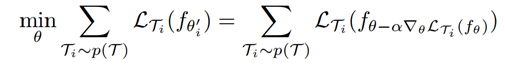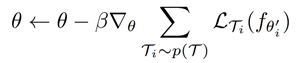
研究背景
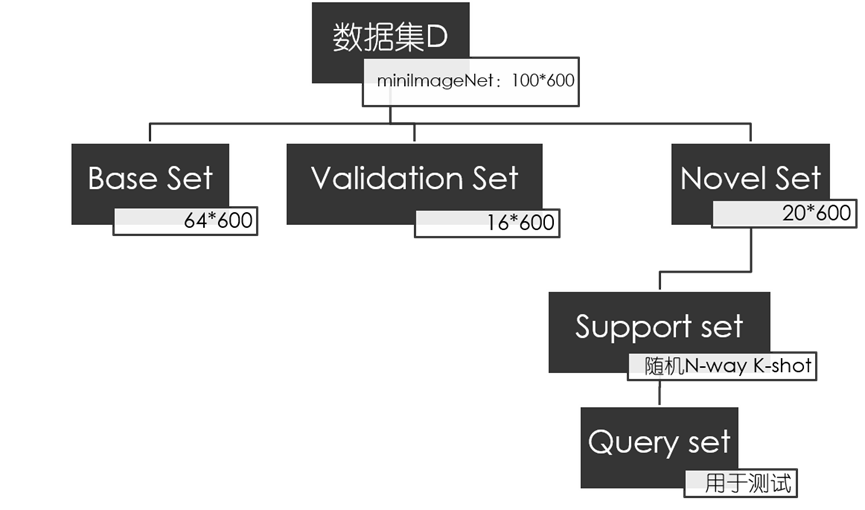
问题定义
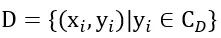 中包含
中包含
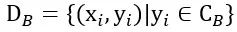 ,一部分称为新颖集(Novel Set)
,一部分称为新颖集(Novel Set)
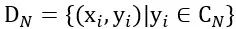 ,
其中,
,
其中,
评价标准
常用数据集
Omniglot[5]:包含50个不同的字母表,每个字母表中的字母各包含20个手写字符样本,每一个手写样本都是不同人通过亚马逊Mechanical Turk在线绘制的。Omniglot数据集的多样性强于MNIST数据集,常用于小样本识别任务。

https://aistudio.baidu.com/aistudio/datasetdetail/23613
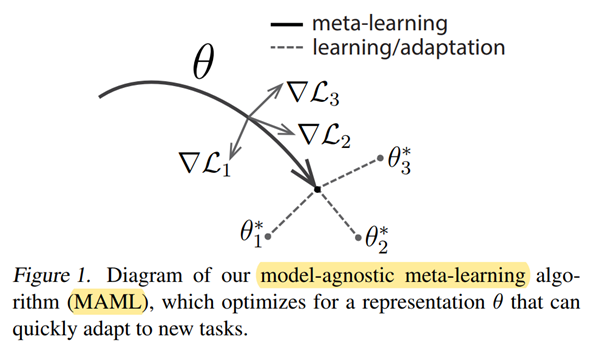
MAML模型算法
模型方法
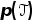 上采样一组任务
上采样一组任务
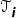 ,计算在这组任务上的损失函数;内层循环是微调过程,即针对每一个任务
,迭代一次(或若干次)梯度下降,将参数进行更新为
,计算在这组任务上的损失函数;内层循环是微调过程,即针对每一个任务
,迭代一次(或若干次)梯度下降,将参数进行更新为
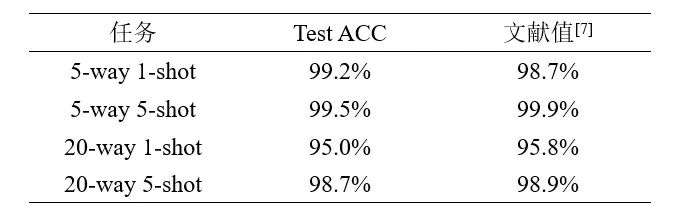
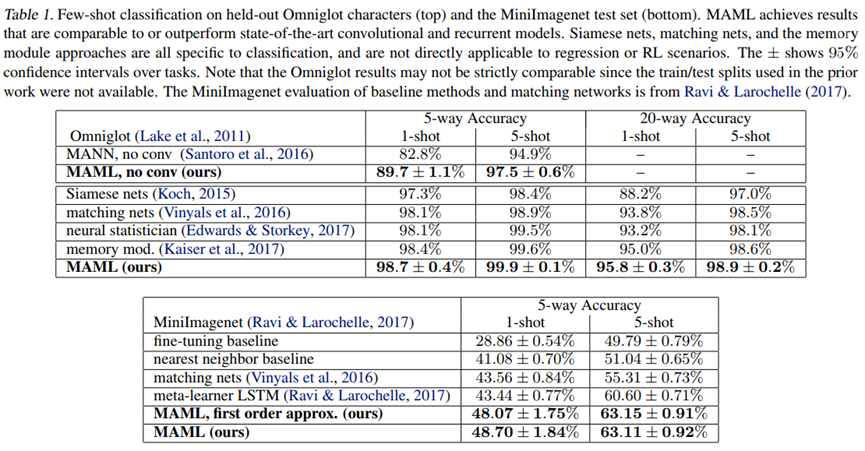
实验结果
在Omniglot和miniImageNet数据集上,文献给出的实验结果如下图所示。
飞桨实现
关键代码实现
1class MAML(paddle.nn.Layer):
2 def __init__(self, n_way):
3 super(MAML, self).__init__()
4 # 定义模型中全部待优化参数
5 self.vars = []
6 self.vars_bn = []
7 # ------------------------第1个conv2d-------------------------
8 weight = paddle.static.create_parameter(shape=[64, 1, 3, 3],
9 dtype='float32',
10 default_initializer=nn.initializer.KaimingNormal(),
11 is_bias=False)
12 bias = paddle.static.create_parameter(shape=[64],
13 dtype='float32',
14 is_bias=True) # 初始化为零
15 self.vars.extend([weight, bias])
16 # 第1个BatchNorm
17 weight = paddle.static.create_parameter(shape=[64],
18 dtype='float32',
19 default_initializer=nn.initializer.Constant(value=1),
20 is_bias=False)
21 bias = paddle.static.create_parameter(shape=[64],
22 dtype='float32',
23 is_bias=True) # 初始化为零
24 self.vars.extend([weight, bias])
25 running_mean = paddle.to_tensor(np.zeros([64], np.float32), stop_gradient=True)
26 running_var = paddle.to_tensor(np.zeros([64], np.float32), stop_gradient=True)
27 self.vars_bn.extend([running_mean, running_var])
28 # ------------------------第2个conv2d------------------------
29 weight = paddle.static.create_parameter(shape=[64, 64, 3, 3],
30 dtype='float32',
31 default_initializer=nn.initializer.KaimingNormal(),
32 is_bias=False)
33 bias = paddle.static.create_parameter(shape=[64],
34 dtype='float32',
35 is_bias=True)
36 self.vars.extend([weight, bias])
37 # 第2个BatchNorm
38 weight = paddle.static.create_parameter(shape=[64],
39 dtype='float32',
