被认定为“上线一个月以来收益最多的手游”
“最快取得1亿美元收益的手游(耗时20天)”
“上线一个月后下载次数(约1.3亿次)”
“上线一个月后在最多国家下载次数排行第一(约70多个国家)”
“上线一个月后的收益额在最多国家排行第一(约55个国家)”
项目背景
方案概要
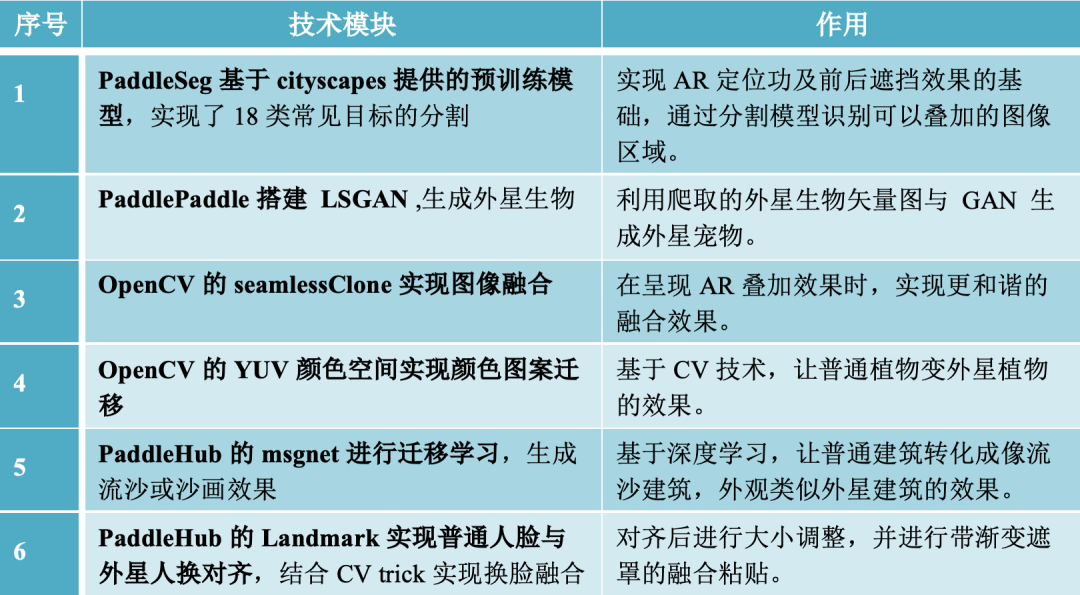
方案主要模块
本文介绍的内容及代码均可在下面项目中获取:
https://github.com/kevinfu1717/SuperInterstellarTerminal
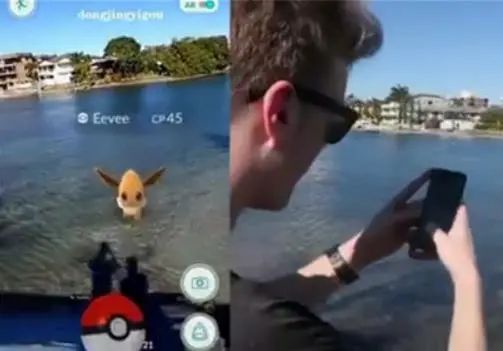
微信聊天机器人互动展示gif,在微信中体验AR寻找外星人:

