在CV领域,CNN一直是各个技术方向最主流的算法,卷积由于其具有局部连接和权重共享的特性,取得了很好的效果。随着Transformer技术在自然语言处理领域取得了丰硕的成果,CV领域也开始尝试将Transformer 技术用于处理图像和视频信息。从2020年的ViT开始,图像分类、目标检测、视频分割等多个技术方向的研究人员都在探索如何将Transformer 技术在NLP中取得的成功借鉴到CV领域,并已经取得了一定的成果。
本期我们将展现Transformer类模型实现的4款CV案例实践,包括图像分类、目标检测和视频分类。如果你对这些内容感兴趣,赶快来一起学习吧。
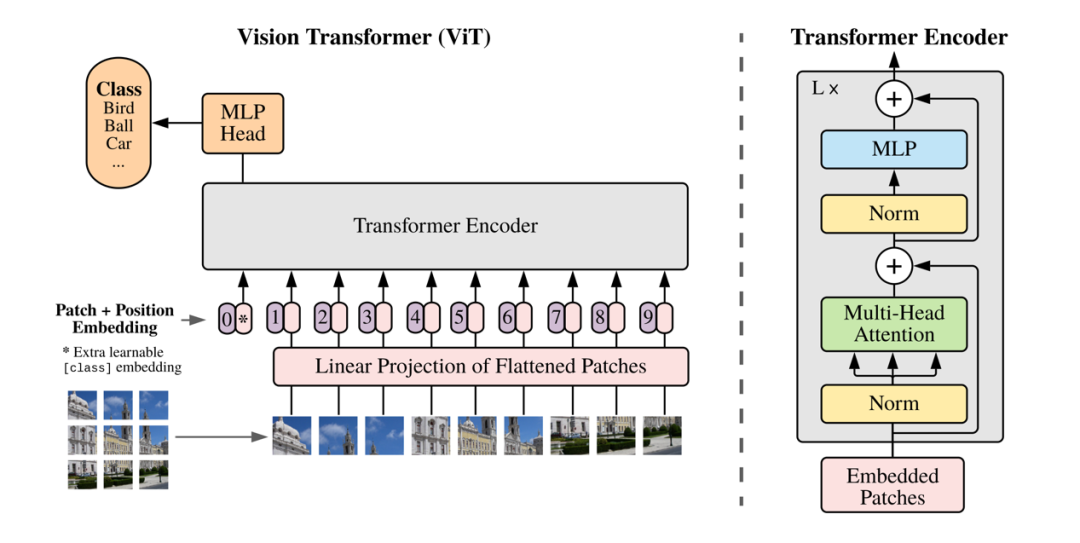
在计算机视觉领域,ViT之前的算法大都是保持CNN整体结构不变,在CNN中增加attention模块或者使用attention模块替换CNN中的某些部分。ViT首次提出没有必要总是依赖于CNN,仅仅使用Transformer结构也能够在图像分类任务中表现很好。
ViT算法尝试将标准的Transformer结构直接应用于图像分类任务,并对整个图像分类流程进行最少的修改。具体来讲,就是将整幅图像拆分成小图像块,然后把这些小图像块的线性嵌入序列作为Transformer的输入送入网络,然后使用监督学习的方式进行图像分类的训练。
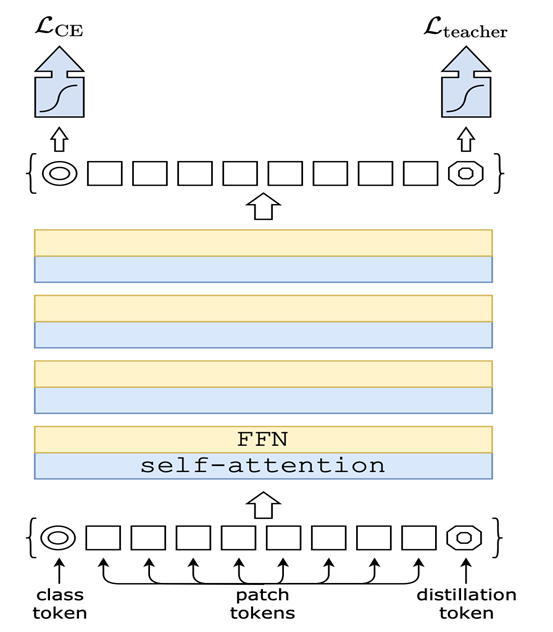
但是ViT 算法要想取得一个较好的指标,需要先使用超大规模数据集进行预训练,然后再迁移到其他中等或较小规模的数据集上。因此,训练一个这样的网络需要非常昂贵的计算资源。出于这个背景,研究者针对 ViT 算法进行了改进,提出了DeiT。
在 DeiT 中,作者在 ViT 的基础上改进了训练策略,并使用了蒸馏学习的方式,只需要在 ImageNet 上进行训练,就可以得到一个有竞争力的 Transformer 模型,而且在单台计算机上,训练时间不到3天。
本项目会先从ViT开始介绍,详细讲解ViT的算法背景、网络结构以及实现细节。然后针对ViT的不足,详细介绍DeiT的优化策略以及对应的一系列对比实验。最后,通过在ImageNet上的模型评估实验,进行实际效果验证。
项目维护者:PaddleEdu
主要框架/工具组件:飞桨PaddlePaddle核心框架,PaddleClas套件
项目链接:
https://aistudio.baidu.com/aistudio/projectdetail/2293050
Swin Transformer
从理论到实现
