导读
支持对图片形式的文档进行版面分析,可以划分文字、标题、表格、图片以及列表5类区域(与Layout-Parser联合使用)
支持文字、标题、图片以及列表区域提取为文字字段(与PP-OCR联合使用)
支持表格区域进行结构化分析,最终结果输出Excel文件
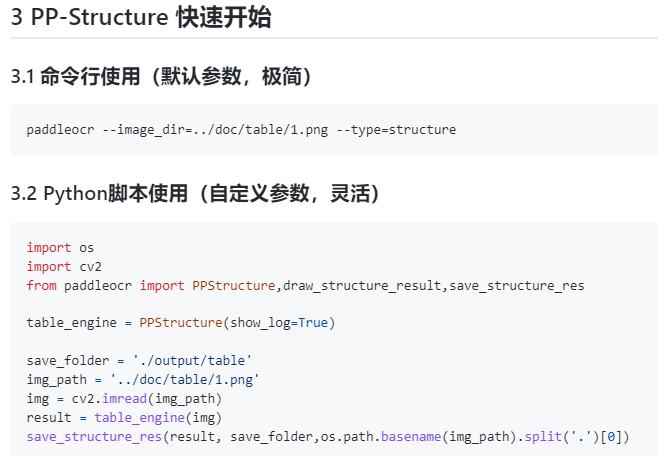
支持Python whl包和命令行两种方式,简单易用
支持版面分析和表格结构化两类任务自定义训练
一张动图看效果
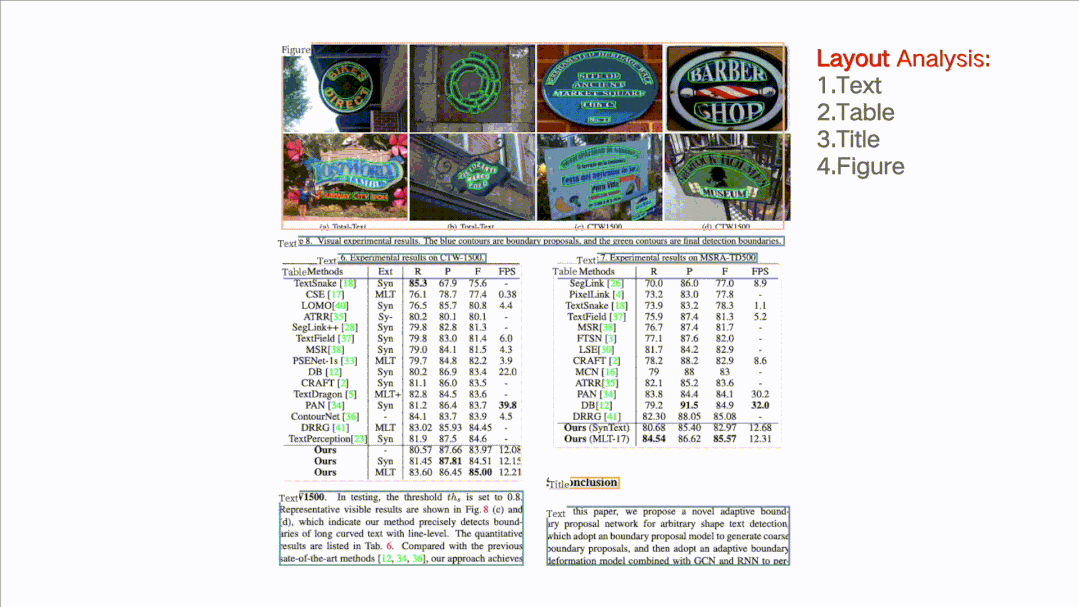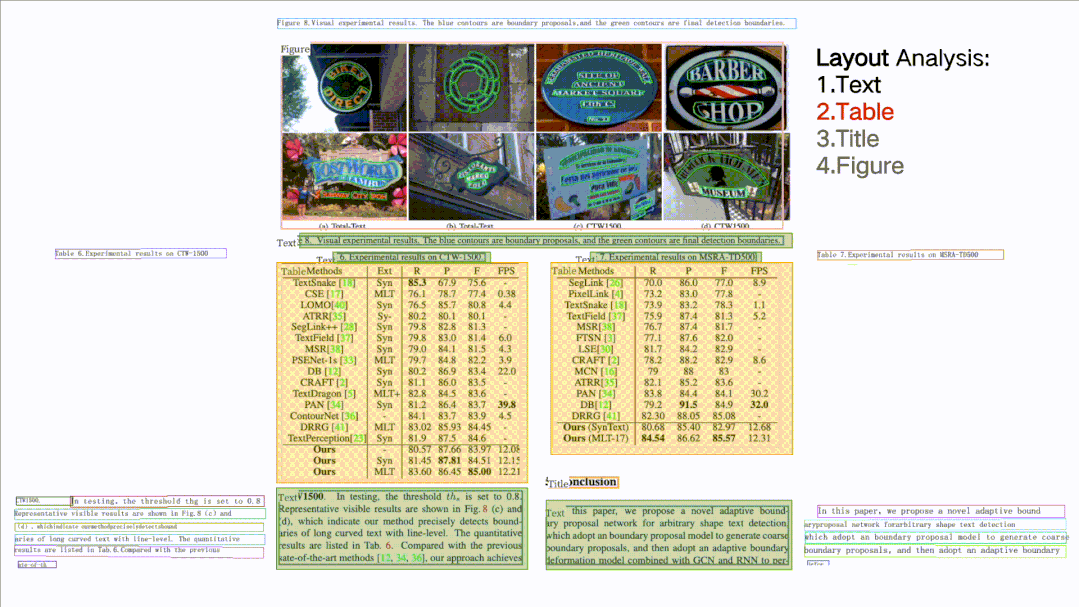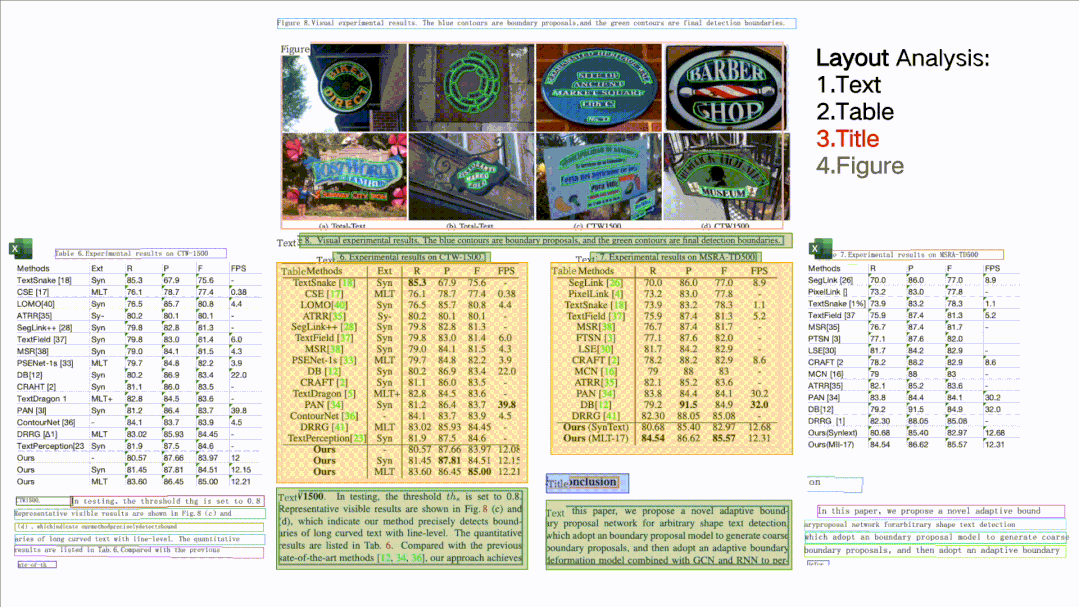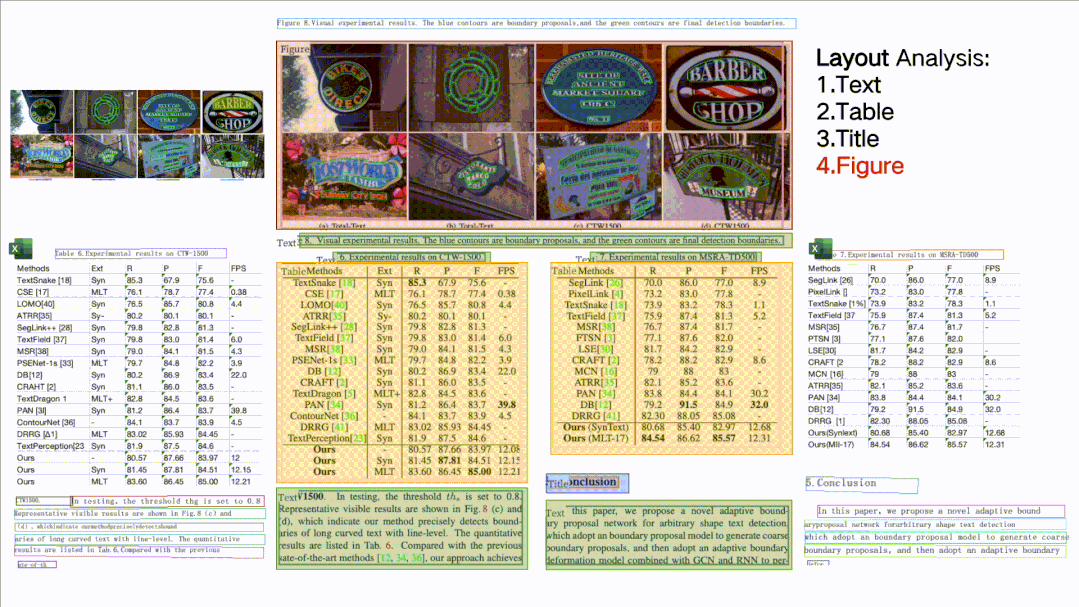
版面分析与表格识别核心技术
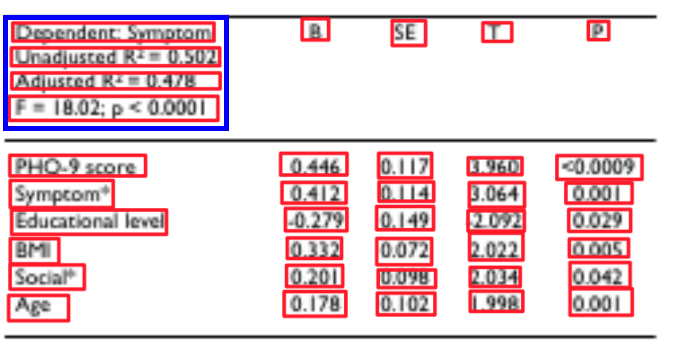