40 default_initializer=nn.initializer.Constant(value=1),
41 is_bias=False)
42 bias = paddle.static.create_parameter(shape=[64],
43 dtype='float32',
44 is_bias=True) # 初始化为零
45 self.vars.extend([weight, bias])
46 running_mean = paddle.to_tensor(np.zeros([64], np.float32), stop_gradient=True)
47 running_var = paddle.to_tensor(np.zeros([64], np.float32), stop_gradient=True)
48 self.vars_bn.extend([running_mean, running_var])
49 # ------------------------第3个conv2d------------------------
50 weight = paddle.static.create_parameter(shape=[64, 64, 3, 3],
51 dtype='float32',
52 default_initializer=nn.initializer.KaimingNormal(),
53 is_bias=False)
54 bias = paddle.static.create_parameter(shape=[64],
55 dtype='float32',
56 is_bias=True)
57 self.vars.extend([weight, bias])
58 # 第3个BatchNorm
59 weight = paddle.static.create_parameter(shape=[64],
60 dtype='float32',
61 default_initializer=nn.initializer.Constant(value=1),
62 is_bias=False)
63 bias = paddle.static.create_parameter(shape=[64],
64 dtype='float32',
65 is_bias=True) # 初始化为零
66 self.vars.extend([weight, bias])
67 running_mean = paddle.to_tensor(np.zeros([64], np.float32), stop_gradient=True)
68 running_var = paddle.to_tensor(np.zeros([64], np.float32), stop_gradient=True)
69 self.vars_bn.extend([running_mean, running_var])
70 # ------------------------第4个conv2d------------------------
71 weight = paddle.static.create_parameter(shape=[64, 64, 3, 3],
72 dtype='float32',
73 default_initializer=nn.initializer.KaimingNormal(),
74 is_bias=False)
75 bias = paddle.static.create_parameter(shape=[64],
76 dtype='float32',
77 is_bias=True)
78 self.vars.extend([weight, bias])
79 # 第4个BatchNorm
80 weight = paddle.static.create_parameter(shape=[64],
81 dtype='float32',
82 default_initializer=nn.initializer.Constant(value=1),
83 is_bias=False)
84 bias = paddle.static.create_parameter(shape=[64],
85 dtype='float32',
86 is_bias=True) # 初始化为零
87 self.vars.extend([weight, bias])
88 running_mean = paddle.to_tensor(np.zeros([64], np.float32), stop_gradient=True)
89 running_var = paddle.to_tensor(np.zeros([64], np.float32), stop_gradient=True)
90 self.vars_bn.extend([running_mean, running_var])
91 # ------------------------全连接层------------------------
92 weight = paddle.static.create_parameter(shape=[64, n_way],
93 dtype='float32',
94 default_initializer=nn.initializer.XavierNormal(),
