众所周知,实时目标检测( Real-Time Object Detection )一直由 YOLO 系列模型主导。
飞桨在去年 3 月份推出了高精度通用目标检测模型 PP-YOLOE ,同年在 PP-YOLOE 的基础上提出了 PP-YOLOE+ 。后者在训练收敛速度、下游任务泛化能力以及高性能部署能力方面均达到了很好的效果。而继 PP-YOLOE 提出后,MT-YOLOv6、YOLOv7、DAMO-YOLO、RTMDet 等模型先后被提出,一直迭代到今年开年的 YOLOv8。
而我们一直在思考,实时目标检测器除了 YOLO 是否还有其他技术路线可以探索呢?
YOLO 检测器有个较大的待改进点是需要 NMS 后处理,其通常难以优化且不够鲁棒,因此检测器的速度存在延迟。为避免该问题,我们将目光移向了不需要 NMS 后处理的 DETR,一种基于 Transformer 的端到端目标检测器。然而,相比于 YOLO 系列检测器,DETR 系列检测器的速度要慢的多,这使得"无需 NMS "并未在速度上体现出优势。上述问题促使我们针对实时的端到端检测器进行探索,旨在基于 DETR 的优秀架构设计一个全新的实时检测器,从根源上解决 NMS 对实时检测器带来的速度延迟问题。
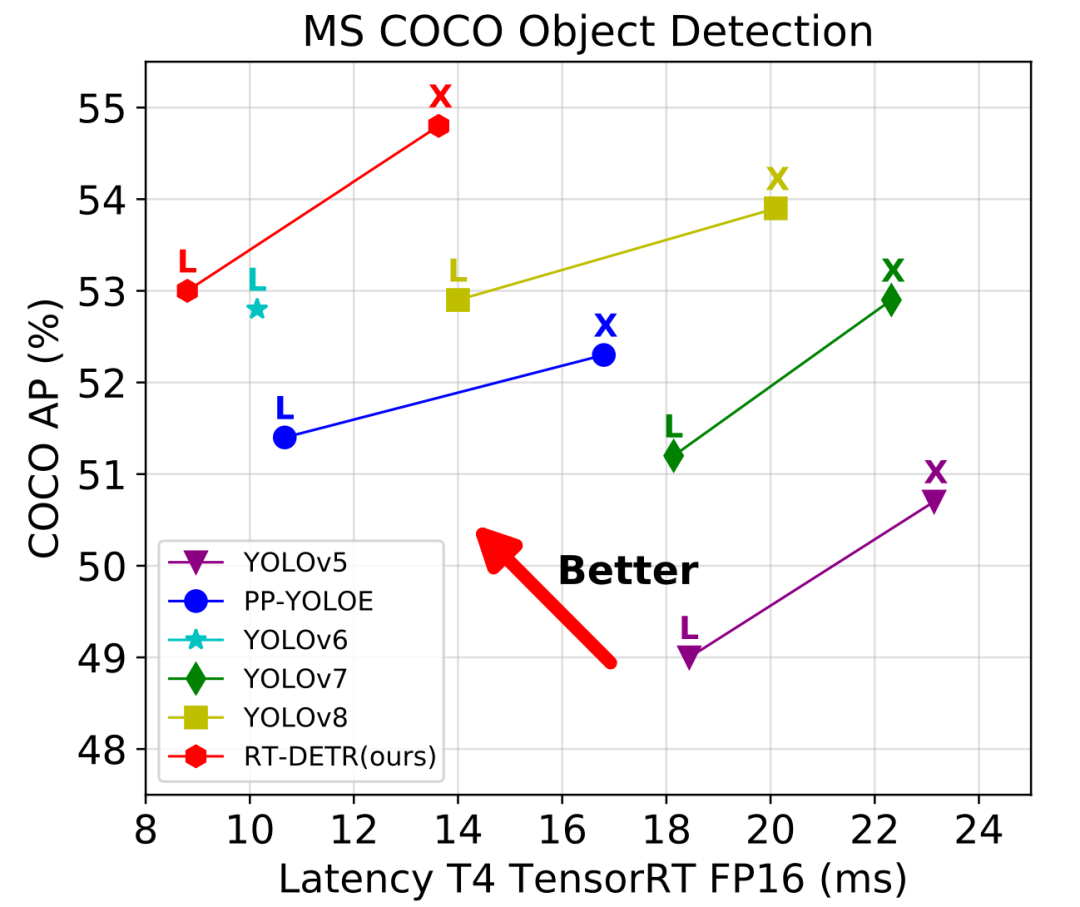
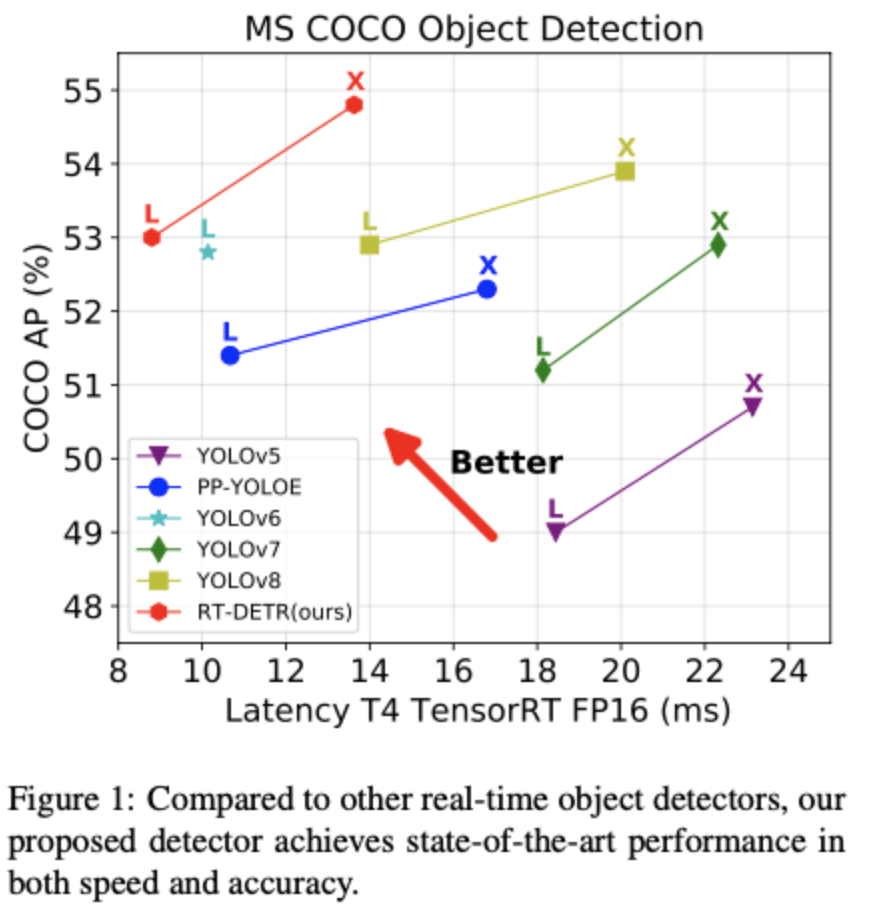
由此,我们正式推出了——RT-DETR (Real-Time DEtection TRansformer) ,一种基于 DETR 架构的实时端到端检测器,其在速度和精度上取得了 SOTA 性能。
点击文末阅读原文快速体验 RT-DETR
https://github.com/PaddlePaddle/PaddleDetection/tree/develop/configs/rtdetr
https://arxiv.org/abs/2304.08069
关于 PaddleDetection 的技术问题欢迎大家入群讨论,也欢迎大家在 GitHub 点 star 支持我们的工作!

