随着深度学习技术的升级与产业的发展,智能语音交互已成为了我们日常生活中一个重要的组成部分,并广泛应用在地图导航播报、智能客服回访、手机语音输入以及各类智能助手等应用场景中,可以说语音已成为了人与机器之间交流的重要桥梁。
飞桨语音模型库PaddleSpeech,为开发者提供了语音识别、语音合成、声纹识别、声音分类等多种语音交互能力,代码全部开源,各类服务一键部署,并附带保姆级教学文档,让开发者轻松搞定产业级应用!
PaddleSpeech自开源以来,就受到了开发者们的广泛关注,Star数一路上扬。
在此过程中,我们也根据用户的反馈不断升级,推陈出新,优化用户体验。
本次,PaddleSpeech新版本发布,再次为开发者带来了三项重要升级:
全新发布,业界首个开源声纹识别与音频检索系统,10分钟轻松搭建产业级应用
语音识别、语音合成、声音分类,一键部署三项核心语音服务
新增大量前沿算法模型,原有模型效果全面升级
项目传送门:
https://github.com/PaddlePaddle/PaddleSpeech
1.PaddleSpeech的核心功能非常易用,按照首页的引导,选择简易模式即可安装。
2.执行如下五个命令轻松体验PaddleSpeech五项核心功能:
以语音合成服务为例,让我们来体验一下合成的效果吧:
基于如此简单的调用接口,飞桨开发者使用PaddleSpeech、PaddleGAN和PaddleHub组件快速开发的PaddleBoBo项目引发了广泛关注,元宇宙时代,借助飞桨,人人都能开发专属于自己的虚拟人。
戳下方视频观看PaddleBoBo为大家带来的
《我与飞桨的2021》
其中虚拟人的发音部分使用的就是PaddleSpeech开源的语音合成模型。除了语音合成能力以外,PaddleSpeech还开源语音识别、声纹识别、语音分类等多种语音能力,让我们的虚拟人不仅说的出,更能听得见!
本次重磅升级
这次更新,我们为大家带来业界首个开源的声纹识别与声音检索系统,命令行一键式服务部署功能,以及多个模型的优化升级。
1. 全新发布,业界首个开源声纹识别与音频检索系统,10分钟轻松搭建产业级应用。
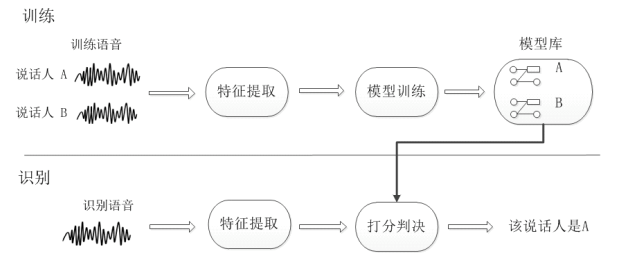
声纹特征作为生物特征,具有防伪性好,不易篡改和窃取等优点,配合语音识别与动态密码技术,非常适合于远程身份认证场景。在声纹识别技术的基础上,配合音频检索技术(如演讲、音乐、说话人等检索),可在海量音频数据中快速查询并找出相似声音(或相同说话人)片段。
其中声纹识别作为一个典型的模式识别问题,其基本的系统架构如下【1】:
PaddleSpeech这次开源的声纹识别与音频检索系统,集成了业界领先的声纹识别模型,使用ECAPA-TDNN模型提取声纹特征,识别等错误率(EER,Equal error rate)低至0.95%, 并且通过串联Mysql和Milvus,可以搭建完整的音频检索系统,实现毫秒级声音检索。
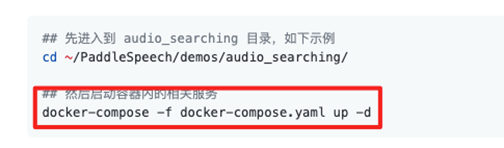
音频检索系统的搭建过程也非常简单,仅需四步即可完成,我们一起来体验一下吧!