95 is_bias=False)
96 bias = paddle.static.create_parameter(shape=[n_way],
97 dtype='float32',
98 is_bias=True)
99 self.vars.extend([weight, bias])
100
101 def forward(self, x, params=None, bn_training=True):
102 if params is None:
103 params = self.vars
104 weight, bias = params[0], params[1] # 第1个CONV层
105 x = F.conv2d(x, weight, bias, stride=1, padding=1)
106 weight, bias = params[2], params[3] # 第1个BN层
107 running_mean, running_var = self.vars_bn[0], self.vars_bn[1]
108 x = F.batch_norm(x, running_mean, running_var, weight=weight, bias=bias, training=bn_training)
109 x = F.relu(x) # 第1个relu
110 x = F.max_pool2d(x, kernel_size=2) # 第1个MAX_POOL层
111 weight, bias = params[4], params[5] # 第2个CONV层
112 x = F.conv2d(x, weight, bias, stride=1, padding=1)
113 weight, bias = params[6], params[7] # 第2个BN层
114 running_mean, running_var = self.vars_bn[2], self.vars_bn[3]
115 x = F.batch_norm(x, running_mean, running_var, weight=weight, bias=bias, training=bn_training)
116 x = F.relu(x) # 第2个relu
117 x = F.max_pool2d(x, kernel_size=2) # 第2个MAX_POOL层
118 weight, bias = params[8], params[9] # 第3个CONV层
119 x = F.conv2d(x, weight, bias, stride=1, padding=1)
120 weight, bias = params[10], params[11] # 第3个BN层
121 running_mean, running_var = self.vars_bn[4], self.vars_bn[5]
122 x = F.batch_norm(x, running_mean, running_var, weight=weight, bias=bias, training=bn_training)
123 x = F.relu(x) # 第3个relu
124 x = F.max_pool2d(x, kernel_size=2) # 第3个MAX_POOL层
125 weight, bias = params[12], params[13] # 第4个CONV层
126 x = F.conv2d(x, weight, bias, stride=1, padding=1)
127 weight, bias = params[14], params[15] # 第4个BN层
128 running_mean, running_var = self.vars_bn[6], self.vars_bn[7]
129 x = F.batch_norm(x, running_mean, running_var, weight=weight, bias=bias, training=bn_training)
130 x = F.relu(x) # 第4个relu
131 x = F.max_pool2d(x, kernel_size=2) # 第4个MAX_POOL层
132 x = paddle.reshape(x, [x.shape[0], -1]) ## flatten
133 weight, bias = params[-2], params[-1] # linear
134 x = F.linear(x, weight, bias)
135 output = x
136 return output
137
138 def parameters(self, include_sublayers=True):
139 return self.vars
元学习器类的代码如下:
1class MetaLearner(nn.Layer):
2 def __init__(self, n_way, glob_update_step, glob_update_step_test, glob_meta_lr, glob_base_lr):
3 super(MetaLearner, self).__init__()
4 self.update_step = glob_update_step # task-level inner update steps