书接上文,具体分析 NMS 。
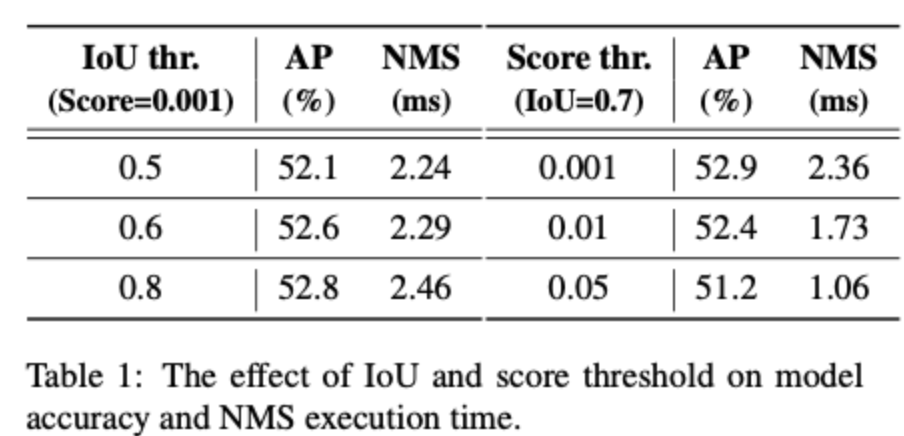
NMS 是目标检测领域常用的后处理技术,用于去除检测器产生的重叠较多的检测框,其包含两个超参数:置信度阈值和 IoU 阈值。具体来说,低于置信度阈值的框被直接过滤,并且如果两个检测框的交并比大于 IoU 阈值,那么其中置信度低的框会被滤除。该过程迭代执行,直到所有类别都被处理完毕。因此,NMS 算法的执行时间取决于预测框数量和上述两个阈值。为了更好地说明这一点,我们使用 YOLOv5 (anchor-based) 和 YOLOv8 (anchor-free) 进行了统计和实测,测量指标包括不同置信度阈值下剩余的检测框的数量,以及在不同的超参数组合下检测器在 COCO 验证集上的精度和 NMS 的执行时间。实验结果表明,NMS 不仅会延迟推理速度,并且不够鲁棒,需要挑选合适的超参数才能达到最优精度。这一实验结果有力证明设计一种实时的端到端检测器是具有重要意义的。

