轻量级文字识别技术创新大赛是第二届CSIG图像图形技术挑战赛赛题之一,由百度公司承办。本赛题以文字识别为主题,要求参赛选手建立轻量级OCR模型,在兼顾准确率指标与模型大小的同时,重点考察选手的网络结构设计与训练调优能力,进一步推动中文场景文字识别算法与技术的突破。
赛题回顾:
https://aistudio.baidu.com/aistudio/competition/detail/75
OCR文本识别任务作为计算机视觉领域的核心问题之一,旨在找出图像中所有的文字信息,进而确定它们的位置和内容。由于文字有不同的外观、形状、尺度和姿态,加上成像时的光照、遮挡等因素干扰,OCR文本识别一直是计算机视觉领域极具挑战性的问题之一,但是在现实世界中又具有庞大的应用基础。
对于一个机器学习任务,数据和模型是取得良好结果的两大关键因素,本次轻量级文本识别大赛也不例外。除此之外,还需要考虑实际应用场景的条件和限制对方案进行调整优化。
数据分析
本次赛题数据集共包括12万张真实图片,其中10万张图片作为训练集,A榜,B榜各1万张图片作为测试集。在实验过程中,我们将官方给到的原始训练集进一步做了9:1划分,得到包含9万张图片的新训练集和1万张图片的新验证集。
表1
数据集 |
图片数 |
总文本数(不包含空格) |
总文本数 |
字典容量 |
|---|---|---|---|---|
Train |
90000 |
487249 |
492992 |
3908 |
Val |
10000 |
54643 |
55255 |
2516 |
Trainval |
100000 |
541892 |
548247 |
3972 |
表2
字符出现次数 |
1000+ |
100-1000 |
10-100 |
1-10 |
1 |
|---|---|---|---|---|---|
Trainval |
99 |
828 |
1262 |
1115 |
668 |
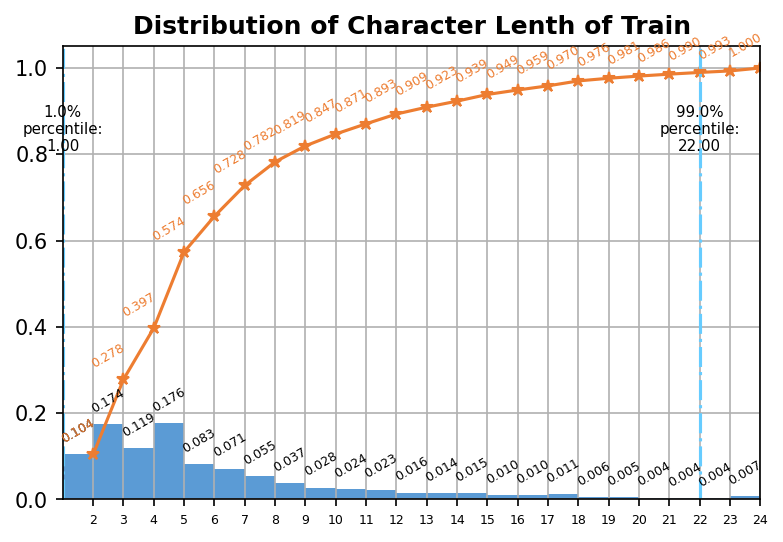
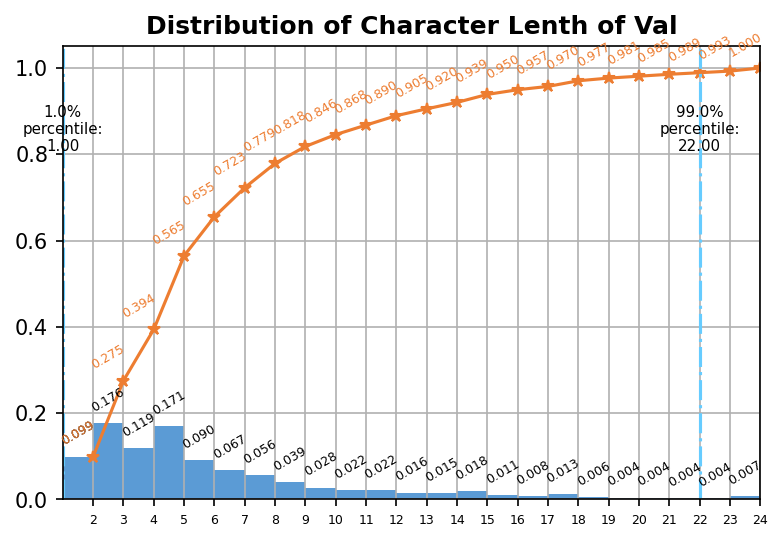
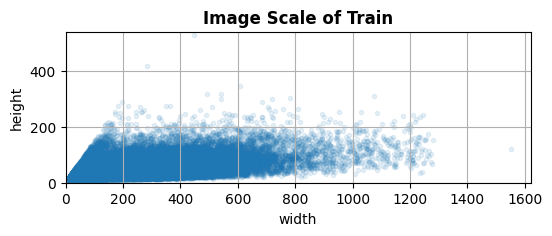
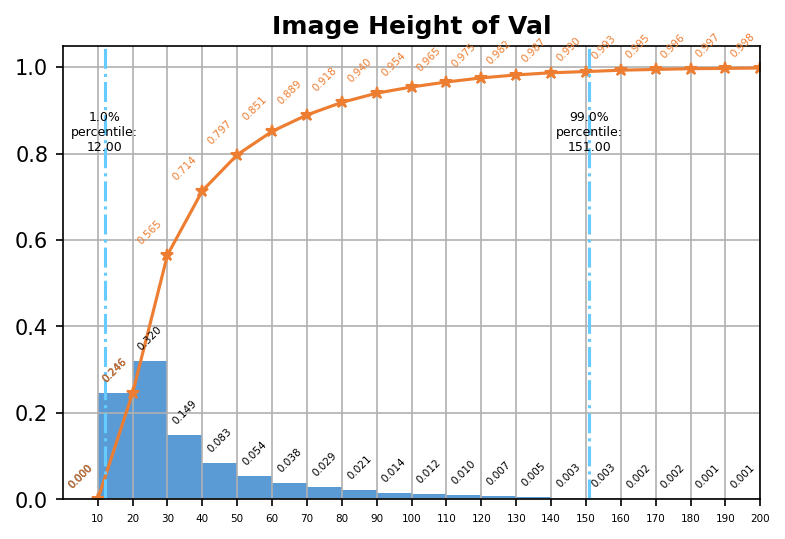
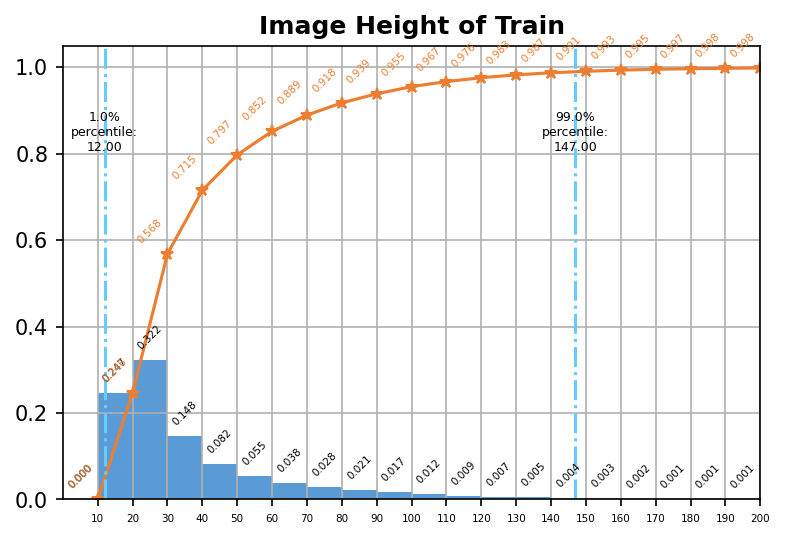
我们对数据量进行了分析,分析结果如表1所示。对于中文文本识别任务来说,10万张图片,50万字符量是相对较少的。此外,我们发现新训练集与原始训练集之间的字典容量也有一定差距,于是我们进一步分析了这批数据的字频分布,如表2所示。可以看到,接近一半的字符出现的次数小于10次,因此我们认为合理且充分的数据增强对本次任务十分重要。进一步地,我们还分析了本次数据集的字符长度分布,图像尺寸分布等统计信息,如下图所示。
字符长度分布
图像尺寸分布
赛题分析与整体思路
本次大赛的任务为中文文字识别,除去OCR任务的通用目标外还有以下两点限制:1、模型总大小不超过10MB;2、仅可使用比赛提供数据进行训练,不允许使用预训练模型以及其他数据集(包括离线合成数据)进行训练。
对于本次任务,我们的思路如下:
