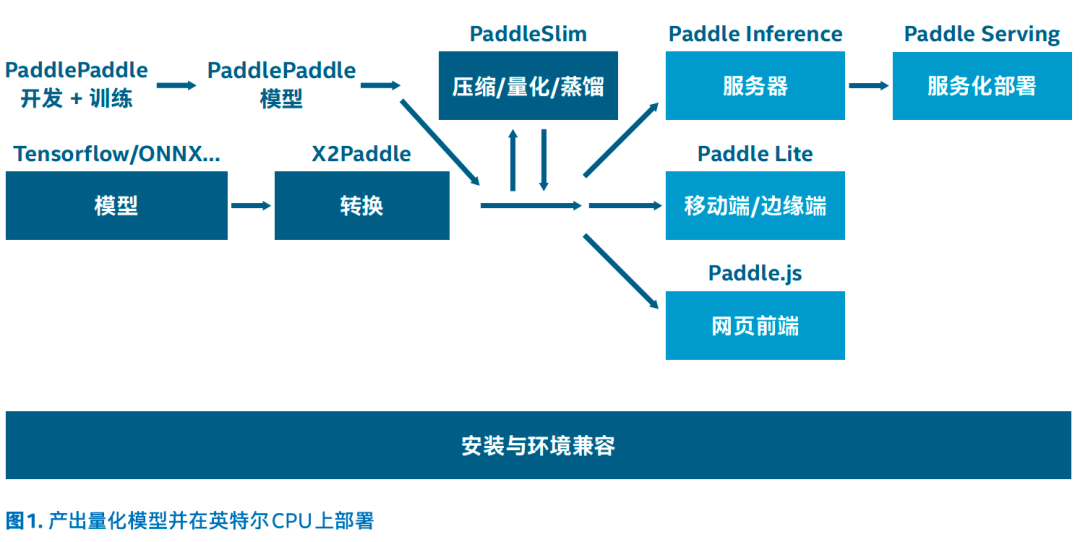
在飞桨深度学习平台之上,针对模型训练阶段,我们为开发者提供了非常丰富的产业级的开源模型库和开发套件,支持超300个经过产业实践长期打磨的主流模型并提供了涵盖各领域的预训练模型和开发组件,依托于这些能力开发者可以快速完成从数据处理、模型训练到方案验证的前期流程;同时我们也支持将其他框架和模型格式通过X2Paddle导入至飞桨框架中,尽可能避免模型二次开发的成本。
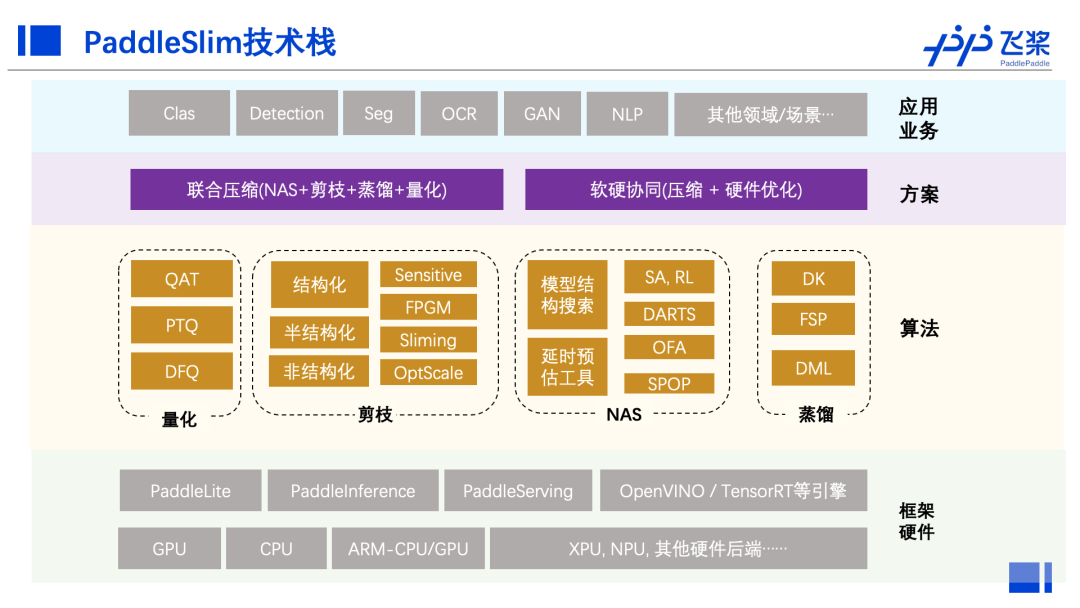
在模型优化阶段,PaddleSlim提供了包含模型剪裁、定点量化、知识蒸馏、超参搜索和神经网络结构搜索(NAS)等一系列模型压缩策略;最新升级的PaddleSlim 2.0在静态图的基础上,还推出了动态图支持功能;同时PaddleSlim还引入了软硬协同策略,来结合硬件特点针对性进行模型优化。
而针对模型优化和部署阶段,飞桨深度学习平台内有面向不同场景的多个高性能推理引擎Paddle Inference、 Paddle Lite以及Paddle.js供开发者选择, 而Paddle Serving则使便捷高效的服务化部署成为了可能。
在以上流程中,结合PaddleSlim的模型量化能力以及英特尔®量化相关技术的加持,我们即可以在英特尔CPU上部署并加速飞桨量化模型。量化是指用低比特数值替换FP32数值进行存储和计算,以业界常见的INT8量化为例,其优点包括:减小存储空间、加快预测速度、降低能耗。PaddleSlim支持量化训练和静态离线量化方法,可以覆盖计算机视觉(CV)和自然语言处理 (NLP)模型,能产出较为准确的scale并统一采用对称量化方式。