5 self.update_step_test = glob_update_step_test
6 self.net = MAML(n_way=n_way)
7 self.meta_lr = glob_meta_lr # 外循环学习率
8 self.base_lr = glob_base_lr # 内循环学习率
9 self.meta_optim = paddle.optimizer.Adam(learning_rate=self.meta_lr, parameters=self.net.parameters())
10
11 def forward(self, x_spt, y_spt, x_qry, y_qry):
12 task_num = x_spt.shape[0]
13 query_size = x_qry.shape[1] # 75 = 15 * 5
14 loss_list_qry = [0 for _ in range(self.update_step + 1)]
15 correct_list = [0 for _ in range(self.update_step + 1)]
16
17 # 内循环梯度手动更新,外循环梯度使用定义好的更新器更新
18 for i in range(task_num):
19 # 第0步更新
20 y_hat = self.net(x_spt[i], params=None, bn_training=True) # (setsz, ways)
21 loss = F.cross_entropy(y_hat, y_spt[i])
22 grad = paddle.grad(loss, self.net.parameters()) # 计算所有loss相对于参数的梯度和
23 tuples = zip(grad, self.net.parameters()) # 将梯度和参数一一对应起来
24 # fast_weights这一步相当于求了一个\theta - \alpha*\nabla(L)
25 fast_weights = list(map(lambda p: p[1] - self.base_lr * p[0], tuples))
26 # 在query集上测试,计算准确率
27 # 这一步使用更新前的数据,loss填入loss_list_qry[0],预测正确数填入correct_list[0]
28 with paddle.no_grad():
29 y_hat = self.net(x_qry[i], self.net.parameters(), bn_training=True)
30 loss_qry = F.cross_entropy(y_hat, y_qry[i])
31 loss_list_qry[0] += loss_qry
32 pred_qry = F.softmax(y_hat, axis=1).argmax(axis=1) # size = (75) # axis取-1也行
33 correct = paddle.equal(pred_qry, y_qry[i]).numpy().sum().item()
34 correct_list[0] += correct
35 # 使用更新后的数据在query集上测试。loss填入loss_list_qry[1],预测正确数填入correct_list[1]
36 with paddle.no_grad():
37 y_hat = self.net(x_qry[i], fast_weights, bn_training=True)
38 loss_qry = F.cross_entropy(y_hat, y_qry[i])
39 loss_list_qry[1] += loss_qry
40 pred_qry = F.softmax(y_hat, axis=1).argmax(axis=1) # size = (75)
41 correct = paddle.equal(pred_qry, y_qry[i]).numpy().sum().item()
42 correct_list[1] += correct
43
44 # 剩余更新步数
45 for k in range(1, self.update_step):
46 y_hat = self.net(x_spt[i], params=fast_weights, bn_training=True)
47 loss = F.cross_entropy(y_hat, y_spt[i])
48 grad = paddle.grad(loss, fast_weights)
49 tuples = zip(grad, fast_weights)
50 fast_weights = list(map(lambda p: p[1] - self.base_lr * p[0], tuples))
51
52 if k < self.update_step - 1:
53 with paddle.no_grad():
54 y_hat = self.net(x_qry[i], params=fast_weights, bn_training=True)
55 loss_qry = F.cross_entropy(y_hat, y_qry[i])
56 loss_list_qry[k + 1] += loss_qry
57 else: # 对于最后一步update,要记录loss计算的梯度值,便于外循环的梯度传播
