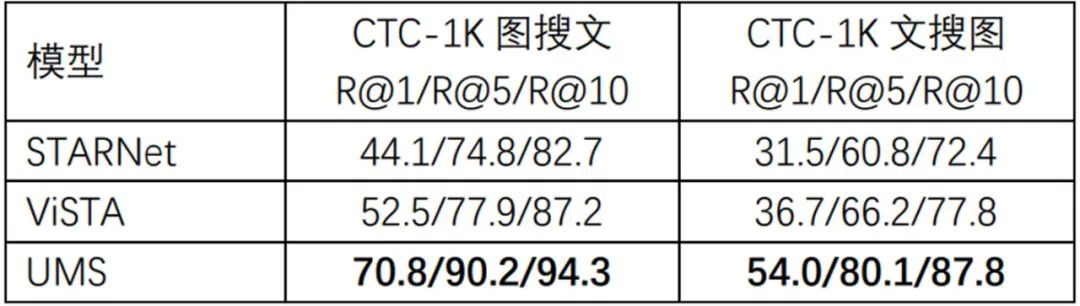
有场景文字图文跨模态任务
COCO-CTC数据集图搜文、文搜图任务大幅刷新SOTA效果,如下表所示。
文心VIMER-UMS强力支持
百度数字化访销解决方案抢占零售数字化高地
在快速消费品行业中,线下销售渠道依然是快消品销售的主要方式。然而品牌商很难完全掌握数百万线下终端门店的产品陈列、销售和营销情况,难以及时获取产品动销信息,并针对快速变化的消费者需求实现及时响应。因此品牌商需要借助数字化来加强渠道管控,实现深度分销,覆盖和掌控终端,拉动销售,提高精细化运营和营销能力。
由于快消品更新频率高、商品陈列场景复杂多样、店内环境昏暗杂乱、访销数据容易伪造,如何准确识别商品SKU和保障数据真实性是数字化访销的关键问题。百度依托文心VIMER-UMS商品预训练作为基础模型,显著增强下游商品识别效果,帮助品牌商高效构建商品SKU识别、访销窜拍识别能力,实现零售行业头部客户的快速落地应用。某头部快消客户场景实现错误率降低40%,帮助该客户大幅提升数字化访销效率,降低日常巡店成本,拉动门店收入增长。
结语
统一视觉与多源图文表征的商品多模态预训练模型文心VIMER-UMS支持电商搜索、商品识别、智能推荐、线下零售数字化多个场景落地应用,使用少量标注或无标注数据,高效实现商品视觉搜索、跨模态、多模态搜索能力,为零售企业数字化转型助力,为用户线上购物带来便捷。
目前文心VIMER-UMS模型已经在飞桨开放。想了解更多文心VIMER-UMS技术细节和快消线下数字化访销解决方案,可通过以下地址访问。
文心VIMER-UMS多模态检索方法ViSTA,论文地址:
文心VIMER-UMS开放模型地址,点击阅读原文即可访问:
快消线下数字化访销解决方案:
https://ai.baidu.com/solution/fmcg