(1)传统方法:版面分析比较著名的是O’Gorman在1993年TPAMI中发表的算法Docstrum。通过自下而上的方法依次将图像中的黑白连通域划分为文字、文本行与文本块,从而得到版面布局。表格识别的传统方法通过腐蚀、膨胀等操作获得表格线、划分行列区域,然后将单元格与文本内容相结合重构为表格对象。但是传统算法主要问题在于,对于版面布局分析和表格结构的提取,图像处理的方法依赖各种阈值和参数的选择,对于不同场景下的文档图片难以保证泛化性。
(2)深度学习方法:除了直接使用检测模型来对版面内容进行分类以外,还融合了检测、分割、图神经网络、注意力机制等众多前沿技术能力。依赖算法工程师对于深度神经网络的精心设计,可以不再依赖阈值与参数,具有更好的泛化性。
PP-Structure核心技术解读
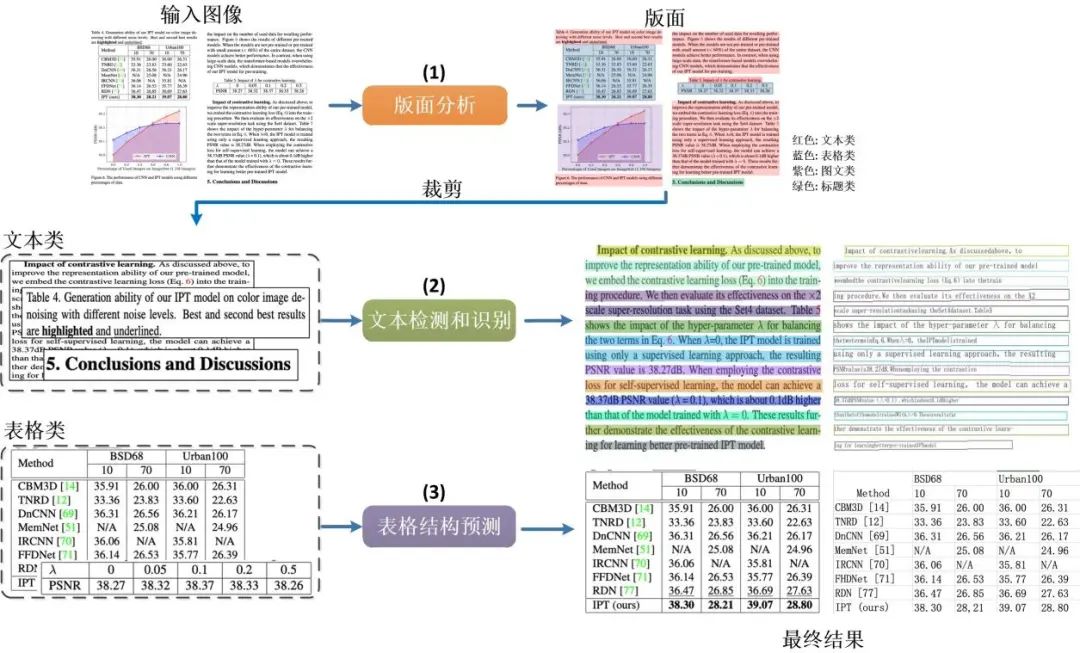

