
课程简介

聊天机器人的“前世今生”
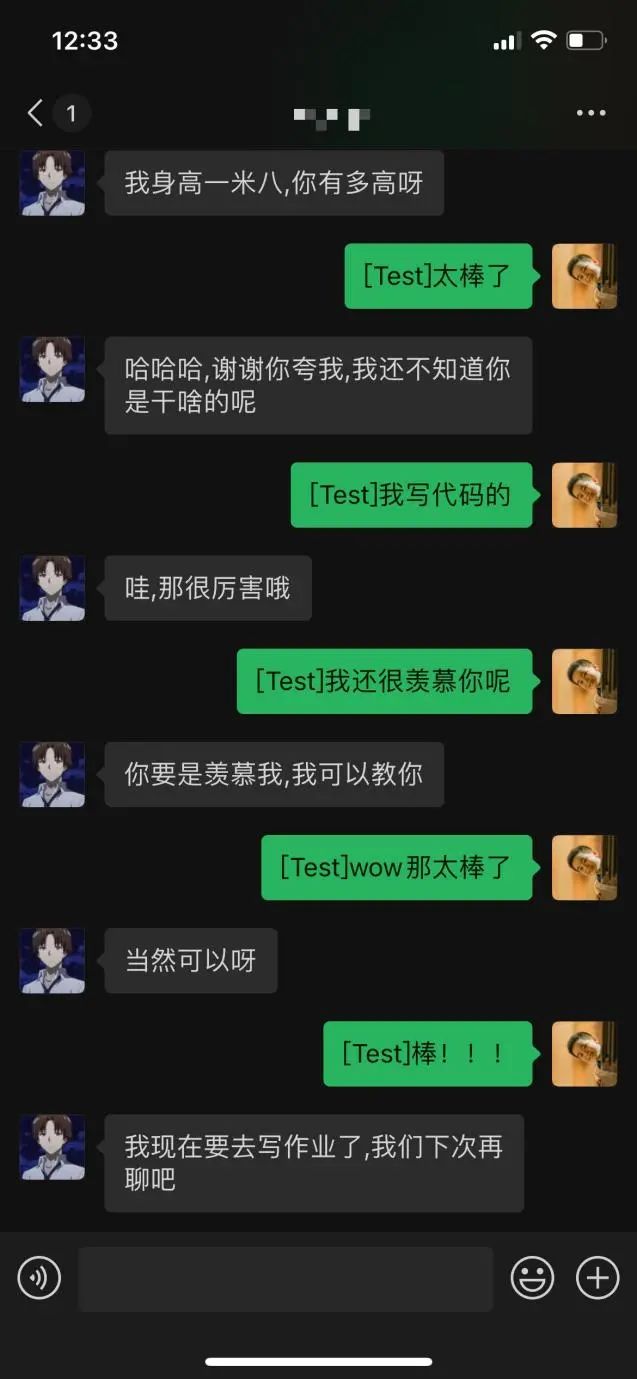
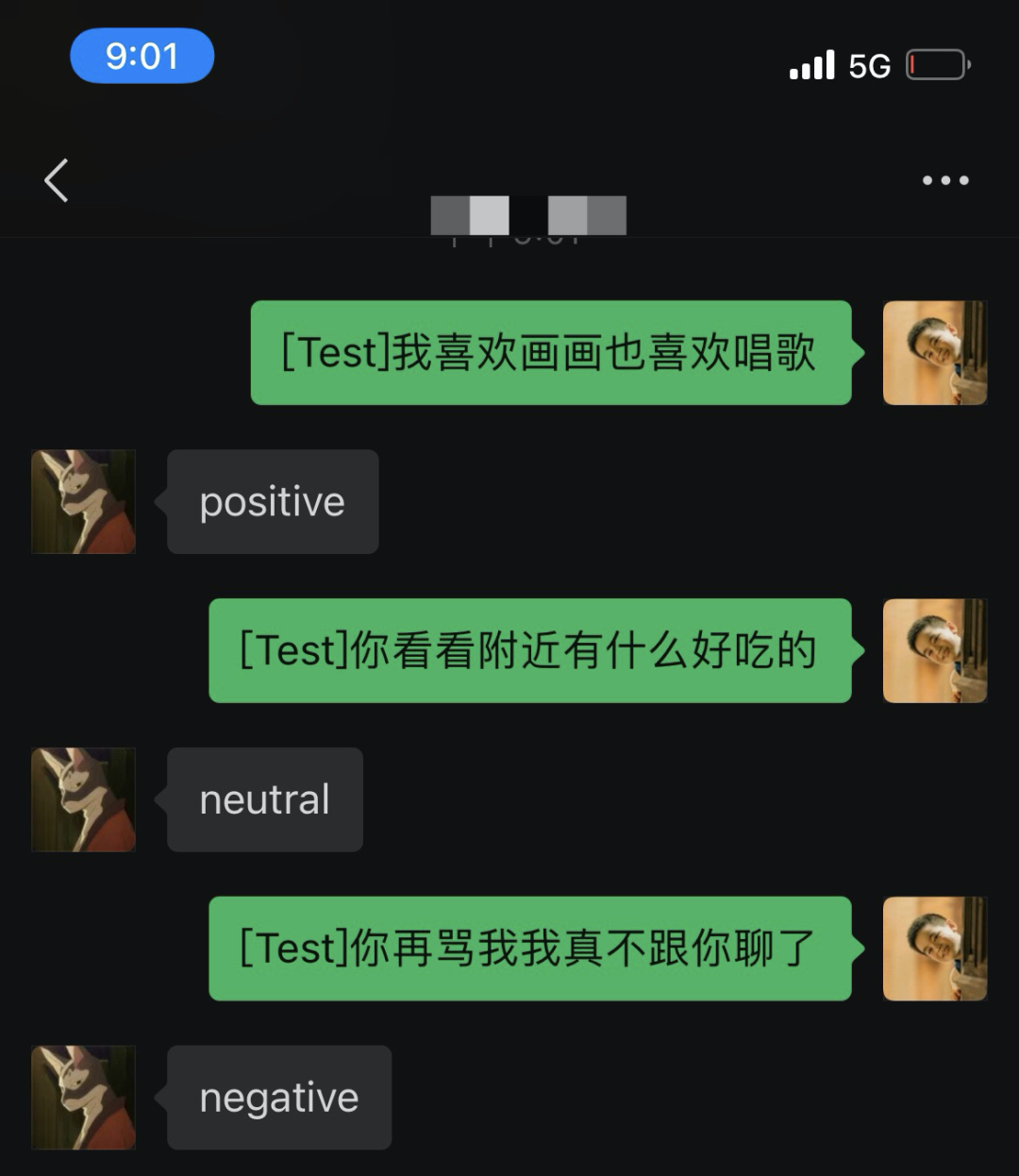
快速实践
2.1 GPT模型使用生成API的小示例
文本数据在输入预训练模型之前,需要经过数据处理转化为Feature。这一过程通常包括分词,token to id,add special token等步骤。
from paddlenlp.transformers import GPTChineseTokenizer
# 设置想要使用模型的名称
model_name = 'gpt-cpm-small-cn-distill'
tokenizer = GPTChineseTokenizer.from_pretrained(model_name)import paddle
user_input = "花间一壶酒,独酌无相亲。举杯邀明月,"
# 将文本转为ids
input_ids = tokenizer(user_input)['input_ids']
print(input_ids)
# 将转换好的id转为tensor
input_ids = paddle.to_tensor(input_ids, dtype='int64').unsqueeze(0)
2.使用PaddleNLP一键加载预训练模型
from paddlenlp.transformers import GPTLMHeadModel
# 一键加载中文GPT模型
model = GPTLMHeadModel.from_pretrained(model_name)
# 调用生成API升成文本
ids, scores = model.generate(
input_ids=input_ids,
max_length=16,
min_length=1,
decode_strategy='greedy_search')
generated_ids = ids[0].numpy().tolist()
# 使用tokenizer将生成的id转为文本
generated_text = tokenizer.convert_ids_to_string(generated_ids)
print(generated_text)
对影成三人。 2.2 UnifiedTransformer
模型和生成式API完成闲聊对话
1.加载paddlenlp.transformers.UnifiedTransformerTokenizer用于数据处理
from paddlenlp.transformers import UnifiedTransformerTokenizer
# 设置想要使用模型的名称
model_name = 'plato-mini'
tokenizer = UnifiedTransformerTokenizer.from_pretrained(model_name)user_input = ['你好啊,你今年多大了']
# 调用dialogue_encode方法生成输入
encoded_input = tokenizer.dialogue_encode(
user_input,
add_start_token_as_response=True,
