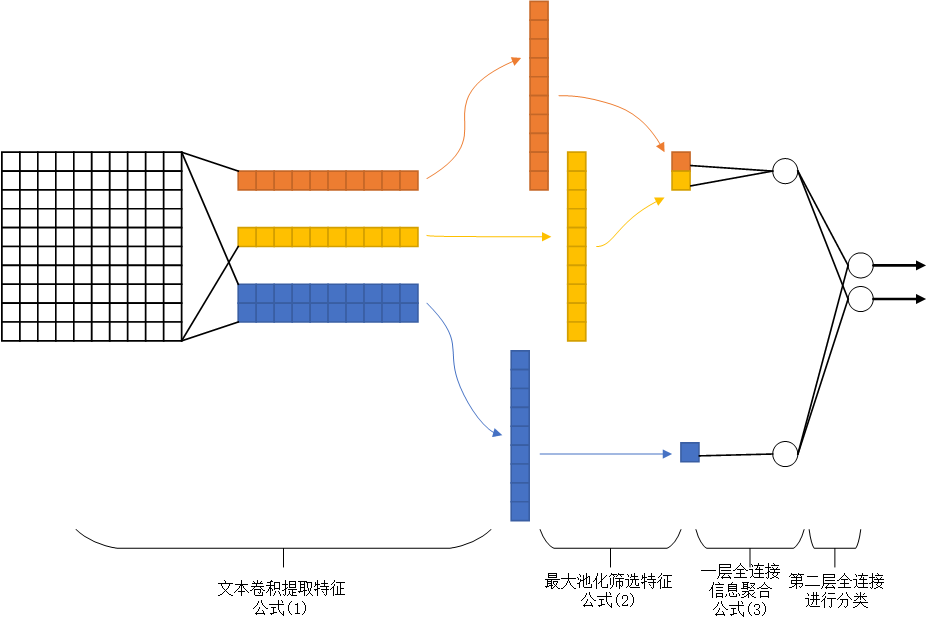
相关研究
方案
3.1 数据准备
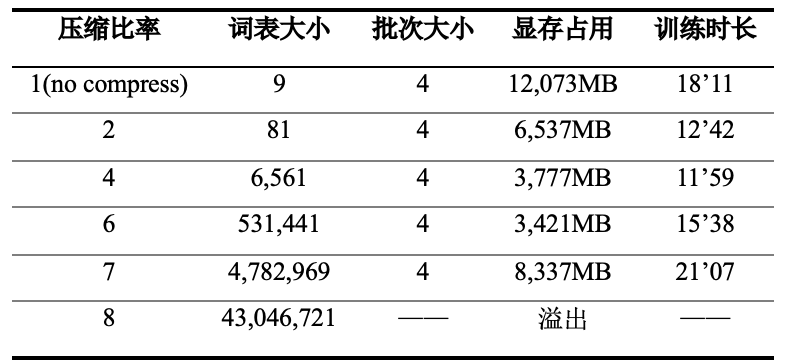
3.2 词典压缩算法
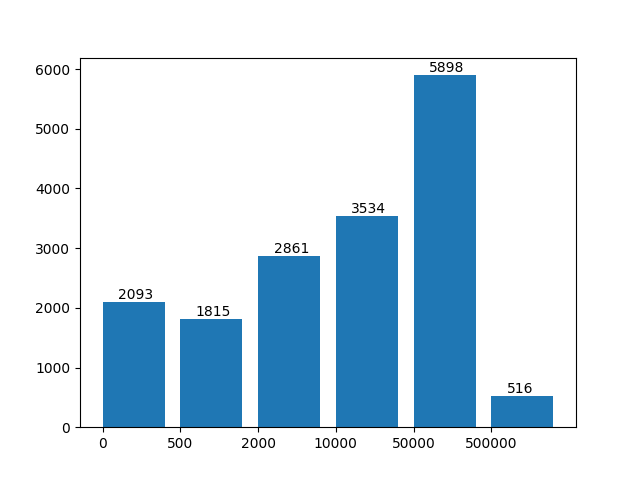
图3.2:特征向量长度分布图
def vocab_compress(vocab_dict,rate=4):
if rate<=0:
return
with open('dict.txt','w',encoding='utf-8') as fp:
arr=np.zeros(rate,int)
while True:
pos=rate-1
for i in range(rate):
fp.write(vocab_dict[arr[i]])
fp.write('\n')
arr[pos]+=1
while True:
if arr[pos]>=len(vocab_dict):
arr[pos]=0
pos-=1
if pos<0:
return
arr[pos]+=1
else:
break
3.3 模型构造
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
import paddlenlp as ppnlp
class CNNModel(nn.Layer):
def __init__(self,
vocab_size,
num_classes,
emb_dim=64,
padding_idx=0,
fc_hidden_size=32):
super().__init__()
# 首先将输入word id 查表后映射成 word embedding
self.embedder = nn.Embedding(
num_embeddings=vocab_size,
embedding_dim=emb_dim,
padding_idx=padding_idx)
self.cnn_encoder = ppnlp.seq2vec.CNNEncoder(
emb_dim,
num_filter=12,
ngram_filter_sizes=(1, 2, 3, 4),
conv_layer_activation=nn.Tanh()
)
self.fc = nn.Linear(self.cnn_encoder.get_output_dim(), out_features=fc_hidden_size)
# 最后的分类器
self.output_layer = nn.Linear(fc_hidden_size, out_features=num_classes)