技术实现
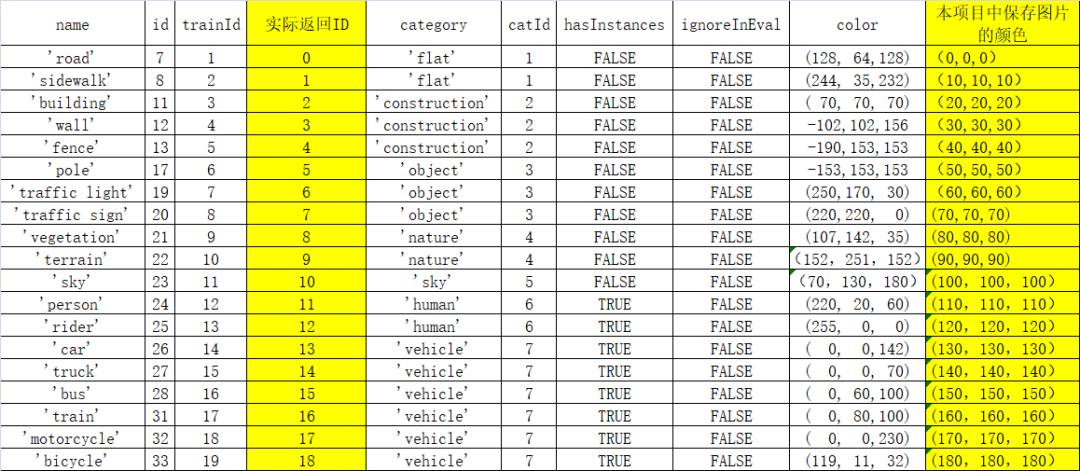
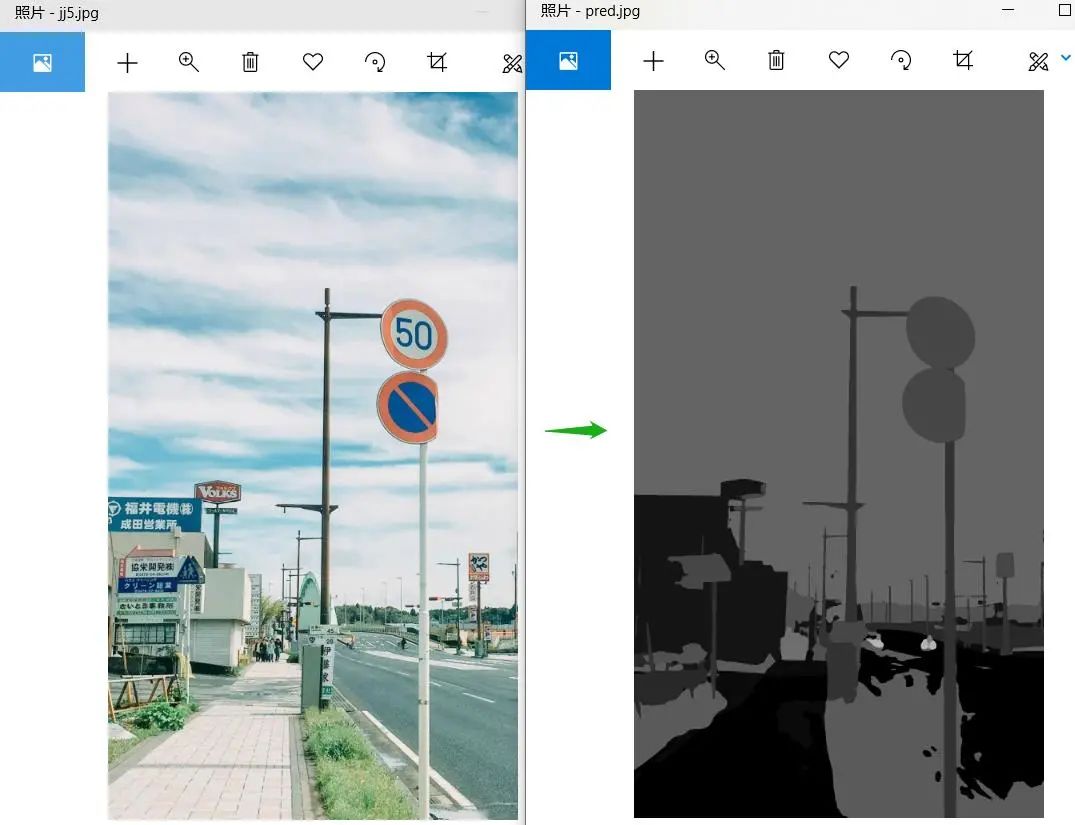
1 识别图片中的环境
├── CityscapesModule.py
└── PetModel
├── modelCityscape.pdparams
├── pretrainedCityscape.pdparams
└──mscale_ocr_cityscapes_autolabel_mapillary_ms_val.yml#把图片送入cistyScaperClass中的run,即可获取分割图
def run(self,image):
pred=[]
try:
t1=time.time()
## 前处理
im,ori_shape=preProcess(image,self.transforms)
print('seg time',time.time()-t1)
t2=time.time()
with paddle.no_grad():
## 预测 并进行后处理(如:转换回原图的尺寸)
pred = infer.inference(
self.segModel,
im,
ori_shape=ori_shape,
transforms=self.transforms.transforms,)
pred = paddle.squeeze(pred)
pred = pred.numpy().astype('uint8')
print('seg time',time.time()-t2)
except Exception as e:
print(e)
return self.resultCode[7],pred
#pred为结果,是一个二维数组,该数组尺寸与原图一样,每个像素的值对应类别,从0~17类
return self.resultCode[4],pred
2 LSGAN生成外星生物

