图神经网络(Graph Neural Network,GNN)是近年来出现的一种利用深度学习直接对图结构数据进行学习的方法,通过在图中的节点和边上制定聚合的策略,GNN能够学习到图结构数据中节点以及边内在规律和更加深层次的语义特征。图神经网络不仅成为学术界研究热点,而且已经在工业界广泛应用落地。特别在搜索、推荐、地图等领域,采用大规模分布式图引擎对异构图结构进行建模,已经成为技术发展的新趋势。
目前,分布式图学习框架通常在CPU集群上部署分布式图服务以及参数服务器,来支持大规模图结构的存储以及特征的更新。然而,基于CPU算力的图学习框架在建设成本、训练速度、稳定性以及复杂算法支持等方面都存在不足。
因此,百度飞桨推出了能够同时支持复杂图学习算法+超大图+超大离散模型的GPU大规模图学习训练框架PGLBox。该框架结合了百度移动生态模型团队在大规模业务技术的深耕,凝聚飞桨图学习PGL丰富的算法能力与应用经验,并依托飞桨深度学习平台通用的训练框架能力与灵活组网能力,不仅继承了飞桨前期开源的Graph4Rec[1]超大规模、灵活易用和适用性广的优点[2],更是在训练性能、图算法能力支持方面获得了显著提升。
 超高性能的GPU分布式图学习训练框架
超高性能的GPU分布式图学习训练框架
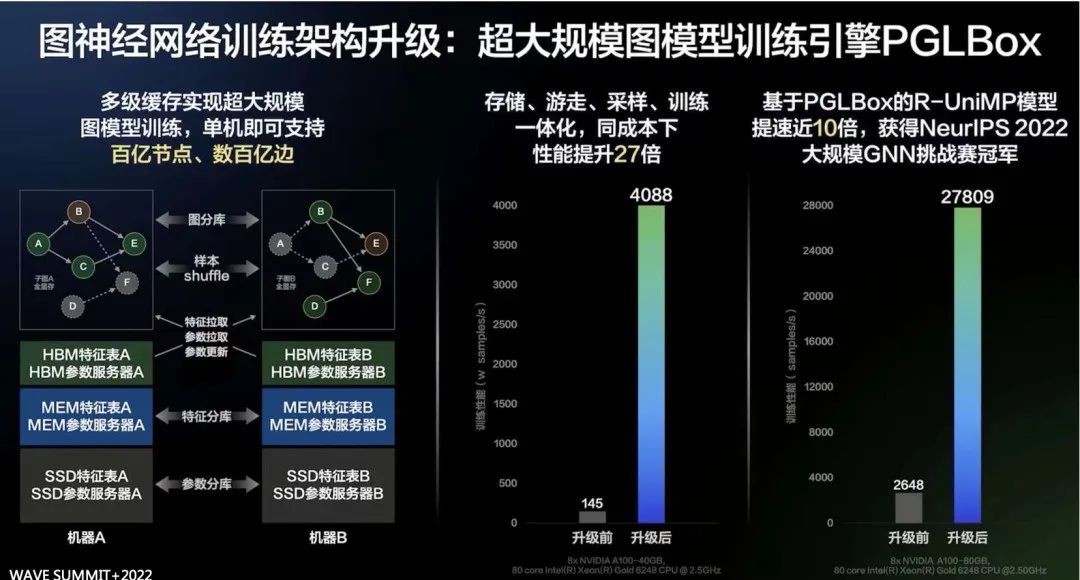
随着图数据规模的不断增大,基于CPU分布式的解决方案需要大量的跨机器通讯,导致训练速度慢且稳定性差。为了解决这个问题,PGLBox将图存储、游走、采样、训练全流程GPU化,并实现流水线架构,极致提升异构硬件效率,大幅提升了图学习算法的训练速度。同时,针对NVLink拓扑、网卡拓扑非全互联问题,实现智能化中转通信,进一步提升训练能力。相比基于MPI CPU分布式的传统方案,训练速度提升27倍。PGLBox实现了多级存储体系,对图、节点属性和图模型进行差异化存储,即图结构全显存、节点属性二级存储和图模型三级存储,将图规模提升了一个数量级。为了平衡磁盘、内存、显存之间的占用,PGLBox实现了均衡训练,对Pass大小平滑处理,削峰填谷,降低峰值显存,使得在单机情况下,可支持的图规模得到大幅提升。
 全面升级预置的图表示学习算法
全面升级预置的图表示学习算法
图节点的属性是多种多样的,可以是文本、图像,也可以是用户画像、地理位置等,如何更好地建模节点特征是图表示学习的一个重要挑战。随着预训练模型席卷NLP、CV等领域,预训练Transformer是节点属性建模不可或缺的一部分。而复杂结构的Transformer等预训练模型的引入所增加的大量计算量,是以往CPU分布式图表示学习框架不可接受的。得益于PGLBox同时兼备GPU的运算能力和大规模图的支持,让我们能够同时实现大规模预训练模型+大规模图结构信息+大规模离散特征的端对端统一建模。在大规模图数据,通过三级存储加载之后,我们可以通过加载不同的大规模预训练模型(例如ERNIE语言大模型、ERNIE-ViL跨模态大模型等)来建模更丰富的节点信息。对于大规模离散特征如用户ID、商品ID等,我们可以同时利用到PGLBox提供的GPU参数服务器能力来建模。最后通过图信息汇聚的Graph Transformer图神经网络模块完成信息聚合,得到图的最终表示,并配合下游任务实现跨模态异构图端对端优化。
基于PGLBox的GNN技术获得了NeurIPS 2022大规模GNN挑战赛冠军[3],同时入选了百度Create2022十大黑科技,并在WAVE SUMMIT+2022上作为飞桨2.4版本最重要的框架新特性之一发布。凭借其超高性能、超大规模、超强图学习算法、灵活易用等特性,PGLBox在百度内大量业务场景实现广泛应用并取得显著业务收益,如百度推荐系统、百度APP、百度搜索、百度网盘、小度平台等。
看到这里相信大家已经迫不及待想要开箱试用了吧!PGLBox已全面开源,欢迎大家试用或转发推荐,详细代码库链接请戳下方链接或者点击阅读原文!
https://github.com/PaddlePaddle/PGL/tree/main/apps/PGLBox
更多交流欢迎通过邮件pglbox@baidu.com与我们联系,感谢支持!
[1]https://arxiv.org/abs/2112.01035
[3]https://ogb.stanford.edu/neurips2022/results/