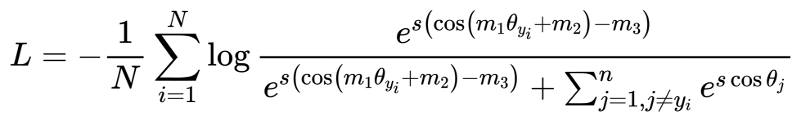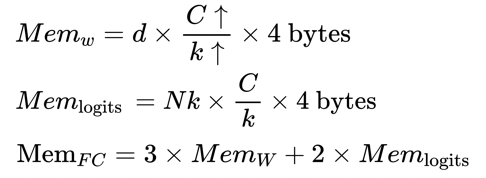大规模分类库PLSC再升级:单机训练6000万类视觉分类模型
发布日期:2021-11-16T11:58:00.000+0000 浏览量:2880次
在介绍大规模分类任务之前,我们先简短回顾一下通常的分类任务。大家熟知的视觉分类任务中,网络模型由特征提取器( Backbone)和分类器( Classifier)组成。分类的类别数有 2类 (如,前景 /背景分类 )、 10类(如, MNIST数据分类)、 80类(如, COCO数据分类)和 1000类(如, ImageNet数据分类)等等。比较主流的特征提取器有 ResNet, MobileNet等网络结构,分类器则通常采用线性分类层(全连接层, FC)。
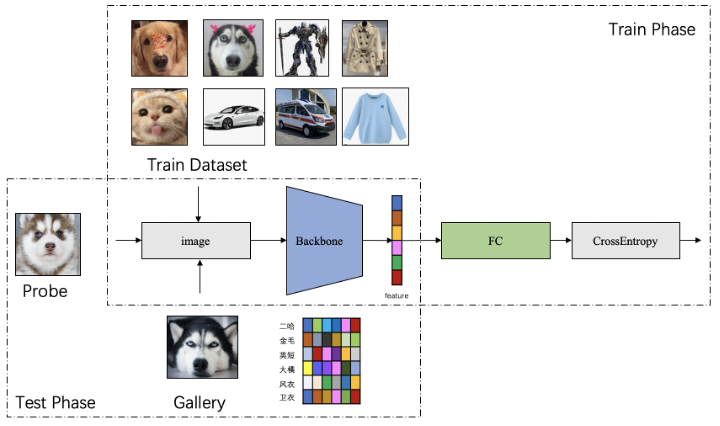
大规模分类任务的『大规模』指模型参数规模非常大,包括以下 3种情况:特征提取器参数规模大、分类器参数规模大,以及两者参数规模都大。万物互联时代,随着人工智能、 5G和 IoT等技术的发展,分类模型分类的类别数不断增加,类别数可以达到上千万甚至更多。在这种背景下,分类网络模型的 FC层的类别数增加,参数规模爆炸式增长。基于度量学习的分类模型,通常在训练阶段使用闭集数据集学习特征提取器和分类器,在推理阶段,仅使用特征提取器提取输入图像的特征,并与预提取的特征进行相似性对比得出是否属于同一类,如图 1所示。
本文聚焦于解决大规模分类模型训练问题。有小伙伴可能会问:大规模分类不就是一个普通的图像分类吗,除了分类类别数较多导致的 FC层参数量大以外,还有什么难题?图像分类领域每年有大量的论文和工作在 ImageNet 数据集上 取得新的 SOTA,随便从 Github 上找个图像分类库来训练是不是就可以了?