def forward(self, text, seq_len):
# text shape: (batch_size, num_tokens)
#print('input :', text.shape,text)
# Shape: (batch_size, num_tokens, embedding_dim)
embedded_text = self.embedder(text)
#print('after embedding:', embedded_text.shape)
#Shape: (batch_size, num_filter*ngram_filter_size)
cnn_out = self.cnn_encoder(embedded_text)
#print('after cnn:', cnn_out.shape)
# Shape: (batch_size, fc_hidden_size)
fc_out = paddle.tanh(self.fc(cnn_out))
# print('after Linear classifier:', fc_out.shape)
# Shape: (batch_size, num_classes)
logits = self.output_layer(fc_out)
#print('output:', logits.shape)
# probs 分类概率值
probs = F.softmax(logits, axis=-1)
#print('output probability:', probs.shape)
return probs
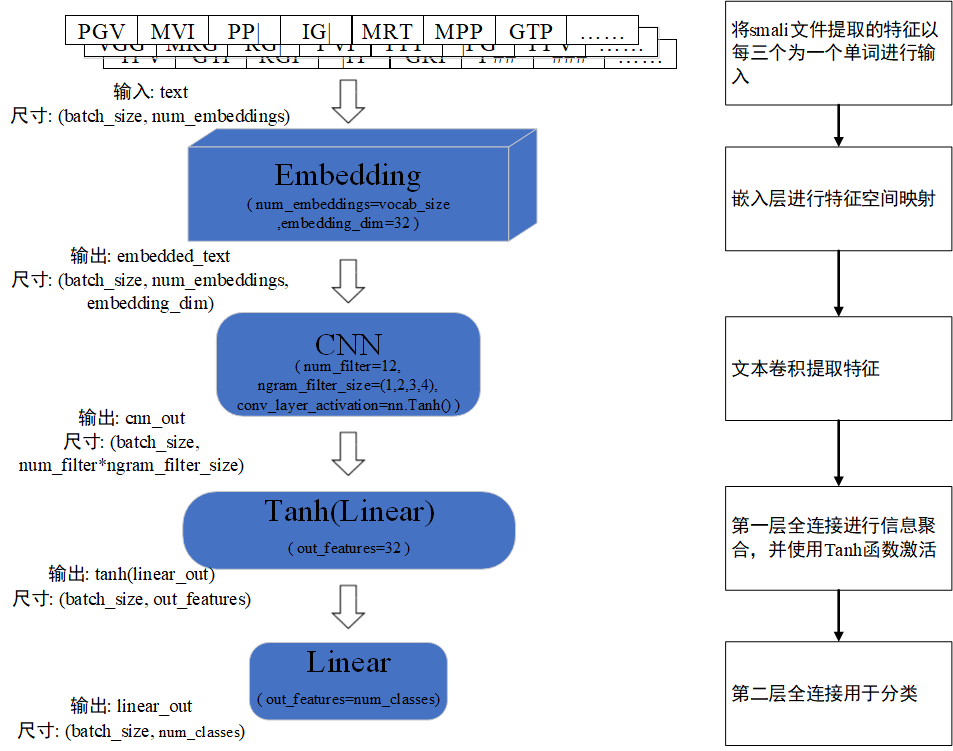
图3.3 模型结构图
实验过程与分析
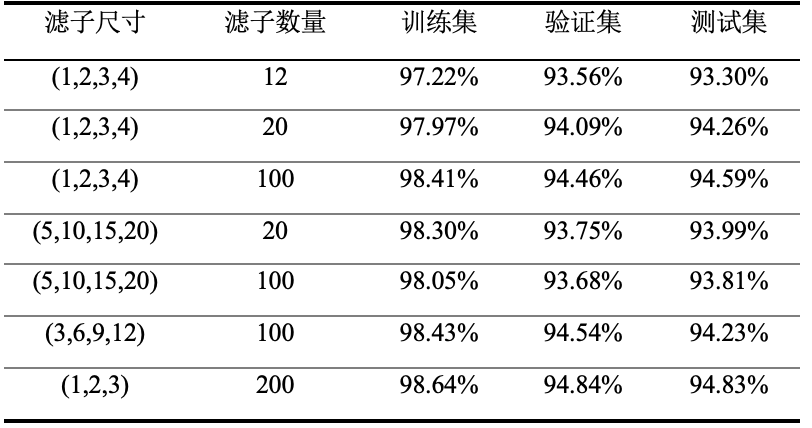
根据4.2表,认为如同Oxford Visual Geometry Group在2014年ImageNet Large Scale Visual Recognition Challenge(ILSVRC)竞赛上提出的通过较小的卷积核进行纵向的深度叠加可以拥有大尺寸卷积核的效果[4]那样,使用小尺寸的文本滤子组在时序特征提取上进行横向的组合也拥有类似的效果。即使用2个1-gram滤子提取出的特征,经过一次全连接的线性变换将信息聚合后可以相当一个2-gram滤子提取出的特征。
from paddlenlp.datasets import load_dataset
def read(data_path):
with open(data_path, 'r', encoding='utf-8') as f:
for line in f:
