

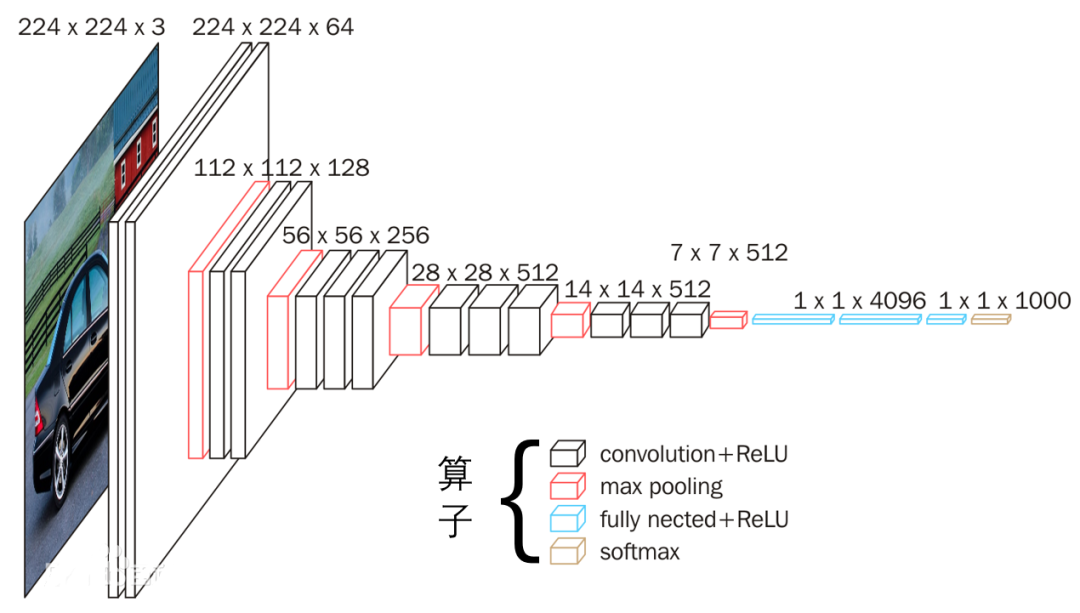
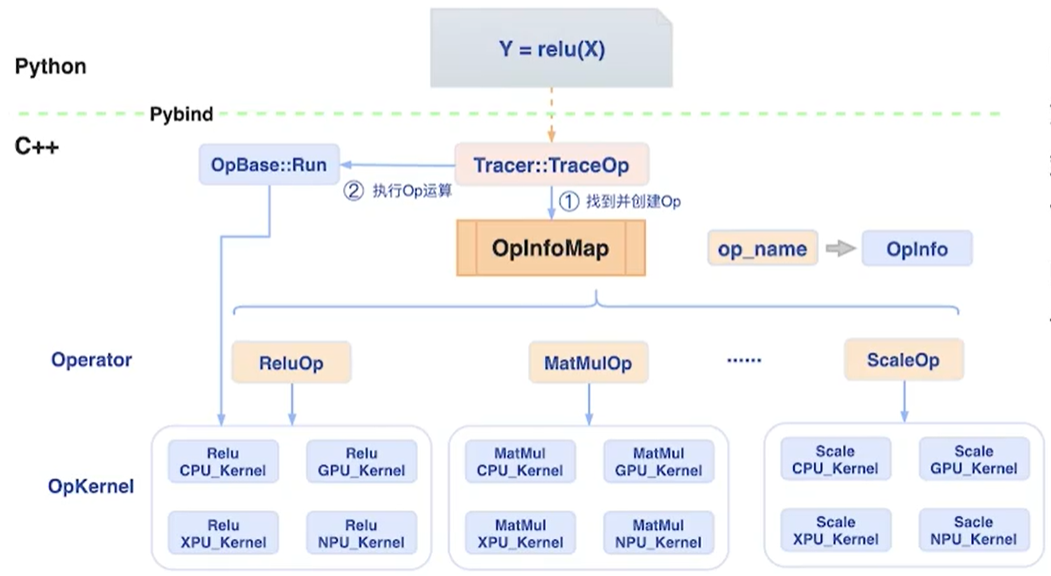
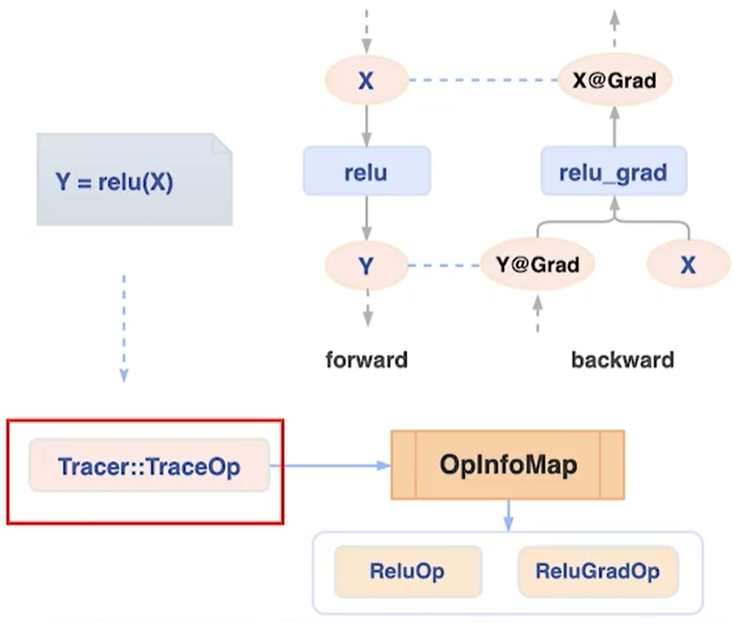
构建神经网络模型需要使用到各种各样的算子(Operator),例如卷积算子、各类数学运算算子、激活函数算子等,深度学习框架需要提供这些算子的运算支持,因此在深度学习框架内部很大一部分工作都是围绕如何对这些算子(Oparetor)进行管理、调度和执行来展开。飞桨开源框架目前已经提供了大量的算子供用户使用,(如图2所示)在框架内部使用OpInfoMap对所有飞桨支持的算子(Oparetor)进行注册和管理(OpInfoMap本质上是一个全局Map,使用算子的名称作为Key,算子的描述信息、构建函数、辅助行功能函数等具体组件作为对应的Value项)。
C++自定义算子格式
基本格式
#include "paddle/extension.h"
std::vector<paddle::Tensor> OpFucntion(const paddle::Tensor& x, ..., int attr, ...) {
...
}
适配多种数据类型
switch(x.type()) {
case paddle::DataType::FLOAT32:
...
break;
case paddle::DataType::FLOAT64:
...
break;
default:
PD_THROW(
"function ... is not implemented for data type `",
paddle::ToString(x.type()), "`");
}