将自然语言处理领域的Transformer技术应用到计算机视觉领域主要的领域差异有:
视觉实体的尺度变化较大,Transformer里面token大部分都是一个固定的尺寸;
相比于文本中的单词,图像的像素分辨率较高。Transformer基于全局自注意力的计算导致计算量较大,需要image size平方的时间复杂度,代价很高。
Swin Transformer模型的提出解决了NLP和Vision两个领域的上述差异:
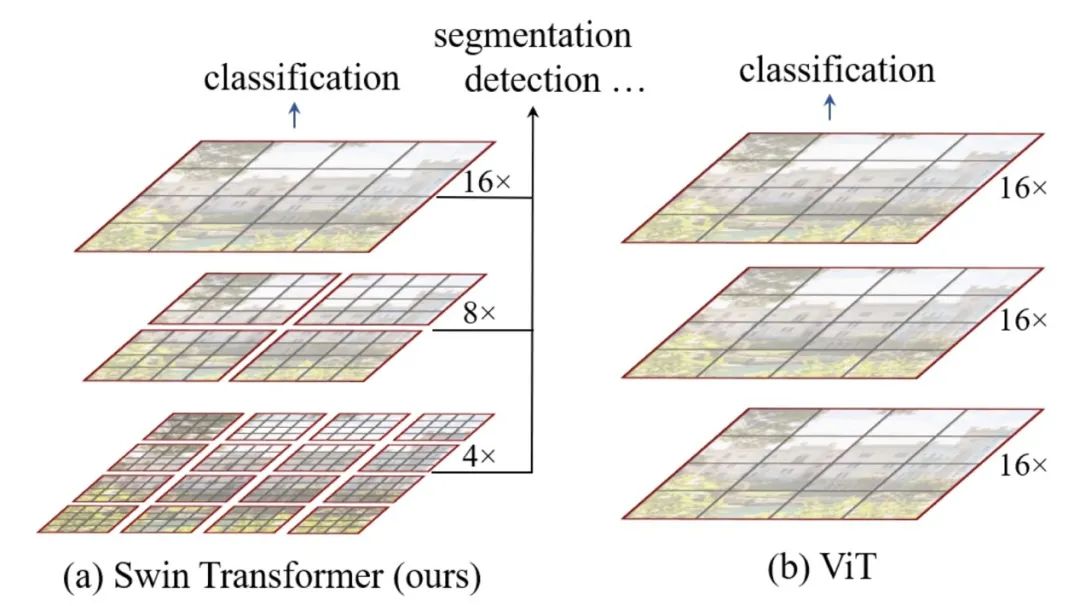
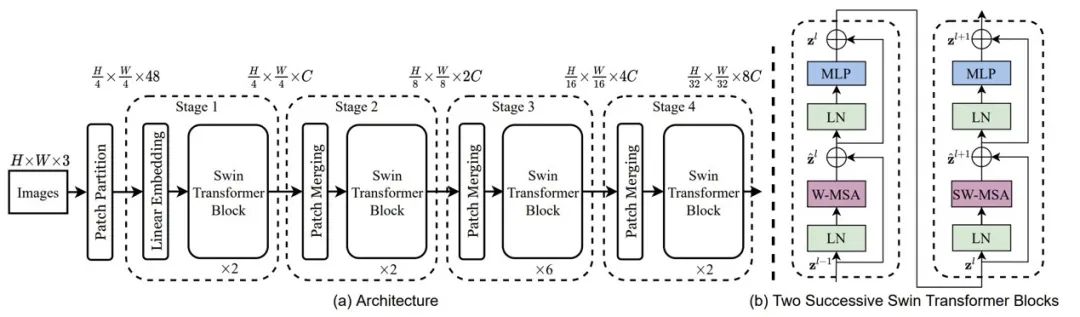
引入类似于CNN的层次化构建方式构建Transformer模型;
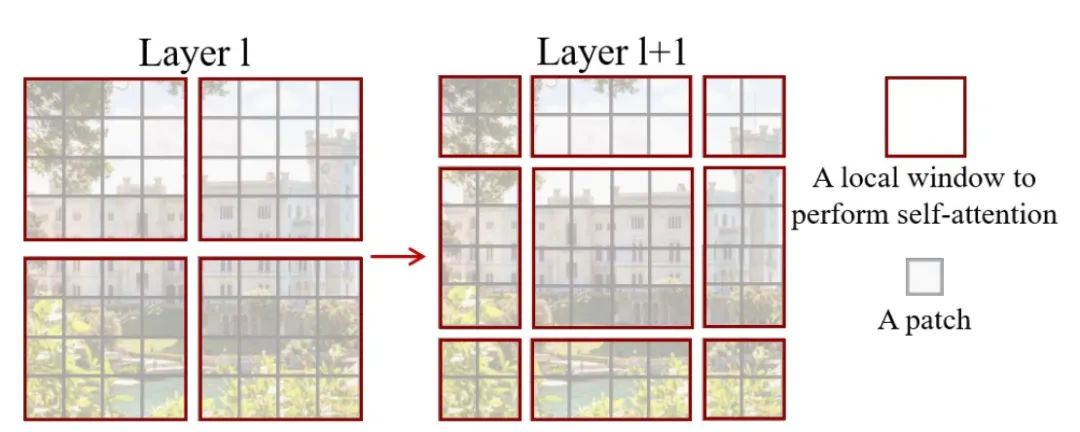
引入locality思想,对无重合的window区域进行单独的self-attention计算。
下图展示了Swin Transformer多层级表示和ViT对比:
Swin Transformer的移动窗口策略将自注意力计算限制在不重叠的局部窗口,同时还允许跨窗口连接,从而达到效率提升的目的。
SwinTransformer模型架构如下图所示:
本项目为大家介绍了Swin Transformer的主要创新点以及对应的具体代码实现,最后以ImageNet的模型评估为例介绍如何应用Swin Transformer进行图像分类。
项目维护者:PaddleEdu
主要框架/工具组件:飞桨PaddlePaddle核心框架,PaddleClas套件
项目链接:
https://aistudio.baidu.com/aistudio/projectdetail/2280436
Transformer模型DETR
在目标检测任务中的应用
DETR(Detection Transformer)是Facebook AI 的研究者提出的 Transformer 的视觉版本,可以用于目标检测,也可以用于全景分割。这是第一个将Transformer成功整合为检测pipeline中心构建块的目标检测框架。
与之前的目标检测方法相比,DETR有效地消除了对许多手工设计的组件的需求,例如非最大抑制(Non-Maximum Suppression,NMS)程序、锚点(Anchor)生成等,结果在COCO数据集上效果与Faster RCNN相当,且可以很容易地将DETR迁移到其他任务例如全景分割。
本项目先带领大家解读DETR的基本原理,然后剖析DETR在目标检测上的应用,最后讲解基于DETR的目标检测的代码实践,即在数据集COCO上训练一个模型、并进行评估和测试,以此进行实际效果验证。