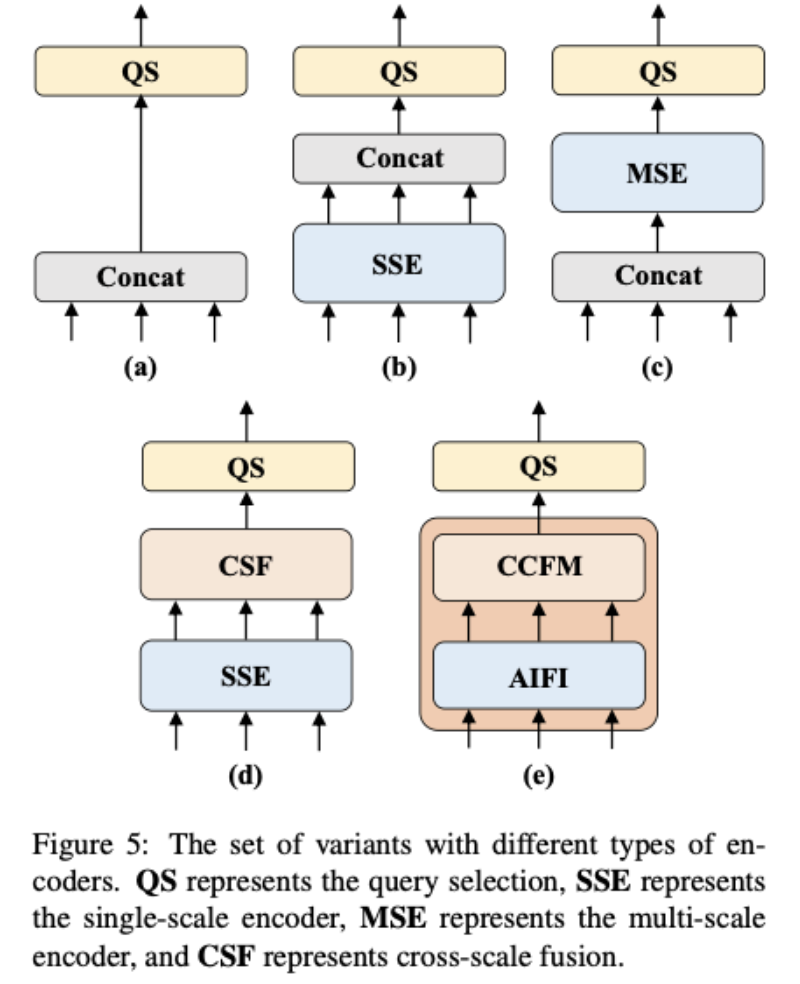
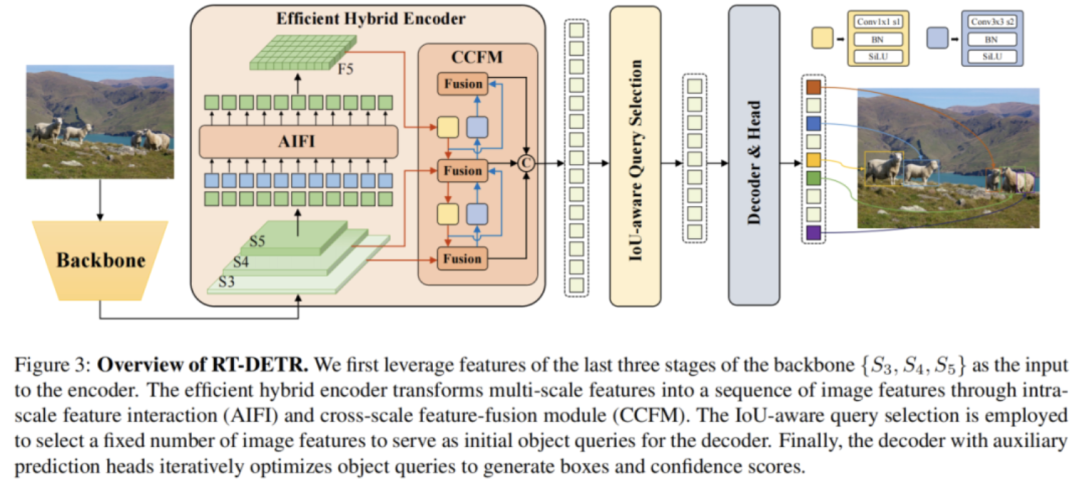
近年来,得益于研究者们在加速训练收敛和降低优化难度上做出的努力, DETR 系列模型已经获得了优秀的性能。然而,DETR 与现有实时检测器在速度上存在巨大差距,因此,将其推向实时化面临巨大的挑战。我们在分析了 DETR 变体模型的架构中各组件对速度和精度的影响后,将主要优化目标定在编码器部分。现有的多尺度 Transformer 编码器在多个尺度的特征之间进行注意力运算,同时进行尺度内和尺度间特征交互,计算消耗较大。为了减少计算消耗,一个简单的办法是直接削减编码器层数。但是我们认为这并不能从根本上解决问题并且势必会对精度造成较大影响,更本质的方法应该是要解耦这种尺度内和尺度间的同时交互,缩短输入编码器的序列长度。