l = line.strip('\n').split('\t')
if len(l) != 2:
print (len(l), line)
words, labels = line.strip('\n').split('\t')
if len(words)==0:
continue
yield {'tokens': words, 'labels': labels}
# data_path为read()方法的参数
train_ds = load_dataset(read, data_path='dataset/train.txt',lazy=False)
dev_ds = load_dataset(read, data_path='dataset/eval.txt',lazy=True)
test_ds = load_dataset(read, data_path='dataset/test.txt',lazy=True)
# 加载词表
vocab = load_vocab('dict.txt')
#print(vocab)
# Reads data and generates mini-batches.
def create_dataloader(dataset,
trans_function=None,
mode='train',
batch_size=1,
pad_token_id=0,
batchify_fn=None):
if trans_function:
dataset_map = dataset.map(trans_function)
# return_list 数据是否以list形式返回
# collate_fn 指定如何将样本列表组合为mini-batch数据。传给它参数需要是一个callable对象,需要实现对组建的batch的处理逻辑,并返回每个batch的数据。在这里传入的是`prepare_input`函数,对产生的数据进行pad操作,并返回实际长度等。
dataloader = paddle.io.DataLoader(
dataset_map,
return_list=True,
batch_size=batch_size,
collate_fn=batchify_fn)
return dataloader
# python中的偏函数partial,把一个函数的某些参数固定住(也就是设置默认值),返回一个新的函数,调用这个新函数会更简单。
trans_function = partial(
convert_example,
vocab=vocab,
rate=rate,
unk_token_id=vocab.get(unk),
is_test=False)