然而, FC层参数规模的急剧增长在训练时会带来以下两方面挑战:
首先是存储问题 。假设分类类别数为万,在训练阶段特征向量的维度为 512,并且以 32比特浮点数存储模型参数,那么仅 FC 层的参数就可达 512 * 40000000 * 4 (bytes) / 1024 / 1024= 76.29 GB,远远超出主流显卡的存储容量。这是普通图像分类库无法解决的存储问题。
其次是速度问题 。普通分类模型也面临同样的问题。随着训练数据、模型规模和分类类别数的增加,模型训练的复杂度显著增长,导致模型训练所需要的时间不断增长。速度是人类永无止境的追求,如何在更短的时间内训练大规模分类模型也是工程实践中迫切需要解决的问题。
为了解决以上两方面难题,学术界和工业界不断围绕着训练的显存消耗和速度进行优化;飞桨团队也持续不断地打磨升级大规模分类库 PLSC( Paddle Large Scale Classification),提供数据并行 &模型并行混合训练、类别中心采样、稀疏梯度参数更新和 FP16训练等解决方案。
接下来,小编将和大家一起来分享 PLSC提供的数据并行 &模型并行混合训练、模型并行 Loss计算、类别中心采样、稀疏梯度参数更新和 FP16训练解决方案。
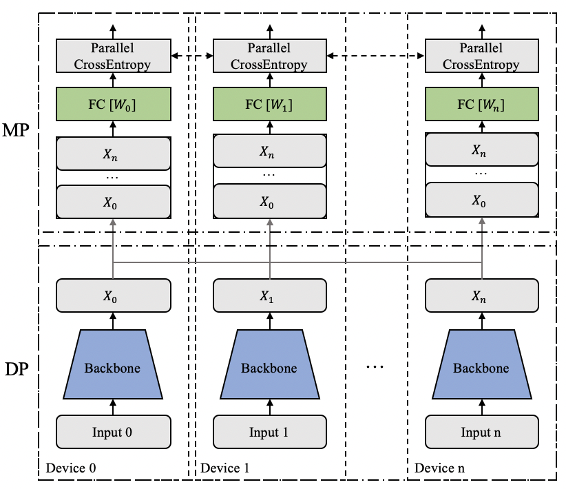
为了提高训练效率,通常使用多张 GPU卡做数据并行训练。但是对于大规模分类问题,类别数非常多,导致单卡无法训练。例如, 4000万类的分类网络模型仅 FC 层的参数量就高达 76.29 GB,远远超出主流显卡的存储容量。此外,数据并行下 FC层的梯度通信量也巨大,导致训练速度难以接受。针对 FC层参数存储和梯度通信问题,我们自然会想到是否可以将参数存放到多张 GPU卡上?答案是肯定的。我们可以采用模型并行策略,将 FC 层参数切分到多张卡上。
如图 2所示, Backbone 网络采用数据并行,分类 FC层采用模型并行,兼顾了数据并行的训练效率和分类 FC层参数的存储和梯度通信需求。在分类类别数为 4000万类时,假如使用单机 8卡,那么每张卡上的 FC层仅需存放 500万类,参数的存储大小为 76.29 GB/ 8 = 9.54 GB。
采用数据并行和模型并行结合的方式,单机 8卡情形下前向计算过程如下
(1)
每张卡接受一个
Batch
的数据,假设
batch size
为
64
;
(2)
每张卡使用输入数据做数据并行计算,经过
Backbone
得到
512
维特征向量,维度为
64x512
;
(3)
对每张卡上的特征和标签做
allgather
操作,从其他卡上收集特征和标签,此时每张卡上拥有全量特征维度为
512x512
,全量标签维度为
512x1
;
(4)
全量特征
(512x512)
和部分
FC
参数
(512x5000000)
做矩阵乘操作得到
logits
,维度为
512x5000000
;
(5)
使用模型并行的
SoftmaxWithCrossEntropy Loss
函数计算