2.1. GAN的训练图片:

2.2. 数据增广:
尝试过用midars模型或CV来提取单个外星生物,但效果都不是很好。所以,最终只使用水平翻转,增加了一倍的数量。尽管可以通过爬取来增加数量,但越到后面,爬取的图片越杂乱,而且没有相关性。所以还是通过水平翻转来处理。
最终训练使用3000多张图片,经水平翻转增广后,投入训练的有6000多张。
后续与PaddleGAN方向的工程师进行沟通。他们给了几个不错的建议可进行尝试:
2.3. 模型训练
1. 训练模型选用LSGAN,可能StyleGAN V2效果会更好,大家可以在PaddleGAN中尝试直接尝试StyleGAN V2模型。
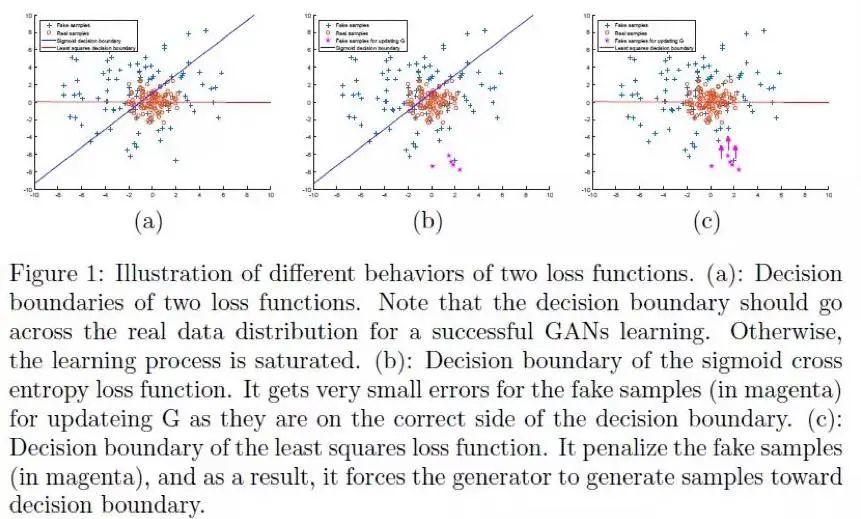
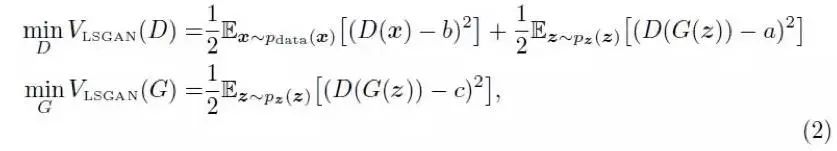
LSGAN模型的搭建基于AI Studio上的项目通过LSGAN以及WGAN-GP实现128*128大小的喀纳斯风景图片 。在其基础上,每个Epoch执行更多的Generation,以及修改了其中的超参数。

因GAN直接生成的图片效果还不完美,我们把其叠加到现实图像中做AR效果时,使用cv处理优化这部分,如:开闭运算,seamlessclone时设置不同的参数等,去掉周围的杂色。
https://aistudio.baidu.com/aistudio/datasetdetail/103316
https://aistudio.baidu.com/aistudio/projectdetail/2210138?shared=1
3 AR效果叠加(外星宠物)