58 y_hat = self.net(x_qry[i], params=fast_weights, bn_training=True)
59 loss_qry = F.cross_entropy(y_hat, y_qry[i])
60 loss_list_qry[k + 1] += loss_qry
61
62 with paddle.no_grad():
63 pred_qry = F.softmax(y_hat, axis=1).argmax(axis=1)
64 correct = paddle.equal(pred_qry, y_qry[i]).numpy().sum().item()
65 correct_list[k + 1] += correct
66
67 loss_qry = loss_list_qry[-1] / task_num # 计算最后一次loss的平均值
68 self.meta_optim.clear_grad() # 梯度清零
69 loss_qry.backward()
70 self.meta_optim.step()
71
72 accs = np.array(correct_list) / (query_size * task_num) # 计算各更新步数acc的平均值
73 loss = np.array(loss_list_qry) / task_num # 计算各更新步数loss的平均值
74 return accs, loss
75
76 def finetunning(self, x_spt, y_spt, x_qry, y_qry):
77 # assert len(x_spt.shape) == 4
78 query_size = x_qry.shape[0]
79 correct_list = [0 for _ in range(self.update_step_test + 1)]
80
81 new_net = deepcopy(self.net)
82 y_hat = new_net(x_spt)
83 loss = F.cross_entropy(y_hat, y_spt)
84 grad = paddle.grad(loss, new_net.parameters())
85 fast_weights = list(map(lambda p: p[1] - self.base_lr * p[0], zip(grad, new_net.parameters())))
86
87 # 在query集上测试,计算准确率
88 # 这一步使用更新前的数据
89 with paddle.no_grad():
90 y_hat = new_net(x_qry, params=new_net.parameters(), bn_training=True)
91 pred_qry = F.softmax(y_hat, axis=1).argmax(axis=1) # size = (75)
92 correct = paddle.equal(pred_qry, y_qry).numpy().sum().item()
93 correct_list[0] += correct
94
95 # 使用更新后的数据在query集上测试。
96 with paddle.no_grad():
97 y_hat = new_net(x_qry, params=fast_weights, bn_training=True)
98 pred_qry = F.softmax(y_hat, axis=1).argmax(axis=1) # size = (75)
99 correct = paddle.equal(pred_qry, y_qry).numpy().sum().item()
100 correct_list[1] += correct
101
102 for k in range(1, self.update_step_test):
103 y_hat = new_net(x_spt, params=fast_weights, bn_training=True)
104 loss = F.cross_entropy(y_hat, y_spt)
105 grad = paddle.grad(loss, fast_weights)
106 fast_weights = list(map(lambda p: p[1] - self.base_lr * p[0], zip(grad, fast_weights)))
107
108 y_hat = new_net(x_qry, fast_weights, bn_training=True)
109
110 with paddle.no_grad():
111 pred_qry = F.softmax(y_hat, axis=1).argmax(axis=1)
112 correct = paddle.equal(pred_qry, y_qry).numpy().sum().item()
113 correct_list[k + 1] += correct
114
115 del new_net
116 accs = np.array(correct_list) / query_size
117 return accs
复现结果
小结
相关阅读

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~