loss
;
(图 2)Backbone 数据并行 & Classifer 模型并行
2. 模型并行 Loss 计算:
API 级 MarginLoss 函数
在度量学习领域中, ArcFace[2] 论文将 ArcFace, CosFace[3]和 SphereFace[4] Loss 函数用如下统一的公式表示,我们称为 MarginLoss:
MarinLoss 函数是在 logits上增加了 margin,最终基于的仍然是 SoftmaxWithCrossEntropy Loss函数。模型并行下最容易想到的计算 Loss的方法是用通信操作从其他卡上获取全量的 logits。但是这种方法不仅需要巨大的通信量,同时需要临时存储其他卡上的 logits,带来巨大的显存开销。飞桨框架在模型并行策略下提供了对 MarginLoss--paddle.nn.functional.margin_cross_entropy的原生支持。该接口通信量少且显存开销较小。
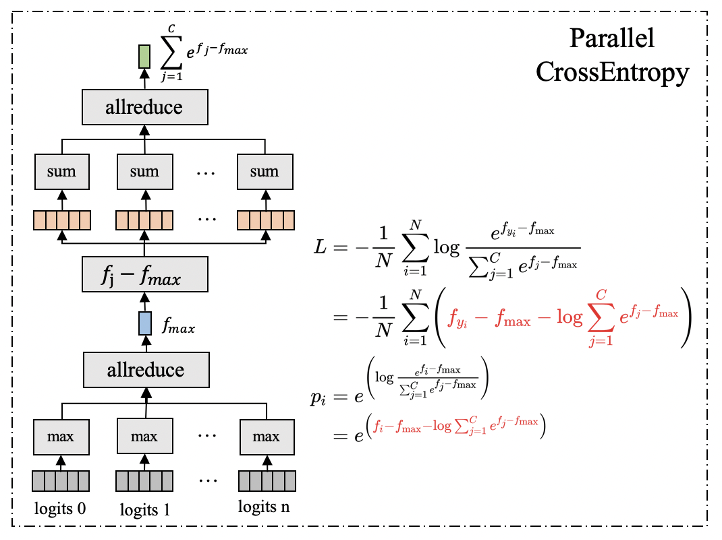
图 3给出模型并行下 SoftmaxwithCrossEntropy的计算过程。首先,在每张卡上逐行计算 logits 的最大值,然后通过 allreduce操作获取全局每行最大值。为了保持数值计算的稳定性,每行减去其对应的全局最大值。接着,逐行计算分母和,然后通过 allreduce操作获取全局和值。最后,逐行计算 loss, 并通过 allreduce操作获取全局 loss。图中,我们对 Loss和 Softmax Probability计算做了共同表达式提取。
(图 3)模型并行 SoftmaxwithCrossEntropy计算过程
3. 类别中心采样:
API 级支持 PartialFC
采用数据并行 &模型并行解决了 FC 参数存储的问题。但是,可以发现前向计算的 logits 存储需求也非常大,在 3.1小节的假设条件下为 512 * 5000000 * 4 (bytes) / 1024 / 1024 = 9.54 GB。考虑前向计算、反向计算和参数更新相关变量,当优化方法使用 Momentum时,可以得到 FC 层需要的存储大小:
其中d表示特征的维度, c表示总类别数, k表示 GPU卡数,N表示 Batch 大小,
表示参数存储大小,
表示 logits存储大小,
FC层总的存储大小。当类别数增大时,我们可以将 FC层参数切分到不同卡上,以保持每张卡上存储的参数大小不变。然而, logits的维度却是随卡数线性增长的。
因此,卡数增大k倍,
也增大k倍。训练过程中, FC层总的存储大小
等于 3 倍
( weight, gradient 和 velocity)加 2 倍
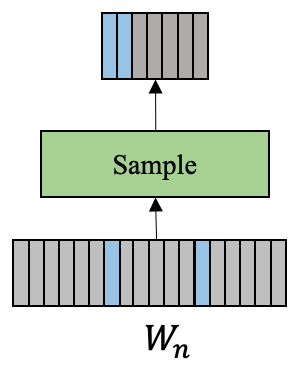