# 将读入的数据batch化处理,便于模型batch化运算。
# batch中的每个句子将会padding到这个batch中的文本最大长度batch_max_seq_len。
# 当文本长度大于batch_max_seq时,将会截断到batch_max_seq_len;当文本长度小于batch_max_seq时,将会padding补齐到batch_max_seq_len.
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=vocab[pad]), # input_ids
Stack(dtype="int64"), # seq len
Stack(dtype="int64") # label
): [data for data in fn(samples)]
train_loader = create_dataloader(
train_ds,
trans_function=trans_function,
batch_size=4,
mode='train',
batchify_fn=batchify_fn)
dev_loader = create_dataloader(
dev_ds,
trans_function=trans_function,
batch_size=4,
mode='validation',
batchify_fn=batchify_fn)
test_loader = create_dataloader(
test_ds,
trans_function=trans_function,
batch_size=4,
mode='test',
batchify_fn=batchify_fn)
model= CNNModel(
len(vocab),
num_classes=5,
padding_idx=vocab[pad])
model = paddle.Model(model)
# 加载模型
#model.load('./checkpoints/final')
optimizer = paddle.optimizer.Adam(
parameters=model.parameters(), learning_rate=1e-5)
loss = paddle.nn.loss.CrossEntropyLoss()
metric = paddle.metric.Accuracy()
model.prepare(optimizer, loss, metric)
# 设置visualdl路径
log_dir = './visualdl'
callback = paddle.callbacks.VisualDL(log_dir=log_dir)
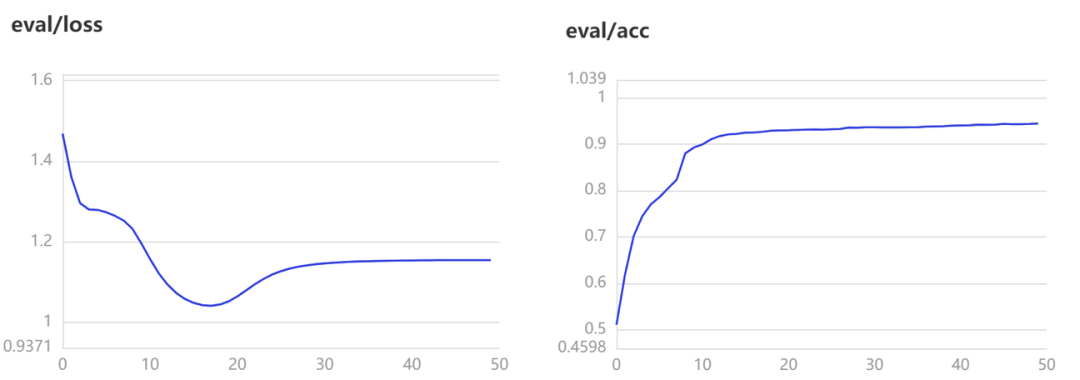
model.fit(train_loader, dev_loader, epochs=50, log_freq=50, save_dir='./checkpoints', save_freq=1, eval_freq=1, callbacks=callback)
end=datetime.datetime.now()
print('Running time: %s Seconds'%(end-start))
results = model.evaluate(train_loader)
print("Finally train acc: %.5f" % results['acc'])
results = model.evaluate(dev_loader)
print("Finally eval acc: %.5f" % results['acc'])
results = model.evaluate(test_loader)
print("Finally test acc: %.5f" % results['acc'])
结论
参考文献
[1] McLaughlin N, Martinez del Rincon J, Kang B J, et al. Deep android malware detection[C]//Proceedings of the Seventh ACM on Conference on Data and Application Security and Privacy. 2017: 301-308.
[2] Zhang Y , Wallace B . A Sensitivity Analysis of (and Practitioners' Guide to) Convolutional Neural Networks for Sentence Classification[J]. Computer Science, 2015.
[3] Samaneh Mahdavifar, Andi Fitriah Abdul Kadir, Rasool Fatemi, et al. Dynamic Android Malware Category Classification using Semi-Supervised Deep Learning[C]. IEEE 18th International Conference on Dependable, Autonomic, and Secure Computing (DASC), 2020: 17-24.
[4] Simonyan K , Zisserman A . Very Deep Convolutional Networks for Large-Scale Image Recognition[J]. Computer Science, 2014.

飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体,是中国首个自主研发、功能丰富、开源开放的产业级深度学习平台。飞桨企业版针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END