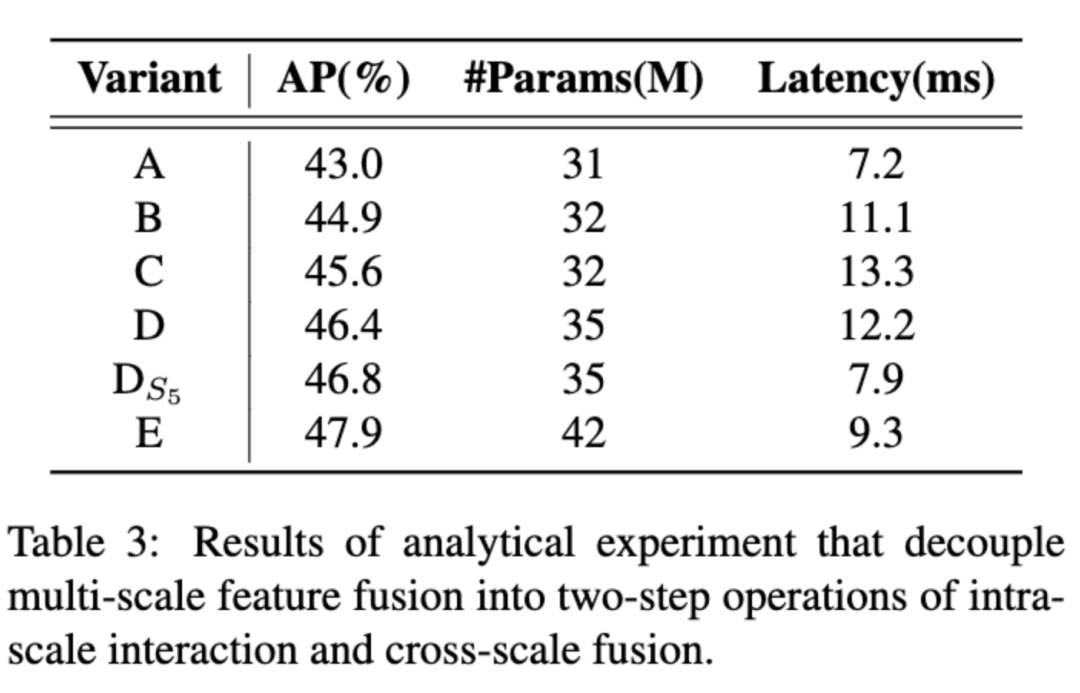
为此,我们设计了一系列编码器变体来验证解耦尺度内和尺度间特征交互的可行性并最终演化为我们提出的 HybridEncoder ,其包括两部分:Attention-based Intra-scale Feature Interaction (AIFI) 和 CNN-based Cross-scale Feature-fusion Module (CCFM) 。最后的实验结果证明了这一思路是可行的,并且可以同时在速度和精度上带来正向收益。
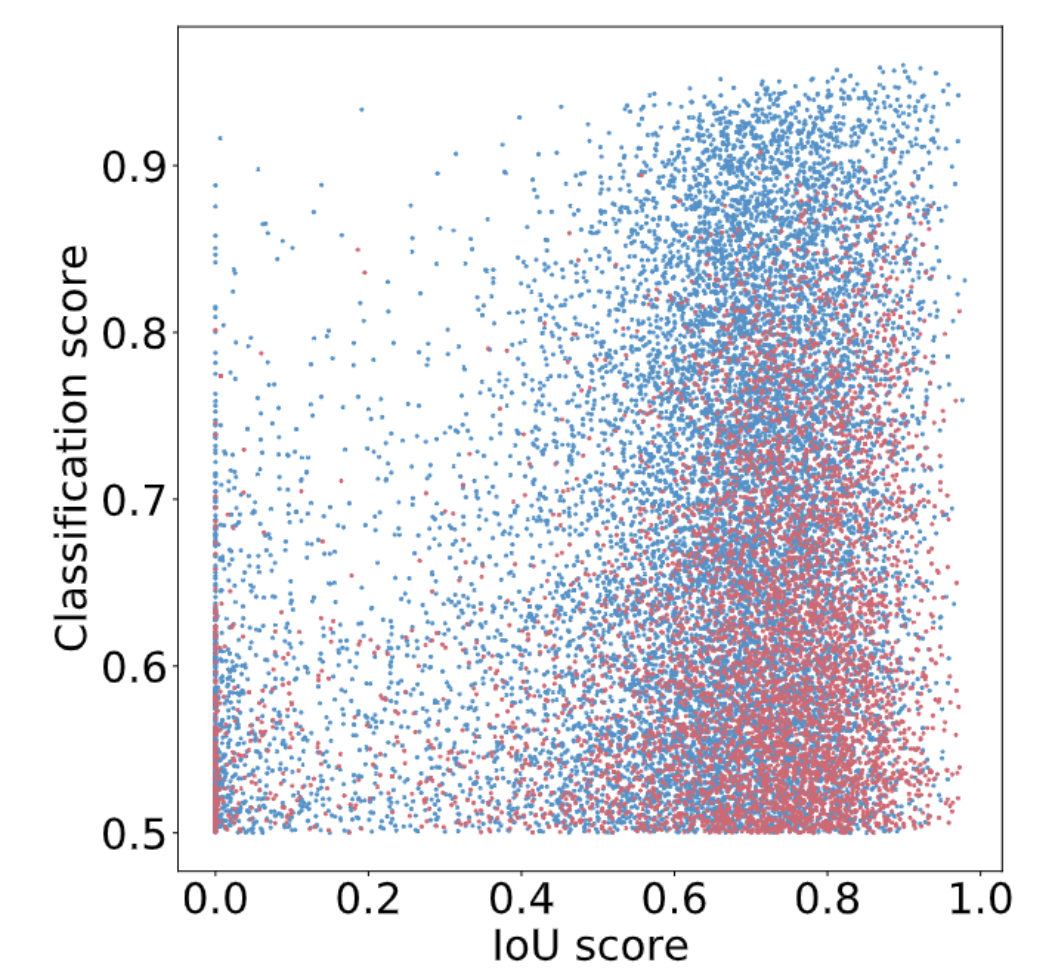
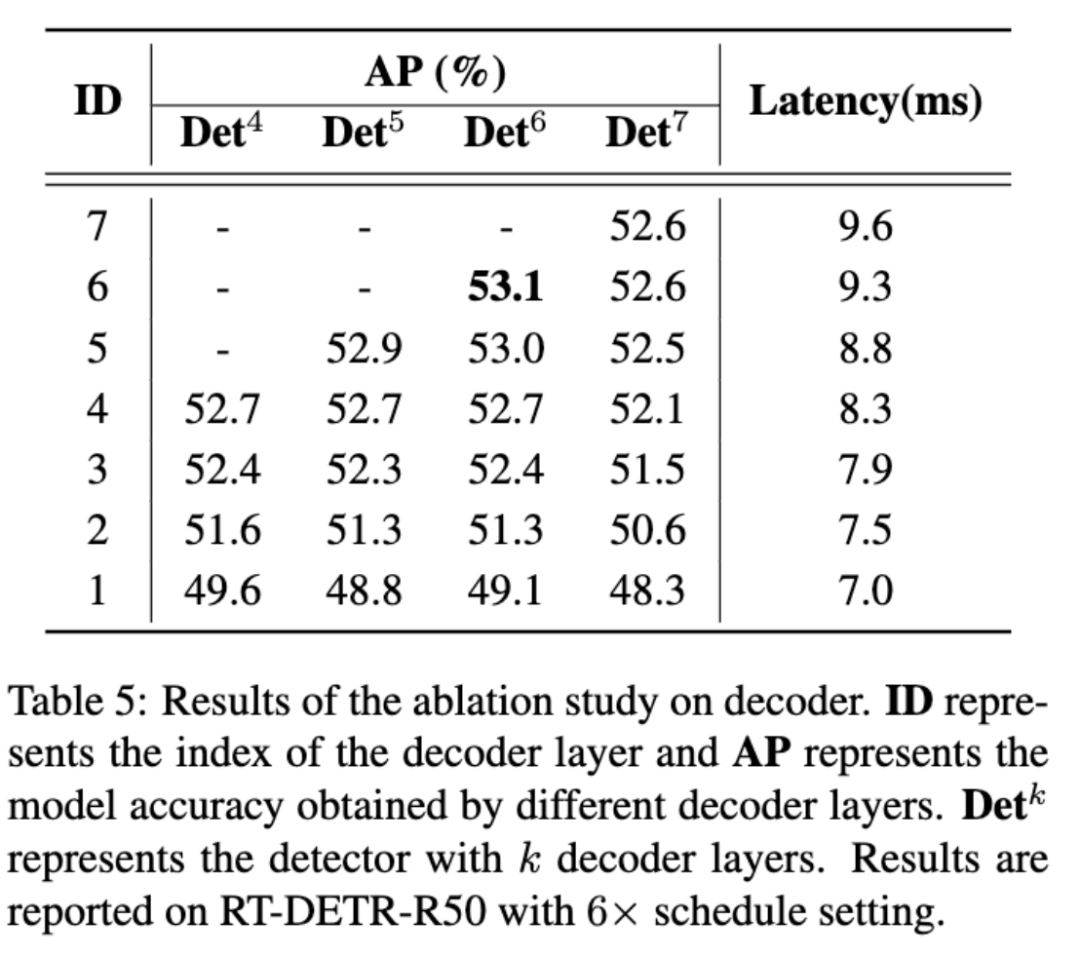
为了进一步提高 RT-DETR 的精度,我们又将目光移向了 DETR 架构的另外两个关键组件: Query Selection 和 Decoder 。 