自定义算子注册

动手实现
CPU算子
导入必要的头文件
#include "paddle/extension.h"
#include <vector>
#define CHECK_CPU_INPUT(x) PD_CHECK(x.place() == paddle::PlaceType::kCPU, #x " must be a CPU Tensor.")
实现forward计算函数
std::function(input)。
template <typename data_t> // 模板函数
void sin_cpu_forward_kernel(const data_t* x_data,
data_t* out_data,
int64_t x_numel) {
for (int i = 0; i < x_numel; ++i) {
out_data[i] = std::sin(x_data[i]);
}
}
std::vector<paddle::Tensor> sin_cpu_forward(const paddle::Tensor& x) {
CHECK_CPU_INPUT(x);
// 声明输出变量out,需传入两个参数(运行的设备类型及维度信息)
auto out = paddle::Tensor(paddle::PlaceType::kCPU, x.shape());
// 计算实现,PD_DISPATCH宏具体使用方法和原理详见:
// 飞桨官方文档自定义外部算子CPU实现部分
PD_DISPATCH_FLOATING_TYPES(
x.type(), "sin_cpu_forward_kernel", ([&] {
sin_cpu_forward_kernel<data_t>( // 调用前面定义好的前向计算函数,这里必须是data_t
x.data<data_t>(), // 获取输入的内存地址,即从内存空间中取数据,这里必须是data_t
out.mutable_data<data_t>(x.place()), x.size()); // 为输出申请内存空间,这里必须是data_t
}));
return {out};
}
实现backward计算函数
template <typename data_t>
void sin_cpu_backward_kernel(const data_t* grad_out_data,
const data_t* x_data,
data_t* grad_x_data,
int64_t out_numel) {
for (int i = 0; i < out_numel; ++i) {
grad_x_data[i] = grad_out_data[i] * std::cos(x_data[i]); // 结果是返回的梯度值乘函数导数值
}
}
std::vector<paddle::Tensor> sin_cpu_backward(const paddle::Tensor& x, // forward的输入
const paddle::Tensor& out, // forward的输出
const paddle::Tensor& grad_out) { // backward的梯度变量
auto grad_x = paddle::Tensor(paddle::PlaceType::kCPU, x.shape());
// 计算实现
PD_DISPATCH_FLOATING_TYPES(out.type(), "sin_cpu_backward_kernel", ([&] {
sin_cpu_backward_kernel<data_t>(
grad_out.data<data_t>(), // 获取内存地址,即从内存空间中取数据
x.data<data_t>(), // 获取内存地址,即从内存空间中取数据
grad_x.mutable_data<data_t>(x.place()), // 申请内存空间
out.size()); // 传入输出的维度信息
}));
return {grad_x};
}
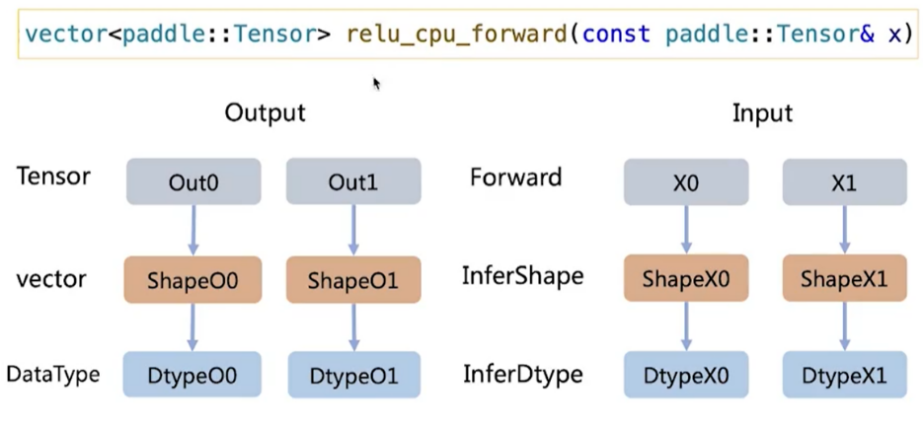
维度推导
// 维度推导
std::vector<std::vector<int64_t>> sinInferShape(std::vector<int64_t> x_shape) {