站在巨人的肩膀上:对于当前任务,目前已有较为成熟的PaddleOCR方案(http://github.com/PaddlePaddle/PaddleOCR/blob/release/2.2/README_ch.md ),与其另起炉灶,不如利用现成的资源对这个任务进行针对性的优化;
解耦合与控制变量:将可能需要进行实验的模块进行解耦,并且每次实验只改变一个变量;
Tick-Tock策略:Tick:根据现有结论将所有有效策略应用于当前对照组作为下一批实验新的对照组;Tock:基于当前对照组进行ablation study获取新的有效策略。这是因为在实验过程中,我们很难确保基于当前对照组得到的结论在进行较大调整后是否依然有效,同时,这种方式也有利于我们并行实验,有利于在短时间内得到较为理想的组合。
先优化指标,再做小模型:模型大小与最终指标往往是互相矛盾的,鱼和熊掌难以兼得,与其在两手抓的过程中顾此失彼,不如拆分步骤逐个击破。
模型优化
选择字典:本任务的字符集与百度默认字符集互有交叠又不互相包含,故我们以本数据集所需字符为准;
不训练空格:是否训练空格是OCR任务常常需要考虑的问题,我们通过实验发现,本任务计算最终指标时无需考虑空格问题,则将' '、'\u3000'字符移出训练范围;
周期化的训练策略:考虑到单个模型训练周期较长,且较难判别合适的epoch数,我们选择对learning rate进行周期化的重启以得到及时的结果反馈,同时这也有利于我们选择更合适的训练时长;
移除数据增强模块:baseline默认的数据增强可能不一定适合本任务,如果需要进一步探索的话,就有必要将其进行足够细粒度的拆分,因此我们暂时将这部分模块移除;
降低模型尺寸限制的优先级:考虑到调研与实验结果和后续做小模型的可能性,我们选择基于MobileNetV3最大尺度+较宽的BiLSTM来做进一步的优化;
适宜的常见超参:batchsize、学习率、GPU数、优化器超参等。在这个阶段我们的目标是排除模型优化过程中可能存在的障碍,保证实验过程中模型对于训练集的过拟合。
在这个阶段,我们基于色彩、噪声、几何形变、图像尺度这几个因素对数据增强的方法进行了分类,将其中的每一个类别作为一个tick,得到该类别下较为合理的增强方法并融合为一个tock,以这种方式组合得到最终使用的数据增强组合。我们尝试的方法包括:
色彩:色彩抖动、随机反色等;
噪声:高斯模糊、运动模糊、高斯噪声、Cutout等;
几何形变:行切除、TIA、旋转、缩放等;
图像尺度:其他输入尺寸、多尺度等。
class Imau:
def __init__(self, transforms, **kwargs) -> None:
self.transforms = transforms
self.augmenter = iaa.Sequential(
[self.imau_builder(t) for t in self.transforms]
)
def imau_builder(self, cfg: dict) -> iaa.Augmenter:
assert isinstance(cfg, dict) and 'typename' in cfg
args = cfg.copy()
obj_type = args.pop('typename')
if isinstance(obj_type, str):
