深度卷积骨干结构在图像分类,实例分割等方面取得了重大进展,多种具有里程碑意义的骨干网络结构大多都使用多层3X3卷积。虽然卷积运算可以有效地捕获局部信息,但目标检测、实例分割、关键点检测等视觉任务需要对长距离依赖进行建模。
为了全局聚合本地捕获的滤波器响应,基于卷积的架构需要堆叠多个层。尽管堆叠更多层确实提高了这些主干的性能,但一种对全局依赖项建模的显式机制可能是一种更强大和可扩展的解决方案,而无需那么多卷积层。业界从自然语言处理(NLP)任务中汲取灵感,在视觉任务中使用Transformer中的多头自注意力(MHSA)层替换空间卷积层,进而诞生了BotNet这一革新的网络。
CV Transformer的时代已经到来!
本项目已在AI Studio开源,可与此文档一同观看,有助于更好的了解。
项目地址:
https://aistudio.baidu.com/aistudio/projectdetail/2265776
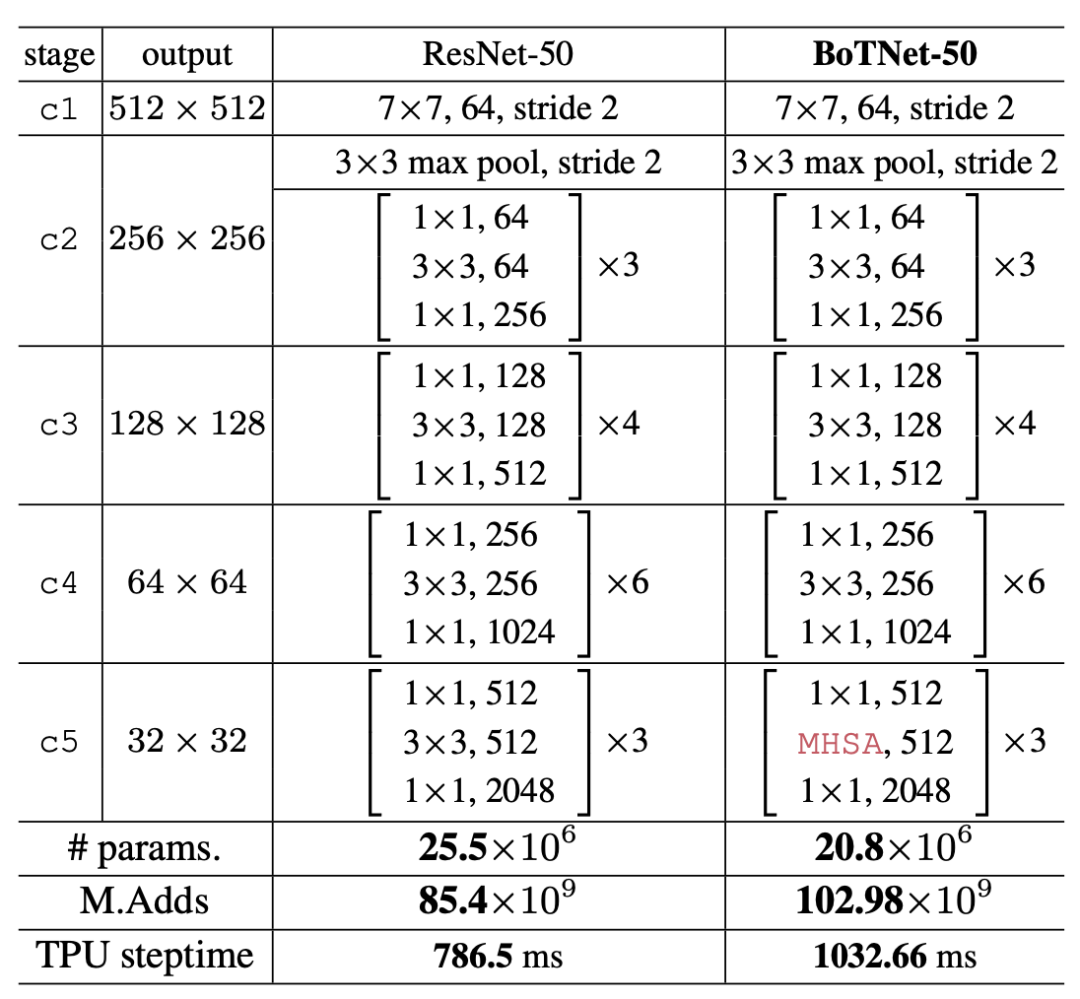
由于BotNet与ResNet极为相似,这里我们以BotNet-50与ResNet-50相比较,来让大家更好的理解BotNet的网络结构。
BotNet即将ResNet中的第4个block中的bottleneck替换为MHSA(Multi-Head Self-Attention)模块,形成新的模块,取名叫做Bottleneck Transformer (BoT) 。最终由BoT这样的block组合成的网络结构就叫做BotNet。
从上图中我们可以看到BotNet仅仅对ResNet-50 C5结构进行了更换,仅仅是更换了这一部分,最终基于BotNet的Mask R-CNN的实例分割在coco数据集上取得了44.4% Mask AP ,49.7% Box AP。在分类任务中,在 ImageNet上取得了84.7%的top-1准确性。并且比 EfficientNet快2.33倍。
当时看到这里我也有些疑问,既然MHSA这么强大为什么不把C2到C5的所有3X3卷积层都更换为MHSA呢?最终我在论文中发现,如果全部更换为MHSA,其计算量将会是几何甚至指数级提升,但带来的效益却远远不成正比。所以最终只修改了C5的结构。
接下来我们将从复现MHSA开始一步一步最终复现到BotNet网络。
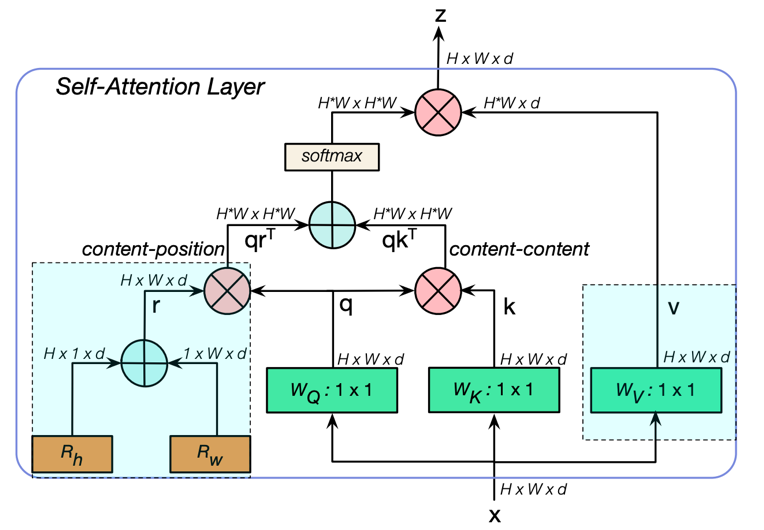