Demo使用展示:
a)安装好PaddleSpeech后,在PaddleSpeech根目录下,进入demos/audio_searching文件夹。构建数据库环境并启动Docker服务。
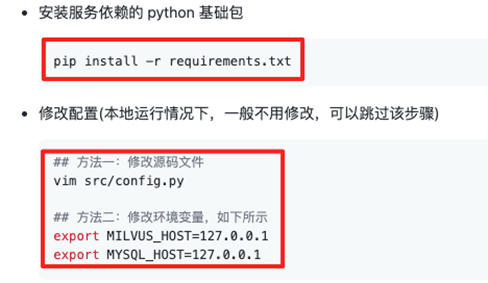
b)安装相关依赖并根据本机环境配置相关参数。
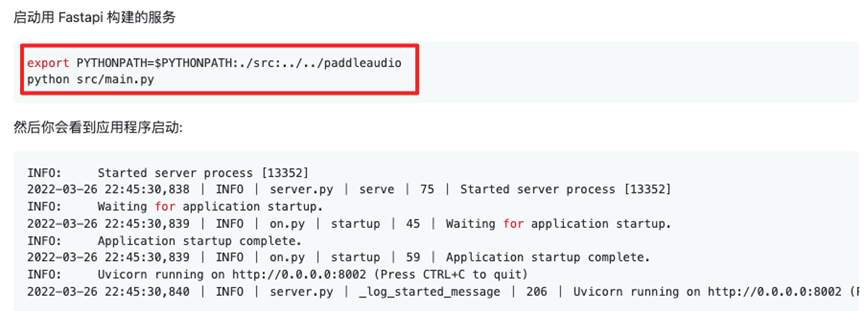
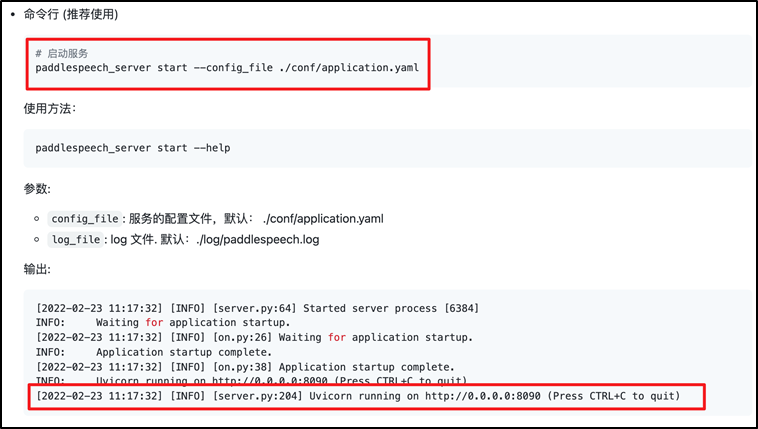
c)启动服务。