在英特尔CPU上部署和加速百度飞桨量化模型时,关键步骤是与第三代英特尔®至强®VNNI可拓展指令集、英特尔®oneAPI工具包以及INT8压缩转化的结合。
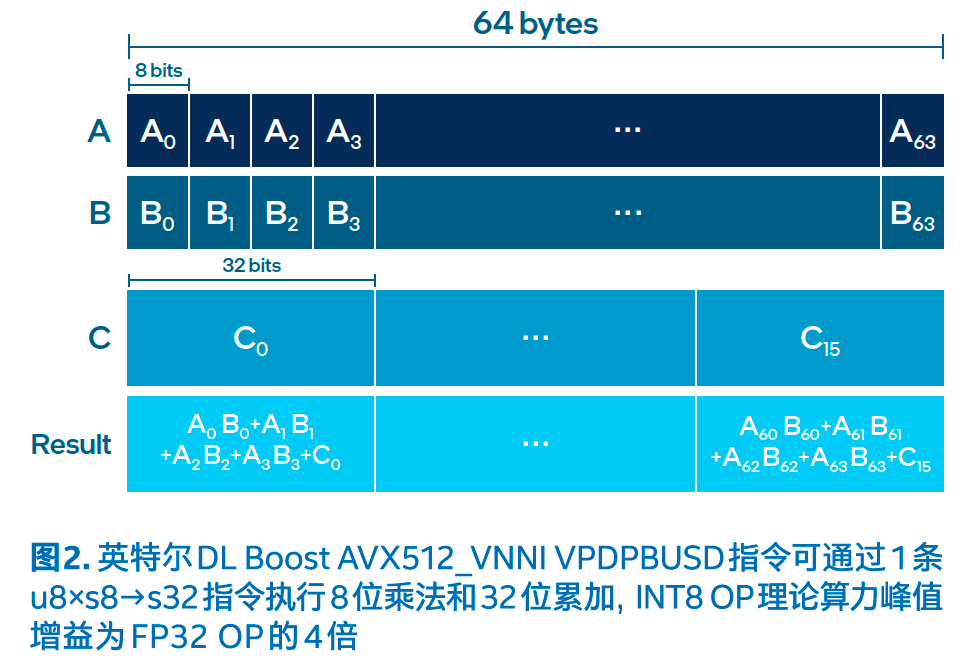
第三代英特尔®至强®可扩展处理器支持英特尔®深度学习加速(英特尔®Deep Learning Boost,包括更新的VNNI)技术,扩展了英特尔®高级矢量扩展指令集512(英特尔®AVX-512)。这一新嵌入式加速器可使用1条指令执行8位乘法u8 x s8 → s32和32位累加:VPMADDWD。相对于FP32格式,INT8模型将算力增加了4倍,内存要求降至1/4。内存的减少和频率的提高加快了低数值精度运算的速度,最终加速Al和深度学习推理,适合图像分类、语音识别、语音翻译、对象检测等众多方面。
为激活VNNI加速功能,百度飞桨压缩量化方案广泛使用英特尔®oneAPI工具包。英特尔®oneAPI是一个统一的、简化的编程模型,集成了多平台下向量计算算子的JIT( just-in-time)代码库,使开发者在不同的架构上(CPU、GPU和FPGA)都可以方便地调用 oneAPI算子的即时代码通用接口,而无需担心平台不兼容问题。
借助VNNI扩展指令和统一编程接口oneAPI的支持,PaddleSlim产出的模拟INT8模型可以转化成真实的INT8模型,并部署到第三代英特尔®至强®可扩展处理器上。转化部署过程中的核心步骤包括:
1.收集微调模拟模型所得的scale等数据。
2.对模型算子进行融合,如conv+relu算子融合并精简图。
3.根据所支持的oneDNN INT8算子列表,结合模型训练所得的scale 数据,做量化/反量化算子的插入操作。
4.最后,平台支持量化后的INT8模型保存,以便进行后续推理部署。