BoTNet块中使用的多头自注意 (MHSA) 层。all2all attention是在 2D 特征图上执行的,其中高度和宽度的相对位置编码分别为 Rh 和 Rw。logits attention是 qkT + qrT,其中 q; k; r 分别代表查询、键和位置编码。十 和 X 分别代表逐元素求和和矩阵乘法,而 1x1 代表逐点卷积。蓝色的部分分别代表position encodings 和 value projection。
与Transformer中的MHSA有所区别的是,MHSA在position部分 使用两个向量当做横纵两个纬度的空间注意力,相加之后,与q相乘得到content-position,再将content-position和content-content相乘得到空间敏感的相似性feature,从而让MHSA关注合适区域,更加容易收敛。这一点在我的项目中也有所验证,当我使用PPYOLOv2时可能要30轮loss才会下降到50左右,而更换了BotNet loss大约5轮就可以下降到50左右。
def get_n_params(model):
pp=0
for p in list(model.parameters()):
nn=1
for s in list(p.size()):
nn = nn*s
pp += nn
return pp
class MHSA(paddle.nn.Layer):
def __init__(self, n_dims, width=38, height=38, heads=4):
super(MHSA, self).__init__()
self.heads = heads
self.query = Conv2D(512, 512, kernel_size=1)
self.key = Conv2D(512, 512, kernel_size=1)
self.value = Conv2D(n_dims, n_dims, kernel_size=1)
self.create_parameter([1,1])
self.rel_h = self.create_parameter(shape=[1,heads,n_dims // heads,1,height],default_initializer=paddle.nn.initializer.Normal(std=1e-4),dtype='float32')
self.add_parameter('rel_h',self.rel_h)