obj_cls = getattr(iaa, obj_type)
else:
raise TypeError(
f'typename must be a str, but got {type(obj_type)}')
for k in ['transforms', 'children', 'then_list', 'else_list']:
if k in args:
args[k] = [self.imau_builder(t) for t in args[k]]
return obj_cls(**args)
def __call__(self, data):
image = data['image']
if self.augmenter:
aug = self.augmenter.to_deterministic()
data['image'] = aug.augment_image(image)
return data
def __repr__(self):
repr_str = self.__class__.__name__ + f'(transforms={self.transforms})'
return repr_str
# modified from mmdet
# https://github.com/open-mmlab/mmdetection/blob/master/mmdet/datasets/pipelines/transforms.py
class Albu:
def __init__(self, transforms, **kwargs) -> None:
self.transforms = transforms
self.aug = Compose([self.albu_builder(t) for t in self.transforms])
def albu_builder(self, cfg: dict) -> albu.BasicTransform:
assert isinstance(cfg, dict) and 'typename' in cfg
args = cfg.copy()
obj_type = args.pop('typename')
if isinstance(obj_type, str):
obj_cls = getattr(albu, obj_type)
else:
raise TypeError(
f'typename must be a str, but got {type(obj_type)}')
if 'transforms' in args:
args['transforms'] = [
self.albu_builder(transform)
for transform in args['transforms']
]
return obj_cls(**args)
def __call__(self, data):
data = self.aug(**data)
return data
def __repr__(self):
repr_str = self.__class__.__name__ + f'(transforms={self.transforms})'
return repr_str