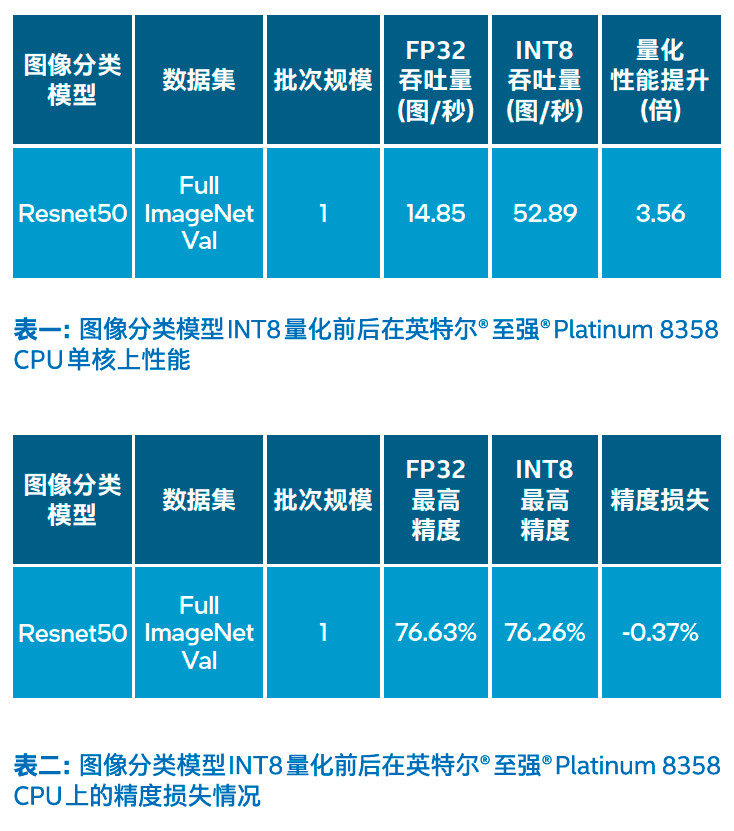
目前,百度飞桨模型量化及加速方案已广泛应用在百度多个服务中,如百度文字识别(OCR)服务。百度商业化OCR覆盖多场景、多语种、高精度的文字检测与识别服务,适用于远程身份认证、财税报销、文档电子化等场景,旨在为企业降本增效。百度OCR提供稳定易用的在线API、离线SDK、软件部署包等多种服务。在模型量化及加速方面,百度打造了一套以量化为核心的Slim OCR工具,取得了显著的性能提升。鉴于百度多个OCR模型均以图像分类模型Resnet5O为基础,此处以Resnet5O为例展示性能收益。
测试结果表明,在FuLL ImageNet VaL完整验证数据集上,Resnet5O INT8推理吞吐量是FP32的3.56倍(表一),而精度仅有极小损失(表二)。可见,在第三代英特尔®至强®可扩展处理器上使用百度飞桨量化策略可让多种深度学习模型的推理速度显著提升,有效提升用户深度学习应用的工作效能。
本文提及的第三代英特尔®至强®可扩展处理器是唯一具有内置Al 加速功能、端到端数据科学工具和智能解决方案生态系统的数据中心CPU。这一强大的能力组合可在从边缘到云的每个应用程序中解锁更多数据价值。
未来,凭借上述量化技术、部署工具及与英特尔硬件的深度整合优化,飞桨深度学习平台中丰富的模型资源及越来越成熟的多种应用开发套件(如PaddleOCR., PaddleDetection等),都将无缝地在英特尔平台上线,为用户提供最优的模型+硬件加速体验。
此外,百度飞桨的部署工具Paddle Inference和Paddle Lite等也将分别针对OpenVINO™工具套件等英特尔推理加速库进行原生整合。种种持续努力将帮助深度学习框架的用户以更低的门槛体验在英特尔硬件上的加速效果(详见本期第一篇文章)。