self.rel_w = self.create_parameter(shape=[1, heads, n_dims // heads, width, 1],default_initializer=paddle.nn.initializer.Normal(std=1e-4),dtype='float32')
self.add_parameter('rel_w',self.rel_w)
def forward(self, x):
n_batch, C, width, height = x.shape
q = self.query(x).reshape([n_batch, self.heads, C // self.heads, -1])
k = self.key(x).reshape([n_batch, self.heads, C // self.heads, -1])
v = self.value(x).reshape([n_batch, self.heads, C // self.heads, -1])
content_content = paddle.matmul(paddle.transpose(q,(0, 1, 3, 2)), k)
content_position = paddle.transpose((self.rel_h + self.rel_w).reshape([1, self.heads, C // self.heads, -1]),[0, 1, 3, 2])
content_position = paddle.matmul(content_position, q)
energy = content_content + content_position
attention = paddle.nn.functional.softmax(energy)
out = paddle.matmul(v, attention)
out = paddle.reshape(out,[n_batch, C, width, height])
return out
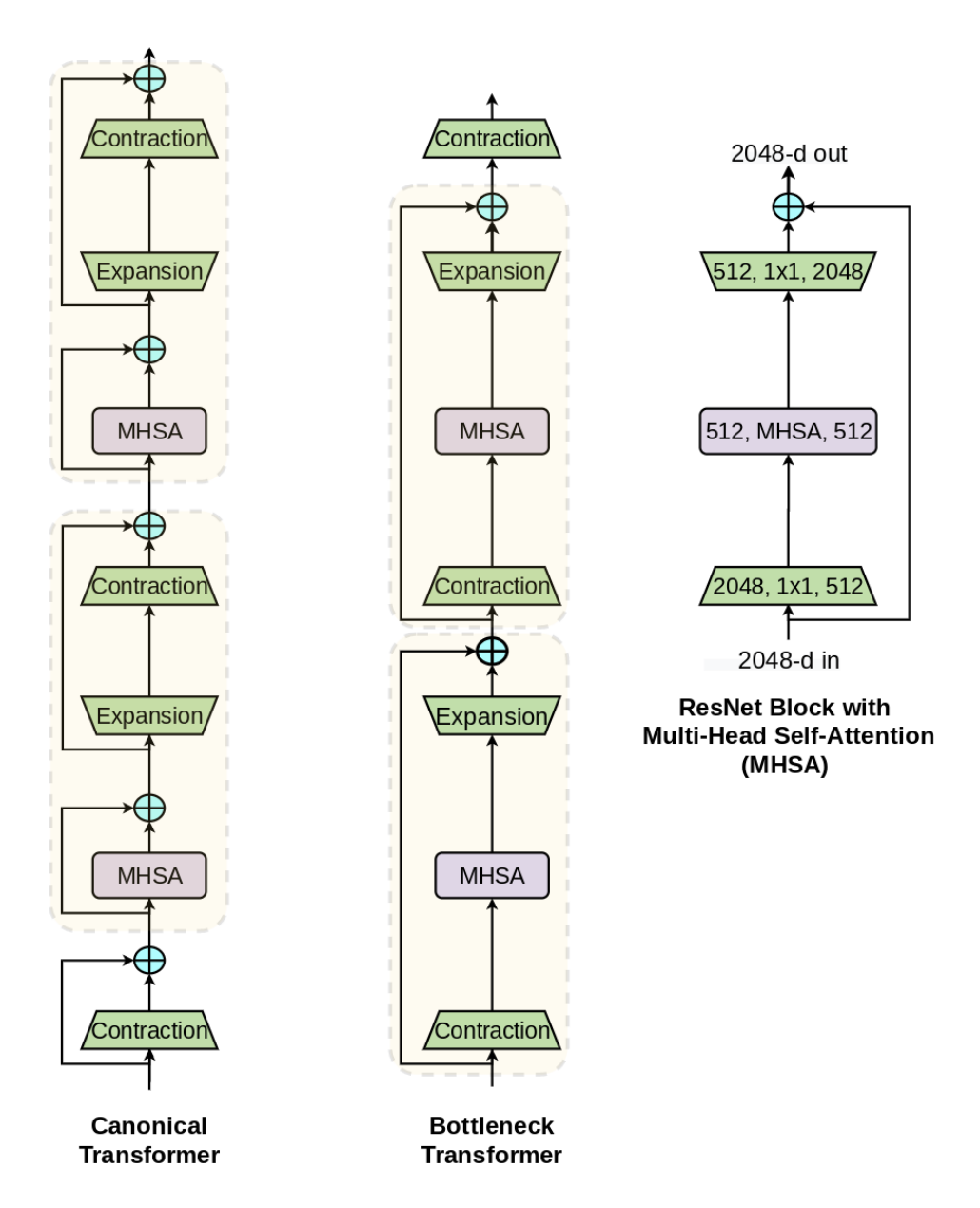
之后便如何将MHSA模块插入到Bot模块。
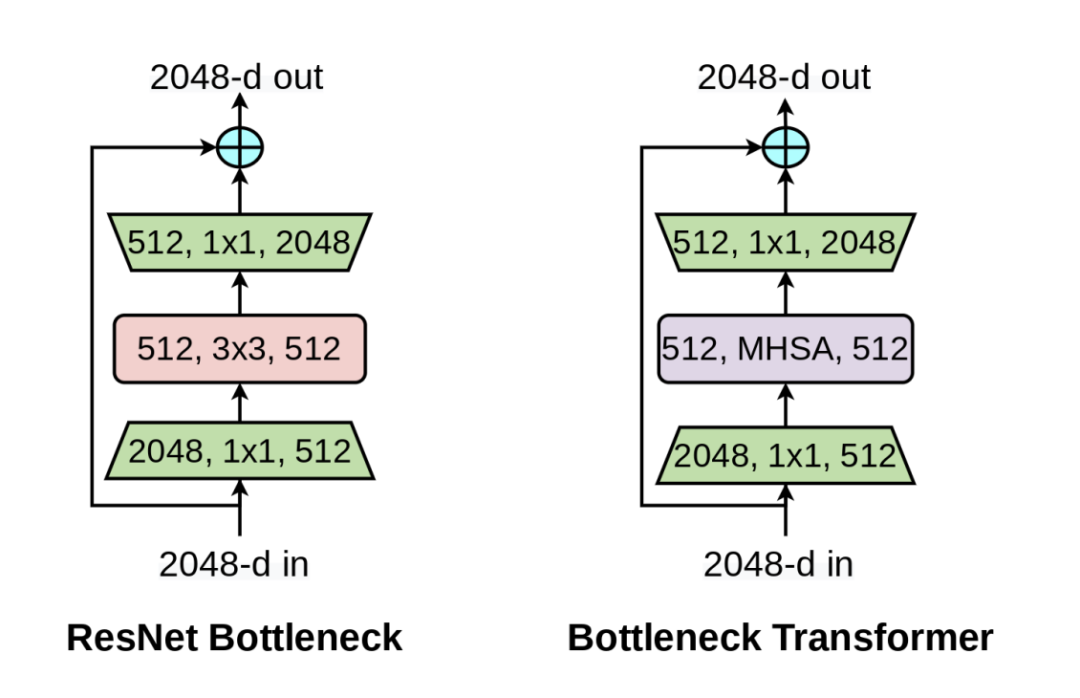
从图中我们可以看出与ResNet-50中的Bottleneck 不同的是BotNet 的Bottleneck板块将3x3的卷积块更换为更容易收敛的MHSA模块。所以对于BotNet的复现应该十分容易。