d)通过浏览器访问本机 8002 端口进入Audio Searching界面。
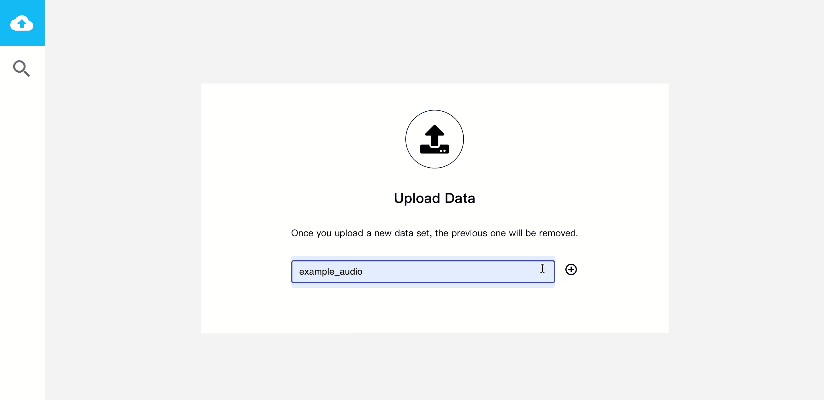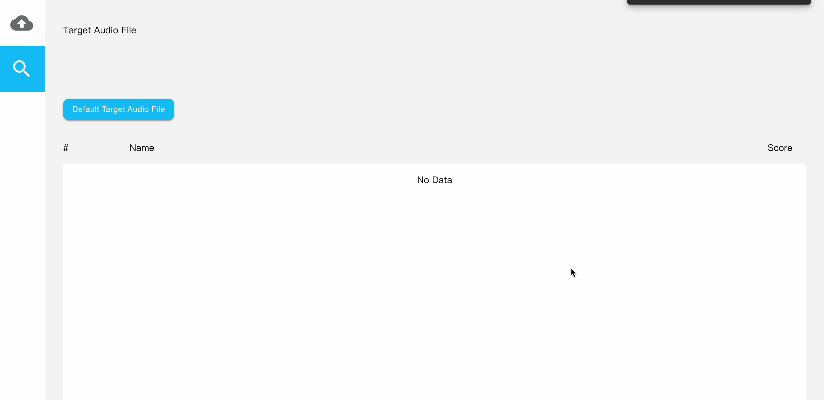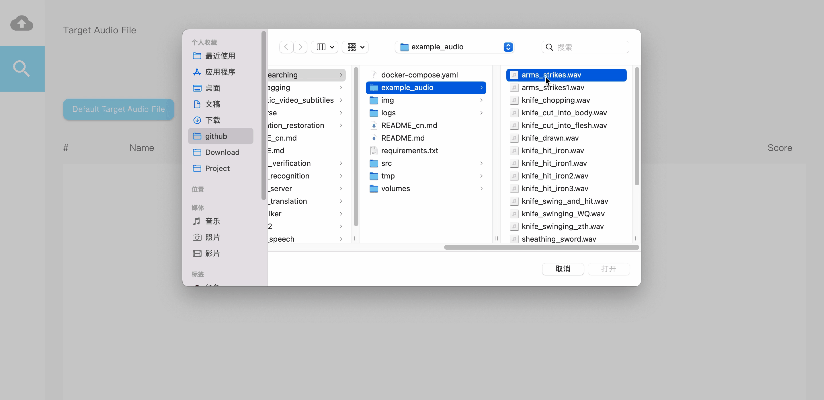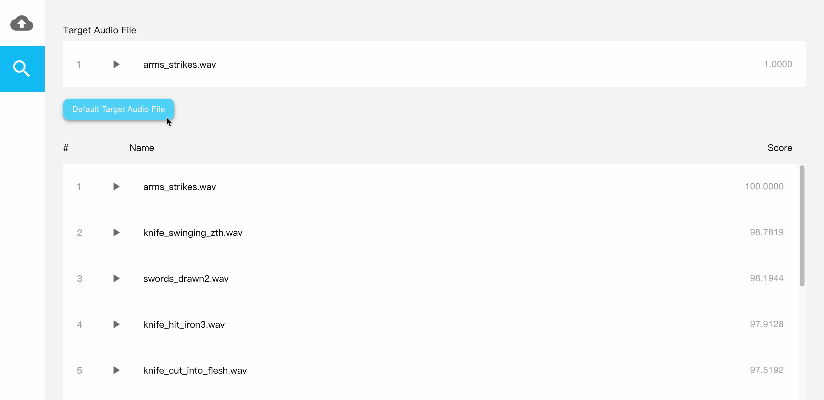
上传音频数据后,选择待检索的音频,得到声纹比对情况,评分越高,匹配程度越大。几行代码,轻松搞定声纹识别服务,赶紧来试试吧!