( activation 和 gradient)。为了解决 logits 和对应的梯度存储问题, PartialFC [5] 提出基于采样的 FC 层,即从全量 FC 中采样一部分类别中心参与本次迭代的学习。如图 4所示,对于正样本对应的类别中心全部保留,对于负类别中心按比例随机采样。假设采样比例为 1/10,则 logits 的维度为 512x500000,存储大小为 0.1 * 9.54 GB = 0.954 GB。优化前 存储大小为 2 * 9.54GB = 19.08GB,采用 PartialFC时需要的显存开销 为 2 * 0.954GB = 1.908GB,可见使用 PartialFC可以大幅减小显存开销。
飞桨提供了原生支持上述采样过程的 API--paddle.nn.functional.class_center_sample。
4. 稀疏梯度参数更新:
SparseMomentum
稀疏梯度参数更新是 PLSC 一大亮点。虽然 PartialFC 通过采样的方法缓解了 logits 和对应梯度的显存开销,但是通过上述分析我们发现 FC层仍然需要 3 倍的
,分别对应 FC层参数、梯度和优化器状态。我们是否可以进一步优化显存呢?答案是肯定的。
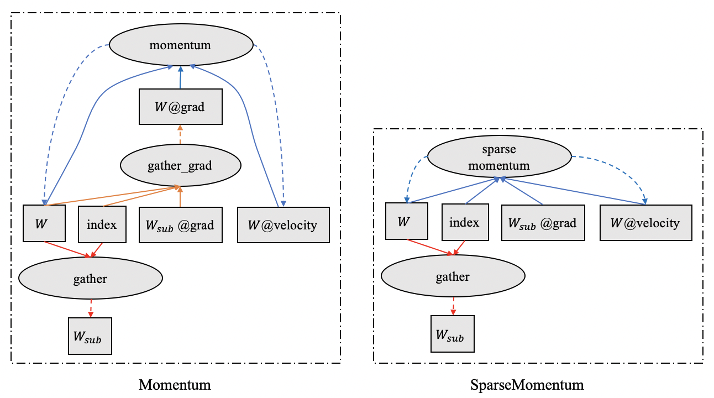
如图 5左所示,在前向计算过程中,通过对参数W的采样,得到采样类别中心
;反向计算梯度时,首先得到稀疏梯度
,进而得到参数梯度
;在参数更新阶段, momentum算子使用传入的参数
,参数梯度
和优化器状态
更新参数 W和优化器状态
。我们通过分析发现,参数梯度
是冗余的,其可以通过稀疏梯度
得到。为此,我们设计和开发了 sparse_momentum接口。相比于 momentum,该接口需要额外传入参数
,表示 FC参数采样的索引值,计算过程如图 5右所示。使用该接口,可以大幅减少梯度的存储空间,从而可以训练更大规模参数的模型。相比 momentum 需要 3 * 9.54 Gb + 2 * 0.954 Gb = 30.528 GB的存储空间,使用 sparse_momentum , FC层仅需要 2 * 9.54 Gb + 2 * 0.954 Gb = 20.988GB的存储空间,显存空间降低 31.25%。
(图 5)Momentum 和 SparseMomentum 的更新过程对比
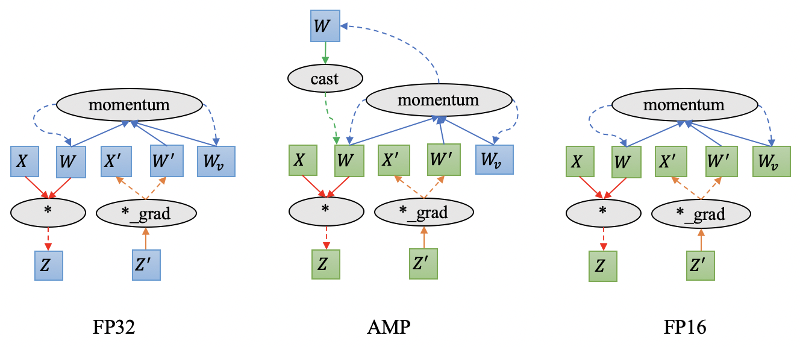
PLSC 的另外一个亮点是使用 FP16训练,即整个训练过程中参数、 Activation、梯度和优化器状态均使用 FP16,相比于 FP32显存空间节省 50%。相比 FP32 和 AMP[6] , FP16可以大幅节省显存,并大幅提升训练速度。