实现对应位置的叠加AR效果。如:天空中出现飞在天上的外星飞碟或外星生物,树丛中会出现喜欢在树上的草食性外星生物。基于分割模型得到图像中对应事物mask区域,例如哪里是天空,哪里是人行道,按照外星生物可存在的位置判断是否出现外星生物,及其出现位置。
# 会把src图的边缘进行模糊化,同时整个src图的色彩融合到dst中->需要src图较清晰,dst背景较简单,可以接受src图周边边缘模糊的场景
cv2.seamlessClone(src, dst, src_mask, center, cv2.NORMAL_CLONE)
# 基于透明度的融合,src图中白色的区域会显得透明度高,看起来叠加的颜色比较透->适合dst背景较复杂,但对src图清晰度要求不高,src图背景是白色的场景
cv2.seamlessClone(src, dst, src_mask, center, cv2.MIXED_CLONE)
# 会把src图变成灰度图合成到dst中->暂时看不到什么好用途
cv2.seamlessClone(src, dst, src_mask, center, cv2.MONOCHROME_TRANSFER)


4.结合mask的优化版seamlesClone图像合成效果
4 外星人换脸
实现过程:
https://github.com/PaddlePaddle/PaddleHub/tree/release/v2.1/modules/image/keypoint_detection/face_landmark_localization
3. 对用户发来的图片,利用PaddleHub的landmark模型获取图片中的人脸特征点。判断是正脸还是侧脸,根据正脸或侧脸使用对应的外星人照片。若角度太偏则不进行处理。然后,使用landmark中脸颊的特征点求中点进行人脸图像位置上的对齐。并根据用户图片的人脸对外星人人脸进行大小调整。
截取外星人人脸,生成一个上到下的渐透明的遮罩图。用cv2.seamlessCloned的NORMAL_CLONE复制到原人脸位置,但因为seamlessClone没法调参数的,外星人形象融在背景里面,不太明显不清晰。

直接把外星人脸贴到用户图上边缘会很硬,如上图中的左图。项目中,还用了双重叠加方式,使外星人脸融合更佳自然,具体方法及代码请见项目。
5 外星植物——基于非深度学习的颜色图案迁移

实现过程:
# 把图片style,content转到yuv空间
yuv = cv2.cvtColor(np.float32(style), cv2.COLOR_BGR2YUV)
y, u, v = cv2.split(yuv)
yuv2 = cv2.cvtColor(np.float32(content), cv2.COLOR_BGR2YUV)
h, j, k = cv2.split(yuv2)
# 根据ratio这个比例来合成 style 与 content两张图
hy = np.array((h * ratio + y * (1 - ratio)), 'uint8')
# hy = np.clip(hy, 0, 255)
# 两张图进行合成
content = np.dstack((hy, u, v))
content = cv2.cvtColor(np.float32(content), cv2.COLOR_YUV2BGR)
6 外星建筑——基于深度学习的风格迁移

风格迁移:
训练:
checkpoint='/home/aistudio/model/msgnet/style_paddle.pdparams'
model = hub.Module(name='msgnet',load_checkpoint=checkpoint)
print(type(model),' parameters nums:',len(model.parameters()))
##
for index,param in enumerate(model.parameters()):
# model的前25层设置成不进行梯度更新
if index>25:
param.stop_gradient=False
else:
param.stop_gradient=True
optimizer = paddle.optimizer.Adam(learning_rate=0.0001, parameters=model.parameters())
trainer = Trainer(model, optimizer,use_gpu=True,use_vdl=True, checkpoint_dir='test_style_ckpt')
trainer.train(styledata, epochs=65, batch_size=32, eval_dataset=None, log_interval=10)
使用:
总结
长按下方二维码立即
Star

更多信息:
飞桨官方QQ群:793866180
飞桨官网网址:
www.paddlepaddle.org.cn/
飞桨开源框架项目地址:
GitHub:
github.com/PaddlePaddle/Paddle
Gitee:
gitee.com/paddlepaddle/Paddle
欢迎在飞桨论坛讨论交流~~
http://discuss.paddlepaddle.org.cn