而针对于表格图片的图片描述网络,输入一张经过版面分析的表格图片,输出的是一串HTML字符(如下图所示)。表格的结构通过HTML的结构标记表示,其中的内容即为表格文本中的内容。通过进一步的HTML解析,可以获得每个文本的单元格四点坐标和表格结构信息。
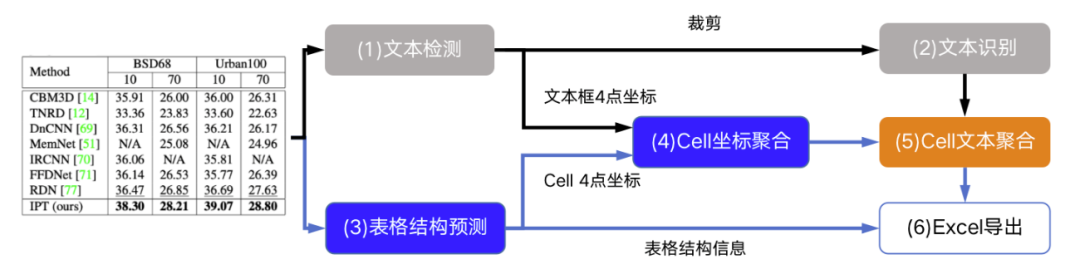
(4)Cell坐标聚合模块,主要用来解决如何将跨行单元格的文本重新拼接在一个单元格内的问题。它通过计算由文本检测算法获得的文本框坐标(红色框)与表格结构预测模块得到的Cell坐标(蓝色框)之间的IOU和顶点距离来进行单行到多行的聚合。使用IOU判断哪些红色框同属于一个蓝色框,使用顶点距离和IOU判断红色框的排列顺序。
(5)Cell文本聚合模块,根据已有的红色文本框顺序,按照从上到下从左到右顺序利用(4)Cell坐标聚合模块的结果将(2)文本识别结果和进行拼接,这样对于多行文本的单元格内容即可拼接成一个字符串。
(6)Excel导出模块,将(3)表格结构预测结果html结果与(5)Cell文本聚合模块文本结果结合,最终导出为Excel输出。
欢迎使用
(中英文文档教程)
PP-Structure的使用也是非常方便,在完成Python whl包安装之后,简单代码即可完成快速试用。
详细文档,请参考:
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.2/ppstructure/README_ch.md
微信扫描二维码添加运营同学,并回复【OCR】,运营同学邀请您加入官方交流群,获得更高效的问题答疑,与各行各业开发者充分交流,期待您的加入!
·PaddleOCR项目地址·
Gitee:
https://gitee.com/paddlepaddle/PaddleOCR

飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体,是中国首个自主研发、功能丰富、开源开放的产业级深度学习平台。飞桨企业版针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END