图 6分别给出是 FP32, AMP和 FP16 的计算过程。 FP32 计算过程中,所有模型参数、梯度、 Activation和优化器状态的数据类型均为 FP32。 AMP 计算过程中,模型参数和优化器状态为 FP32;计算过程中,将参数 cast 成 FP16,因此 Activation 和梯度也是 FP16;优化阶段参数梯度需要重新 cast为 FP32;所以,相比于 FP32, AMP通过将 Activation 和对应的梯度存储为 FP16,节省显存开销。 PLSC 使用的是真正意义的 FP16,即模型参数、 Activation、梯度和优化器状态均使用 FP16;相比 FP32显存开销减少 50%;此外,由于消除了 cast操作, FP16相比于 AMP可以进一步提升训练速度。
在上一节我们介绍了大规模分类模型训练的一些解决方案,这些解决方案都已经在 PLSC中实现且开源。此外,我们也已经将 PLSC开源到人脸识别社区 InsighFace[1]。 PLSC库地址: https://github.com/PaddlePaddle/PLSC
( 3 ) 支持单机和多机分布式训练,API
级支持模型并行、
PartialFC和MarginLoss
接下来我们将从训练精度、显存开销和训练速度 3个维度来评测 PLSC。
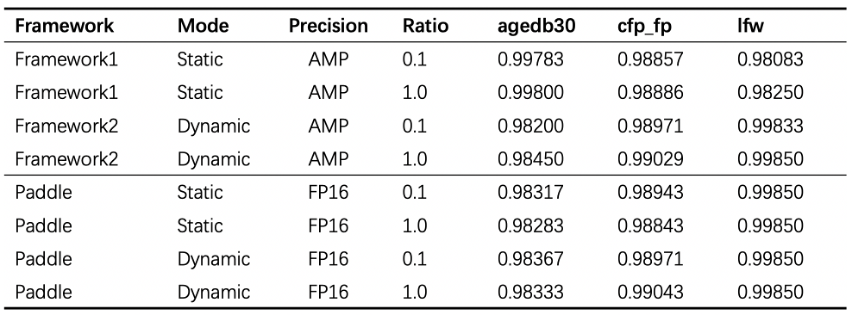
(表 1)不同框架实现的 Repo在 MS1MV3数据集上的精度对比
从表 1中,我们可以看到虽然 PLSC使用了 FP16,但在主要数据集上 PLSC的精度仍然可以打平其它框架实现。
(1)GPUs
:
8 NVIDIA Tesla V100 32G
(2)BatchSize
:
64/512 (
每张卡的
batch size
是
64
,全局
batch size
是
512
个样本
)
(3)SampleRatio: 0.1 (PartialFC
采样率为
0.1)
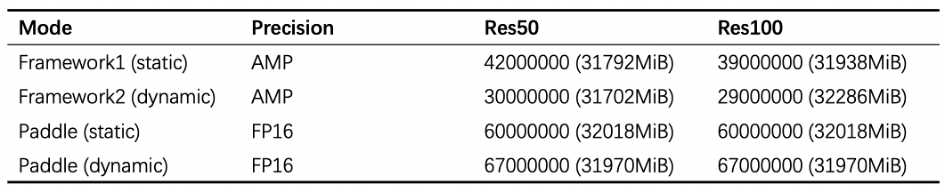
表中数据说明,相比其他的框架实现, PLSC在显存优化方面具有显著优势:静态图最多支持 6000万类别分类,动态图最多可支持 6700 万类别分类。
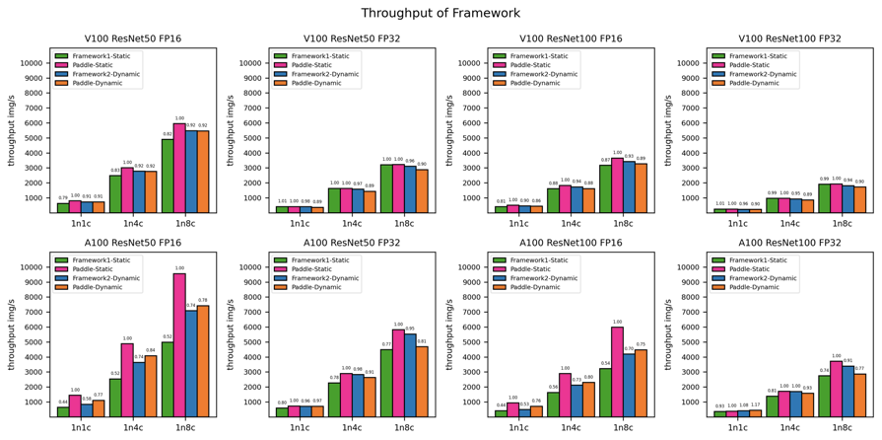
吞吐量是每秒训练的样本数。我们采用公开数据集 MS1MV3 来测试。为了取得稳定和公平的结果,我们对每个实验配置都运行了 5 组实验,每组运行 200 个 steps,然后计算 50 到 150 个 steps间的 100个 steps吞吐量的平均值,最后得到这 5组实验的平均吞吐量后再取中位数作为最终的吞吐量结果。以下是实验配置:
(1) Tesla V100 (32G): Driver Version: 450.80.02, CUDA Version: 11.0
(2)Tesla A100 (40G): Driver Version: 460.32.03, CUDA Version: 11.2
(3)Datasets: MS1MV3 (93431
类
)
(4)SampleRatio: 0.1 (
使用了
PartialFC
,采样率为
0.1)
(5)BatchSize
:
128 (
每张卡
128
个样本
)
从图 7可以看出 PLSC静态图模式下,优于所有框架实现,尤其在 A100, ResNet50, FP16, 8卡的配置下, PLSC吞吐量高达 9500 imgs/s。