return_tensors=True,
is_split_into_words=False)2.使用PaddleNLP一键加载预训练模型
unified_transformer-12L-cn 该预训练模型是在大规模中文会话数据集上训练得到的。
unified_transformer-12L-cn-luge 该预训练模型是unified_transformer-12L-cn在千言对话数据集上进行微调得到的。
plato-mini 该模型使用了十亿级别的中文闲聊对话数据进行预训练。
from paddlenlp.transformers import UnifiedTransformerLMHeadModel
model = UnifiedTransformerLMHeadModel.from_pretrained(model_name)
ids, scores = model.generate(
input_ids=encoded_input['input_ids'],
token_type_ids=encoded_input['token_type_ids'],
position_ids=encoded_input['position_ids'],
attention_mask=encoded_input['attention_mask'],
max_length=64,
min_length=1,
decode_strategy='sampling',
top_k=5,
num_return_sequences=20)
from utils import select_response
# 简单根据概率选取最佳回复
result = select_response(ids, scores, tokenizer, keep_space=False, num_return_sequences=20)
print(result)
['你好啊,我今年23岁了']
动手试一试
加入交流群,一起学习吧

回顾往期
越学越有趣:『手把手带你学NLP』系列项目01 ——词向量应用的那些事儿
越学越有趣:『手把手带你学NLP』系列项目02 ——语义相似度计算的那些事儿
越学越有趣:『手把手带你学NLP』系列项目03 ——快递单信息抽取的那些事儿
越学越有趣:『手把手带你学NLP』系列项目04 ——实体关系抽取的那些事儿
越学越有趣:『手把手带你学NLP』系列项目05 ——文本情感分析的那些事儿
越学越有趣:『手把手带你学NLP』系列项目06 ——机器阅读理解的那些事儿
越学越有趣:『手把手带你学NLP』系列项目07 ——机器翻译的那些事儿
越学越有趣:『手把手带你学NLP』系列项目08 ——“不缺钱,只缺人” ,同传翻译的那些事儿
越学越有趣:『手把手带你学NLP』系列项目09 ——“此苹果非彼苹果”看意图识别的那些事儿
越学越有趣:『手把手带你学NLP』系列项目10 ——NLP预训练模型小型化与部署的那些事儿

飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体,是中国首个自主研发、功能丰富、开源开放的产业级深度学习平台。飞桨企业版针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END