2. 语音识别、语音合成、声音分类,一键命令部署三项核心语音服务
在产业应用中,将训练好的模型以服务的形式提供给他人使用可以更方便。考虑到搭建一套完整的网络服务应用是一件繁琐的工作,PaddleSpeech为大家提供了一键式部署服务,命令行一行代码即可同时启动语音识别,语音合成,语音分类三大服务。
Demo使用及展示:进入 demo/speech_server 目录下,一键启动语音识别、语音合成、语音分类服务。
此时服务已经挂载到了配置的8090端口了,我们可以通过命令行对服务进行调用。
客户端调用,以语音识别为例:
识别结果:
语音合成与分类的服务使用类似,可以参考对应的文档。
3. 新增大量前沿算法模型,已有模型效果全面升级
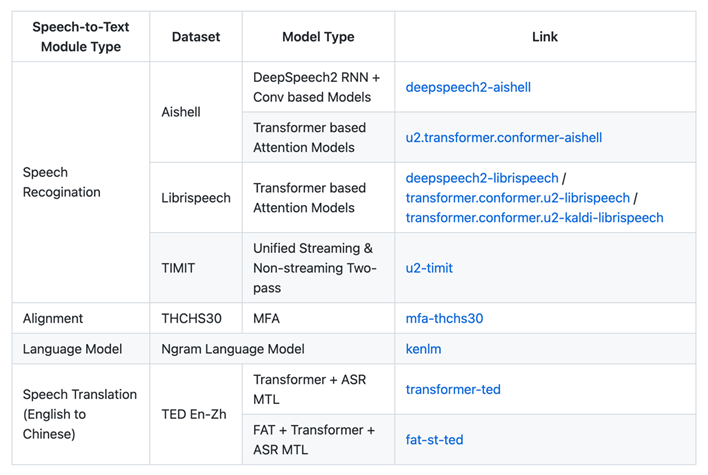
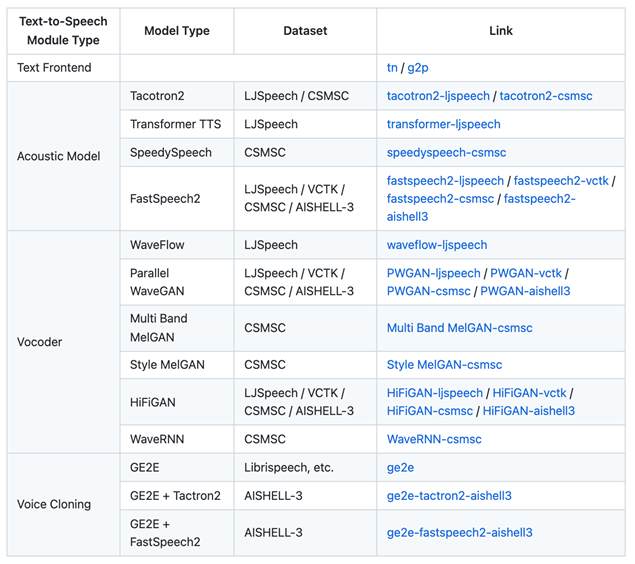
除了上面各种功能之外,PaddleSpeech为开发者提供了丰富的预训练模型。
语音识别:Conformer语音识别模型优化升级,在离线环境下,Aishell数据集上识别正确率达 95% 以上
语音合成:新增多个预训练模型,合成效果全面提升,支持中英两种语言;前端优化,文字转拼音准确率进一步提高。
语音分类:新增开源PANN模型,在 ESC-50数据集上,分类准确率达95%。
声纹识别:新增开源ECAPA-TDNN模型,在VoxCeleb数据集上等错误率EER(Equal Error Rate)0.95%。
标点恢复: 开源基于ERNIE的中文标点恢复模型。
完善的文档教程
这么好的项目,欢迎大家点star鼓励并前来体验!
https://github.com/PaddlePaddle/PaddleSpeech
欢迎更多热爱语音技术的开发者们
一起加入PaddleSpeech的社区交流
微信扫描二维码加入官方交流群
获得更高效的问题答疑
与各行各业开发者充分交流
期待您的加入
(如果二维码过期,可以到GitHub首页查找二维码加群)

不忘初心 致谢开发者
PaddleSpeech开源以来,受到开发者的广泛关注,已经有大量开发者投入到项目的建设中并且贡献内容,感谢各位,我们一起努力!
PaddleSpeech项目地址:
GitHub:
https://github.com/PaddlePaddle/PaddleSpeech
Gitee:
https://gitee.com/paddlepaddle/PaddleSpeech
参考文献:
[1]郑方. 声纹识别技术及其应用现状[J]. 信息安全研究, 2016, 2(1): 44-57.
相关阅读

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~