Query Selection 的作用是从 Encoder 输出的特征序列中选择固定数量的特征作为 object queries ,其经过 Decoder 后由预测头映射为置信度和边界框。现有的 DETR 变体都是利用这些特征的分类分数直接选择 top-K 特征。然而,由于分类分数和 IoU 分数的分布存在不一致,分类得分高的预测框并不一定是和 GT 最接近的框,这导致高分类分数低 IoU 的框会被选中,而低分类分数高 IoU 的框会被丢弃,这将会损害检测器的性能。
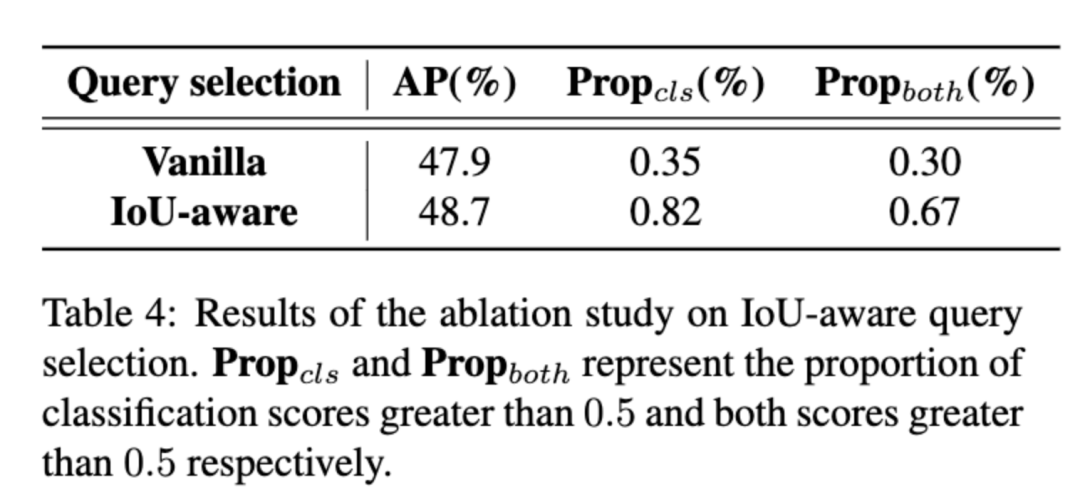
为解决这一问题,我们提出了 IoU-aware Query Selection ,通过在训练期间约束检测器对高 IoU 的特征产生高分类分数,对低 IoU 的特征产生低分类分数。从而使得模型根据分类分数选择的 top-K 特征对应的预测框同时具有高分类分数和高 IoU 分数。