BotNet作为Backbone
应用于项目当中
前面的MHSA模块已经准备好了,接下来就是如何将BotNet作为Backbone应用于项目当中。因为我使用的是PaddleDedection,所以我一开始打算是直接从编写一个BotNet放入到PaddleDeteion.ppdet.modeling.backbones之中的。但是因为我看了三天源码也没找到他们是怎么从配置文件中读取相关配置的(别骂了别骂了),所以我就转换了一个想法,PaddleDetection中拥有一百多种模型,那么它一定就收录了很多种Backbone,那我为什么不直接找和BotNet最相近的Backbone,然后直接修改它不就好了吗。而BotNet无非就是把ResNet换了换,所以这里我对ResNet.py进行以下修改。
先将MHSA模块放入到ResNet.py中,之后就是复现Bot模块,这里阅读ResNet源码,可以看到ResNet的BottleNeck模块,就是1x1,3x3,1x1的卷积模块。只需要将3x3更换为MHSA就完成了Bottle Transformer的改造,但ResNet的BottleNeck模块是从C2到C5都发挥作用的。如果直接把3x3卷积更换为MHSA模块,那C2到C4该怎么办呢?
if x and y:
self.branch2b = paddle.nn.LayerList()
self.branch2b.append(MHSA(512, width=int(38), height=int(38), heads=4))
self.branch2b.append(paddle.nn.AvgPool2D(2, 2))
self.branch2b = paddle.nn.Sequential(*self.branch2b)
elif x and not y:
self.branch2b = MHSA(512,width=19, height=19)
else:
self.branch2b = ConvNormLayer(
ch_in=width,
ch_out=width,
filter_size=3,
stride=stride2,
groups=groups,
act='relu',
norm_type=norm_type,
norm_decay=norm_decay,
freeze_norm=freeze_norm,
lr=lr,