大规模分类的一个典型应用就是人脸识别,这里我们邀请到了 InsightFace项目发起人与飞桨开发者一起,在 B站直播间,为大家深入技术解读。
微信扫描下方二维码或点击"阅读原文 "报名直播课 。报名成功后即可加入 InsightFace交流群,与 Insightface项目发起人和飞桨开发者一起技术交流。
GitHub:
https://github.com/PaddlePaddle/PLSC
GitHub:
https://github.com/deepinsight/insightface
[1]https://github.com/deepinsight/insightface.git
[2]Deng, J., Guo, J., Xue, N. and Zafeiriou, S., 2019. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4690-4699).
[3]Wang, H., Wang, Y., Zhou, Z., Ji, X., Gong, D., Zhou, J., Li, Z. and Liu, W., 2018. Cosface: Large margin cosine loss for deep face recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 5265-5274).
[4]Liu, W., Wen, Y., Yu, Z., Li, M., Raj, B. and Song, L., 2017. Sphereface: Deep hypersphere embedding for face recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 212-220).
[5]An, X., Zhu, X., Gao, Y., Xiao, Y., Zhao, Y., Feng, Z., Wu, L., Qin, B., Zhang, M., Zhang, D. and Fu, Y., 2021. Partial fc: Training 10 million identities on a single machine. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 1445-1449).
[6]Micikevicius, P., Narang, S., Alben, J., Diamos, G., Elsen, E., Garcia, D., Ginsburg, B., Houston, M., Kuchaiev, O., Venkatesh, G. and Wu, H., 2017. Mixed precision training. arXiv preprint arXiv:1710.03740.