解决过拟合:当新训练集拟合效果很好时,新验证集指标依旧较低——Dropout、Dropout2D、调整FC正则化项、Multi-Scale等;
提高模型容量:考虑到模型容量受参数量限制较大,我们尝试通过一些成本较低(参数增量小)的方法提升模型容量——SE模块、ResNetV1D的残差块、更复杂的激活函数、多尺度feature融合、其他策略的downsample(AdaptivePool、Max/MeanPool)等;
从感受野角度优化:当前的模型如不考虑sequence模块,其横向只在backbone最初及最终进行了下采样,特征感受野过小——增加宽度方向的下采样次数、增加池化层的kernel size等。
最后,我们将得到的模型方案通过收窄backbone与neck的通道宽度,将模型文件压缩到9.5M,得到最终方案。
方案总结
数据
增强:
行切除(HeightRatioCrop), ratio∈[0, 0.05], p=0.5
Cutout, ratio∈[0, 0.05], p=0.5, num∈[1, 3], size∈[0.05, 0.1], mode=constant, value∈[0, 255]
TIA, p=0.4
AdditiveGaussianNoise, scale∈[0, 10], p=0.5
MotionBlur, k∈[3, 7], p=0.5
ColorJitter, p=0.5
清洗:为专注于更为普适的模型优化、避免不公平竞争,我们不对原始数据进行诸如人工过滤、其他完备模型过滤等操作。
我们使用的模型与经典的CRNN算法结构一致,其中:
Backbone采用的是scale=0.6的MobileNetV3(large), 并且做了如下改进:
在backbone的C2层增加一次对宽度的下采样;
在backbone的最后一层pool根据输入图像尺寸的大小将配置改成了kernel_size=3,stride=3;
在backbone的C5阶段加入了基于课程学习的Dropout2D。
Neck使用了hidden_size=64的BiLSTM
Head中的fc层加入了Dropout
具体配置如下:
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
name: CyclicalCosine
learning_rate: 0.004 # 4 gpus
cycle: 50
eta_min: 0.00001
regularizer:
name: 'L2'
factor: 0.00001
Architecture:
model_type: rec
algorithm: CRNN
Transform:
Backbone:
name: MobileNetV3
scale: 0.6
model_name: large
large_stride: [[1,1], [2,2], [2,1], [2,1]] # 在backbone的C2层多做了一次对宽度的下采样
last_pool: # backbone最后一层pool的配置
type: max
kernel_size: 3
stride: 3
padding: 0
dropout_cfg: # 在backbone中做spatial dropout
start_epoch: 200