return {x_shape};
}
// 类型推导
std::vector<paddle::DataType> sinInferDtype(paddle::DataType x_dtype) {
return {x_dtype};
}
自定义算子注册
PD_BUILD_OP(custom_sin_cpu)
.Inputs({"X"})
.Outputs({"Out"})
.SetKernelFn(PD_KERNEL(sin_cpu_forward))
.SetInferShapeFn(PD_INFER_SHAPE(sinInferShape))
.SetInferDtypeFn(PD_INFER_DTYPE(sinInferDtype));
PD_BUILD_GRAD_OP(custom_sin_cpu)
.Inputs({"X", "Out", paddle::Grad("Out")})
.Outputs({paddle::Grad("X")})
.SetKernelFn(PD_KERNEL(sin_cpu_backward));
自定义
CPU算子的使用
使用JIT (即时编译)安装加载自定义算子,其基本格式如下:

from paddle.utils.cpp_extension import load
custom_ops = load(
name="custom_jit_ops",
sources=["custom_op/custom_sin_cpu.cc"])
custom_sin_cpu = custom_ops.custom_sin_cpu
Compiling user custom op, it will cost a few seconds.....
使用该算子也非常简单,直接使用即可,如下所示:
import paddle
import paddle.nn.functional as F
import numpy as np
# 定义执行环境
device = 'cpu'
paddle.set_device(device)
# 将输入数据转换为张量
data = np.random.random([4, 12]).astype(np.float32)
x = paddle.to_tensor(data, stop_gradient=False)
# 调用自定义算子实现前向计算
y = custom_sin_cpu(x)
# 调用自定义算子实现反向传播
y.mean().backward()
print("前向计算结果:{}".format(y))
print("梯度结果:{}".format(x.grad))

import paddle
import paddle.nn.functional as F
import numpy as np
device = 'cpu'
paddle.set_device(device)
data = np.random.random([4, 12]).astype(np.float32)
x_target = paddle.to_tensor(data, stop_gradient=False)
y_target = paddle.sin(x_target)
y_target.mean().backward()
x = paddle.to_tensor(data, stop_gradient=False)
y = custom_sin_cpu(x)
y.mean().backward()
# 输出都为True表示结果正确
print("sin_result: ",paddle.allclose(y_target, y).numpy())
print("sin_grad_result: ",paddle.allclose(x_target.grad, x.grad).numpy())
sin_result: [ True]
sin_grad_result: [ True]
总结与升华
最后总结一下C++自定义算子最主要的思路,其实就是3点:
forward和backward实现
《飞桨论文复现打卡营》高阶课:Paddle自定义算子实现和使用
论文复现营C++自定义算子开发Demo by zhangyunfei:
飞桨使用教程:自定义算子之自定义C++算子实现: