Graphcore和飞桨联合发布了在Graphcore IPU上支持训练和推理完整流程的开源代码库。在本篇文章中,我们将会介绍飞桨与Graphcore的合作初衷和成果,并为大家解读飞桨与Graphcore IPU的适配方案,以及Graphcore在硬件设计上的独特之处。
如果您想要体验使用Graphcore运行深度学习任务,请参考本期第一篇文章『
即刻体验!在飞桨 x Graphcore IPU上运行训练与推理任务
』。
Graphcore的智能处理器 (IPU) 是第一个专为机器智能设计的处理器,其IPU硬件和Poplar SDK能够帮助开发者在机器智能方面实现新突破。而作为飞桨重要的硬件合作伙伴,Graphcore将通过云端和数据中心的IPU技术助力我们飞桨的开发者们实现AI模型大幅加速,同时也为使用飞桨的企业提供基于IPU的产品方案,帮助飞桨的企业级客户提升数据中心效率。通过大幅提升模型的性能和运行速度,缩短研发周期,加快AI模型落地应用,同时降低计算成本。
图1. Graphcore中国工程总负责人、AI算法科学家金琛在2021 Wave Summit峰会上介绍IPU上的百度飞桨
目前Graphcore IPU支持通过飞桨完成大规模的模型训练任务,也支持通过飞桨推理库执行高性能的推理任务。双方团队通过在16个IPU组成的IPU-POD16上做数据并行与模型并行,并在Bert-Base模型上进行了精读和吞吐量验证,取得了良好的性能效果。
结果证明,运行在IPU硬件上的百度飞桨解决方案,在目前主流的AI训练任务和前沿AI创新模型任务上,可以取得很好的加速效果。IPU良好的系统扩展性使得用户可以根据任务需求灵活扩展性能。
图2. BERT base training on PaddlePaddle
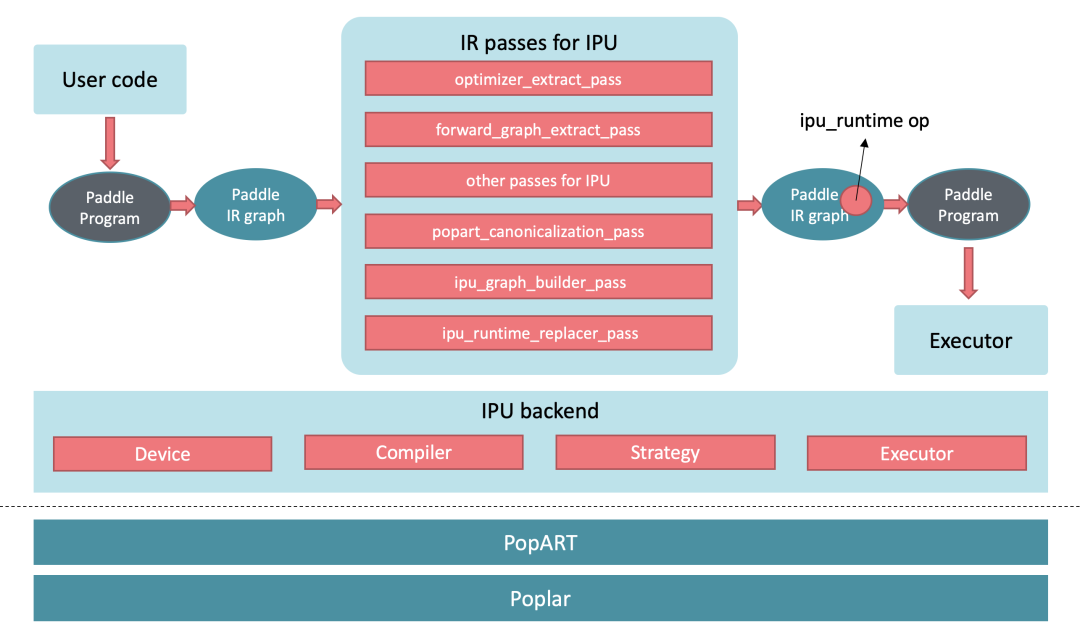
飞桨框架当前支持以算子接入、子图/整图接入以及编译器后端三种方式对接硬件,并且包含定义良好的IR(Intermediate Representation),以及用于做图优化的IR Pass机制。飞桨框架同时也通过扩展新的Device类型、Operator、Pass、Executor等机制,使框架拥有良好的扩展性,方便开发者来支持新的硬件类型。
基于上述特点,飞桨框架团队与Graphcore研发团队决定以子图/整图接入作为切入点来支持IPU,遵守的原则是尽量减少对飞桨框架原生代码的侵入式修改,通过扩展IR Pass、扩展Operator的方式来增量式开发,最低程度减少对飞桨框架原有代码逻辑的影响。在图3中,我们展示了Graphcore在飞桨框架中的集成逻辑。。
Graphcore的IPU的设计目标是解决大多数ASIC和GPU中存在的那些当前加速架构无法解决的问题。这些芯片通常是针对密集的线性代数工作负载进行特定优化的,这些工作负载或许可以在某些卷积神经网络中较为高效的执行,但却不太适合更加变化多样的数据访问模式。
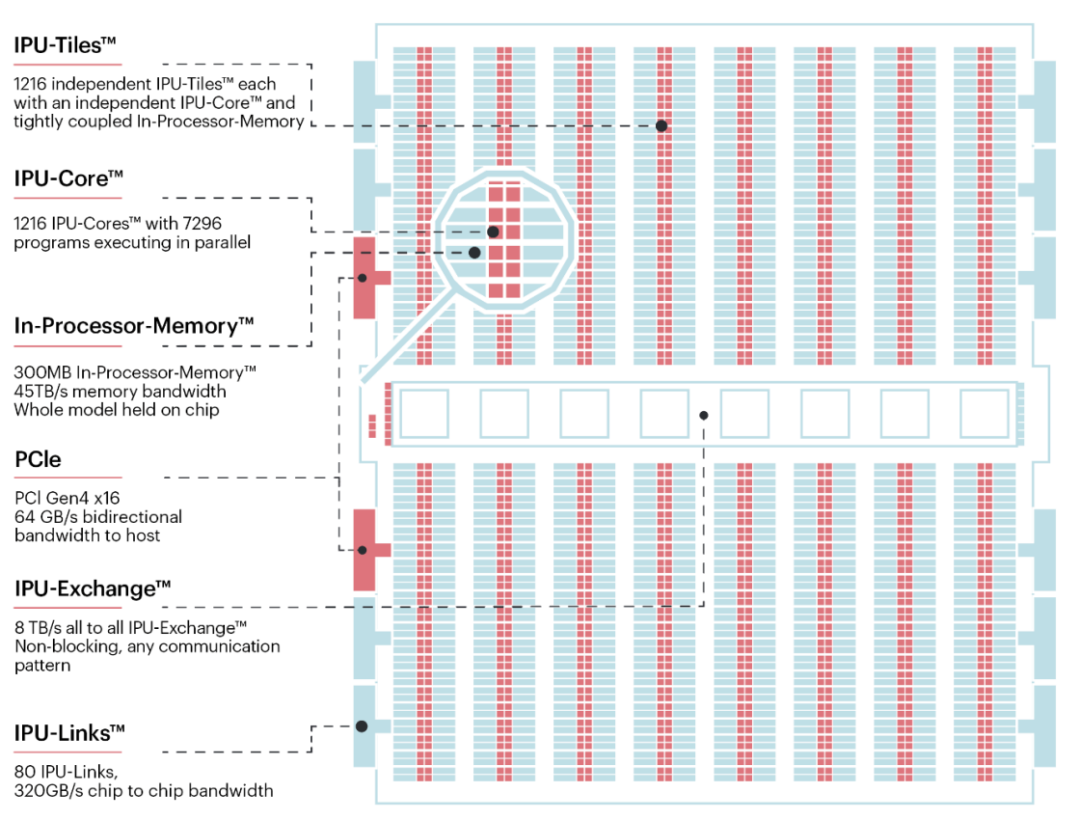
以Graphcore第一代IPU为例,其由1216个相互连接的处理 tile 组成。其中每个 tile 享有专属核和片上SRAM内存,以使模型和数据能够尽可能在IPU上驻留,从而改善内存带宽的压力并降低延迟。这些tile能够以8 TB/秒的速率通过片上的IPU-Exchange进行互连,而IPU-Exchange可以进一步通过以320 GB/秒带宽运行的IPU-Link进行连接,为芯片到芯片间的高速连接创造可能。
图4. Colossus™ MK1 IPU处理器架构
Graphcore的多机系统通常由许多IPU组成,而同步执行则可分为:通信、计算两个阶段。
在计算阶段中,运行在IPU上的程序可被表示为计算图,其中图上的的顶点负责执行计算,计算结果将通过与顶点相邻的边传递到相邻计算顶点。而在通信阶段中,通过Bulk Synchronous Parallel(BSP)的批量同步并行计算模型操作,可将每个tile在片上SRAM 中的数据,高效传输到那些与其相连的 tile 内存中。
除了计算指令外每个IPU核还具有专用的tile级指令集,用于BSP模型的通信阶段。集成的交换-通信结构,旨在支持通过计算图编译器实现的、用于数据和模型并行性的BSP,并可能扩展到数千个节点。根据Graphcore的说法,IPU架构的一个重要区别是其能够有效处理稀疏数据和计算图的能力,这可以在提高性能的同时减少总内存需求。
自第一代Colossus IPU以来,Graphcore已在芯片和系统架构上的计算、通信和存储方面取得了突破性进展,而其第二代产品 “Graphcore的Colossus™MK2 IPU处理器——GC200” 实践性能较MK1 IPU提高了8倍。拥有594亿个晶体管、采用台积电 7纳米工艺制造、每个MK2 IPU具有1472个强大的处理器内核、可运行近9,000个独立的并行程序线程。Colossus MK2 GC200 IPU的每个IPU在FP16.16和FP16.SR(随机舍入)上都拥有前所未有的900MB处理器内存储器和250 TeraFlops AI计算。
图5. Colossus MK2 GC200 IPU
由Graphcore第二代IPU处理器构建的IPU-M2000是用于构建基于IPU的机器智能的基本计算引擎。Graphcore的硬件架构提供了1 PetaFlop AI计算和450GB的超快速Exchange-Memory™。IPU-Machine具有新的超低时延IPU-Fabric™,可以进一步构建可横向扩展的IPU-POD™,最多可连接64,000个IPU。
获取更多Graphcore资讯,阅读深度技术文章,并与其他创新者们一起交流,敬请访问
https://www.graphcore.cn/。