dcn_v2=dcn_v2)最终通过控制两个参数的形式,将branch2b模块从单纯的3x3卷积更换为开启MHSA模块加步长为二的平均池化,或只开启MHSA模块,最后依旧是3X3卷积模块。
当进入C5环节是x=1,其余环节x=0这样就能控制是开始MHSA模块还是使用3x3卷积模块,当进入C5环节第一轮时y=1,其余环节y=0这样就能控制是否启用步长为二的平均池化。由于篇幅有限这里我只说了最核心的部分,关于如何控制x,y等环节请进入《botnet:Transformer和Attention思想相遇产生的火花》项目具体观看。
项目地址:
https://aistudio.baidu.com/aistudio/projectdetail/2265776
结束语
这里我只复现了BotNet-50与101,如何复现BotNet-18,与34,就当作一个疑问让大家去思考吧,和上面的步骤类似,这里就不过多赘述。
作为一个入门深度学习不足两个月的初学者,尤其是在复现这篇论文的时候对我的挑战真的十分巨大,我是一边跑项目,一边在学习视觉方向的基础知识,从PaddleDetection里面去寻找这究竟是怎么通过配置文件去唤醒Backbone,到最后亲手把Backbone中的resnet换成botnet,一方面让我更好的了解了PaddleDetection的源码构造,另一方面也让我学会了从不同的角度思考问题,十分感谢飞桨给我这个机会在这里分享我的过程,也同样感谢郑先生,行见远大,iter等大佬,在我复现过程中给予我的帮助。
作者介绍
北京石油化工学院 信息学院 2020级 本科生 李慧涛
AI Studio主页:
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/553083
参考文献
Bottleneck Transformers for Visual Recognition:https://arxiv.org/abs/2101.11605
https://www.zhihu.com/question/442344643/answer/1744876036
长按下方二维码立即
Star

更多信息:
飞桨官方QQ群:793866180
飞桨官网网址:
www.paddlepaddle.org.cn/
飞桨开源框架项目地址:
GitHub:
github.com/PaddlePaddle/Paddle
Gitee:
gitee.com/paddlepaddle/Paddle
点击阅读原文,欢迎在飞桨论坛讨论交流~~
END