项目维护者:PaddleEdu
主要框架/工具组件:飞桨PaddlePaddle核心框架,PaddleDetection套件
项目链接:
https://aistudio.baidu.com/aistudio/projectdetail/2290729
Transformer在
视频分类中的应用
TimeSformer是FacebookAI于2021年提出的无卷积视频分类方法,该方法使用ViT网络结构作为骨干网络,提出时空自注意力机制,以此代替了传统的卷积网络。与图像只具有空间信息不同,视频还包含时间信息,因此TimeSformer对一系列的帧级图像块进行时空特征提取,从而适配视频任务。
TimeSformer在多个行为识别基准测试中达到了SOTA效果,其中TimeSformer-L在Kinetics-400上达到了80.7的准确率,超过了经典的基于2D CNN的视频分类模型TSN、TSM及SlowFast,而且训练用时更短。与3D卷积网络相比,TimeSformer的模型训练速度更快,拥有更高的测试效率,并且可以处理超过一分钟的视频片段。
本项目会先为大家详细介绍TimeSformer 模型,再通过一个实验案例,带领大家使用飞桨2.1版本在UCF101数据集上实现基于TimeSformer模型的视频分类,同时对训练好的模型进行评估和预测,以此进行实际效果验证。
项目维护者:PaddleEdu
主要框架/工具组件:飞桨PaddlePaddle核心框架,PaddleVideo套件
项目链接:
https://aistudio.baidu.com/aistudio/projectdetail/2291410
了解更多
更多Transformer类模型在CV领域的理论及实践内容,欢迎访问下方链接查看。上述案例使用过程中如有任何问题,可以点击阅读原文提issue,或者扫描下方二维码加入QQ群交流,目前已有2300+同学一起学习。
合集地址:
https://aistudio.baidu.com/aistudio/projectdetail/2277159
长按下方二维码立即
Star

更多信息:
飞桨官方QQ群:793866180
飞桨官网网址:
www.paddlepaddle.org.cn/
飞桨开源框架项目地址:
GitHub:
github.com/PaddlePaddle/Paddle
Gitee:
gitee.com/paddlepaddle/Paddle
欢迎在飞桨论坛讨论交流~~
http://discuss.paddlepaddle.org.cn