我们通过可视化这些编码器特征的置信度分数以及与 GT 之间的 IoU 分数后发现,IoU-aware Query Selection(蓝色点)明显提高了被选中特征的质量(集中于右上角)。对于 Decoder ,我们并没有对其结构进行调整,目的是为了方便使用高精度的 DETR 的大检测模型对轻量级 DETR 检测器进行蒸馏,我们认为这是未来可探索的一个方向。
最终我们的 RT-DETR 整体结构如下图所示:
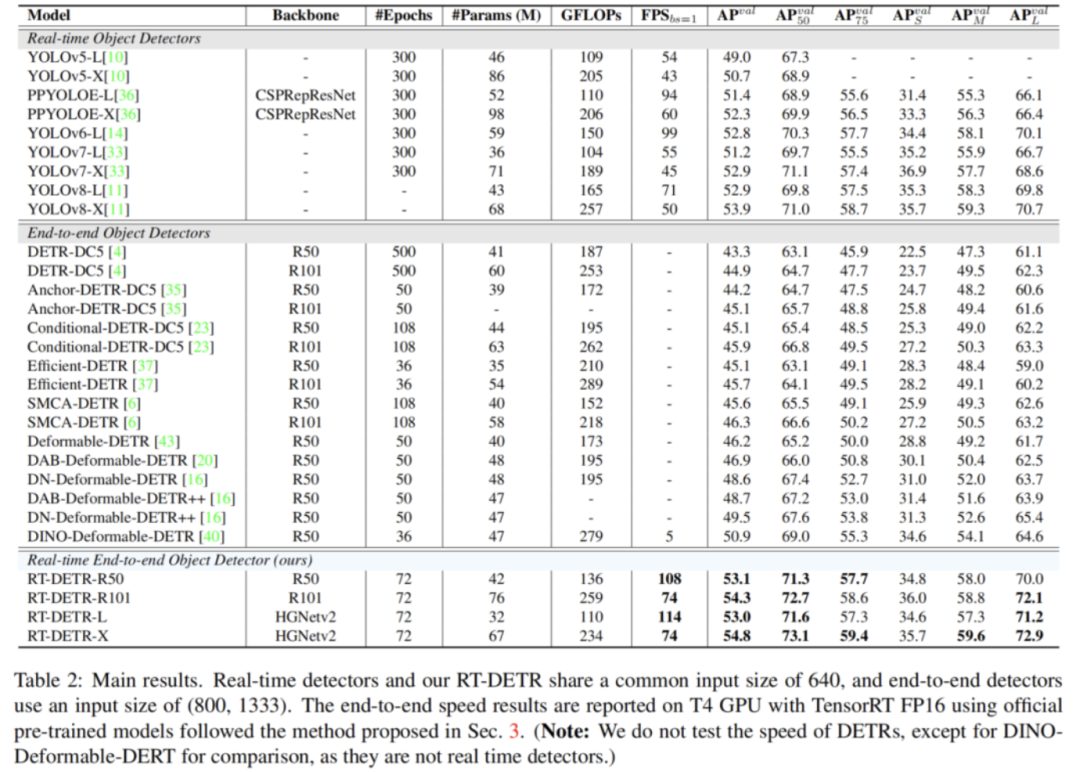
对于 backbone 部分,我们采用了经典的 ResNet 和可缩放的 HGNetv2 两种,我们本次使用两种 backbone 各训练了两个版本的 RT-DETR ,以 HGNetv2 为 backbone 的 RT-DETR 包括 L 和 X 版本,以 ResNet 为 backbone 的 RT-DETR 则包括 RT-DETR-R50 和 RT-DETR-R101 。 RT-DETR-R50 / 101 方便和现有的 DETR 变体进行对比,而 RT-DETR-L / X 则用来和现有的实时检测器( YOLO 系列模型)进行对比。
对于数据增强和训练策略部分,我们的数据增强采用的是基础的随机颜色抖动、随机翻转、裁剪和 Resize ,并且在验证和推理时图像的输入尺寸统一为 640 ,与 DETR 系列的处理方式有较大的不同,主要是为了满足实时性的要求。我们的训练策略则是和 DETR 系列基本相同,优化器同样采用 AdamW ,默认在 COCO train2017 上训练 6x ,即 72 个 epoch 。
另外,考虑到多样化的应用场景,实时检测器通常会提供多个不同尺度的模型,RT-DETR 同样可以进行缩放,我们通过调整 CCFM 中 RepBlock 的数量和 Encoder 的编码维度分别控制 Hybrid Encoder 的深度和宽度,同时对 backbone 进行相应的调整即可实现检测器的缩放。




 总结
总结