final_p: 0.1
start_block_idx: 12 # 12 for large:C5
curr_finish_epoch: 1000 # p=0.1 at 1000 epoch
Neck:
name: SequenceEncoder
encoder_type: rnn
hidden_size: 64
Head:
name: CTCHead
fc_decay: 0.00004
dropout:
p: 0.1
Loss:
name: CTCLoss
PostProcess:
name: CTCLabelDecode
基于以上改进,得到的模型在比赛A/B榜上的表现如下:
Accuracy |
A榜 |
B榜 |
|---|---|---|
Untitled |
0.8159 |
0.8170 |
一些感想
在本次比赛任务中,我们学到的一个很重要的经验是过拟合的重要性。为什么过拟合很重要?我们认为,当前的很多方法将训练周期限制在一定的epoch数,而不考虑模型在训练集上的拟合效果,这是存在一定问题的。如果说一个模型在训练集上尚不能过拟合,从何谈起在验证集/测试集上的效果呢?举例来说,在本任务中,我们使用准确率作为验证模型过拟合效果的代理,这里需要明确的是,我们需要同时考虑训练集的在线准确率与离线准确率,两者的主要区别如下表:
MAE |
离线准确率 |
在线准确率 |
|---|---|---|
数据增强 |
否 |
是 |
BN的均值方差 |
基于滑动平均 |
基于当前batch统计 |
当训练集的离线准确率较低时,我们对模型的优化可能存在这几个方面的问题:1.模型容量不足;2.模型尚未收敛;3.模型设计不合理。这时,就需要设计实验验证到底是哪里出了问题。而当训练集的离线准确率较高,在线准确率较低时,更可能是我们的数据增强出了问题,我们便可以据此进行下一步分析和实验。因此,对训练集的过拟合本质上是解耦思想的一个体现,当我们把问题拆分得足够细,便能将其各个击破。
细节是一个老生常谈的问题,即使站在巨人的肩膀上,我们也需要考虑,巨人在哪座山上以哪一个站姿能看得很远,但是如果换了座山,原先的姿势是否还是最好的呢?例如数据增强中对图像尺度的调整和添加模糊数据增强的先后顺序:在PaddleOCR的超轻量模型配置中,默认将模糊增强放在Resize之前,而我们在初期实验中对数据增强后的图像进行肉眼检验和实际训练的对比试验,发现:1. 模糊的强度是与图像尺寸相关的,同样的模糊核放在大图中效果区别甚微,但在小图中可能会导致字符无法被肉眼辨别;2. 模糊之后的高斯噪声显得很不自然,实验也证明将其放在噪声之后确实有提升。
最后,我们开源了本次实验使用的代码,更多细节可以参考:
https://github.com/YuxinZou/Ultra_light_OCR_No.4
长按下方二维码立即
Star

更多信息:
飞桨官方QQ群:793866180
飞桨官网网址:
www.paddlepaddle.org.cn/
飞桨开源框架项目地址:
GitHub:
github.com/PaddlePaddle/Paddle
Gitee:
gitee.com/paddlepaddle/Paddle
欢迎在飞桨论坛讨论交流~~
http://discuss.paddlepaddle.org.cn