硬件接入飞桨后端方案介绍¶
随着芯片多样化的发展,不同芯片的硬件架构、指令集的设计可能不同,其软件栈及适用场景也存在差异,因此硬件与深度学习框架间存在多样化的接入方案。即使是同一款芯片也存在不同硬件接入方案,比如 Nvidia GPU 提供了 CUDA (ToolKit)高级编程接口可直接支持算子开发、高性能的 cuDNN 加速库(SDK)的接入方式、适用于推理场景的图引擎接入方式 TensorRT(SDK);一些硬件支持深度学习编译器方案,比如 TVM、MLIR;一些硬件支持神经网络交换格式方案 ONNX。
不同硬件可能存在多种技术方案并行,方案成熟度也各不相同,因此为了满足各种硬件厂商的接入需求,也为了匹配芯片中长期技术发展的规划,飞桨提供了多种硬件接入方案,包括算子开发与映射、子图与整图接入、深度学习编译器后端接入以及开源神经网络格式转化四种硬件接入方案,供硬件厂商根据自身芯片架构设计与软件栈的建设成熟度进行灵活选择。
说明:硬件厂商如需接入飞桨深度学习框架,可参考本文指导,想咨询更多信息,可发邮件至:Paddle-better@baidu.com。
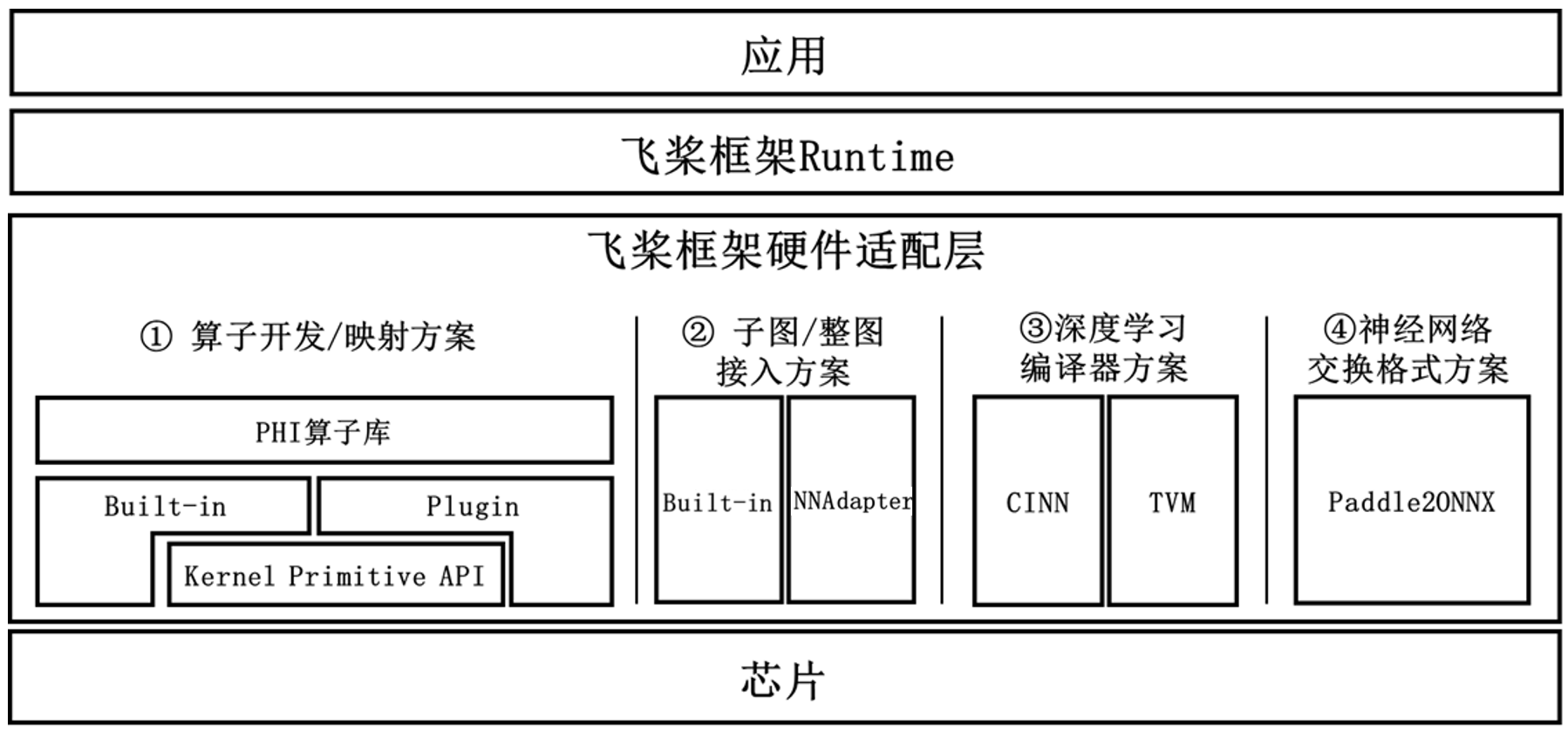
| 硬件接入方案 |
方案介绍 | 适用场景 |
|---|---|---|
| 算子开发与映射方案 | 该方案以算子为粒度对接,即对硬件侧算子库与飞桨框架侧算子库做映射,其优势是调度灵活,支持上层应用开发者以动态图的编程范式进行模型开发和调试,开发体验更佳。
|
|
| 子图与整图接入方案 | 该方案主要面向推理场景,以整图/子图为粒度对接,即实现硬件侧神经网络中间表示(IR)与飞桨框架侧神经网络中间表示的转换。该方案的优势是所有硬件相关的细节如模型的优化、生成和执行均在硬件图引擎内实现,给予硬件厂商较大的灵活性,同时能够降低硬件适配深度学习框架难度和人力成本。 |
|
| 编译器后端接入方案 | 该方案通过“中间表示代码生成方式”(Codegen)来接入硬件。编译器分为前端和后端,前端对接各种网络模型并将其转化为代表计算图的高层中间表示(HLIR),后端进一步转化计算图中间表示为计算指令级别的低层中间表示(LLIR),并基于此代码生成器(Codegen)产生在硬件上运行的指令。在各层中间表示(IR)上,编译器都会进行相关优化。硬件厂商只需对神经网络编译器的底层 IR 开发相应的代码生成器(Codegen),即可通过更低层次的方式(指从 CINN IR 转化为机器指令的过程)生成在具体硬件上的可执行指令(Machine Code)。 飞桨支持了开源深度学习编译器 TVM,也提供了自研 CINN(Compiler Infrastructure for Neural Networks)编译器,目前该自研方案正在探索和研发中。 |
|
| 神经网络格式转化方案 | 该方案面向推理场景,飞桨框架支持将飞桨模型格式转化到开源的 ONNX 模型格式。很多在线或离线的推理引擎都支持 ONNX 开源格式,这样飞桨模型也可以通过这些推理引擎部署到更多的硬件类型上。 飞桨提供了模型转换工具 Paddle2ONNX,将飞桨模型转换为 ONNX 格式。 |
|