
人工智能时代,越来越多的企业正在应用AI技术开展智能化转型。其中,NLP技术拥有非常广泛的行业应用场景,包括信息检索、推荐、信息流、互联网金融、社交网络等。通过NLP技术的应用,可以支持情感分析系统对海量带有情感色彩的主观性文本进行分析、处理、归纳和推理,提供用户洞察,辅助决策;可以支持检索系统帮助用户快速在海量数据中找到自己需要的信息,实现知识的搜索、发现和利用。
本次飞桨产业实践范例库开源
评论观点抽取与分析、文本语义检索
两个NLP技术典型场景应用,提供了从数据准备、模型训练优化,到模型部署的全流程可复用方案,降低产业落地门槛。
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications
所有源码及教程均已开源,欢迎大家
star鼓励
~
情感分析旨在对带有情感色彩的主观性文本进行分析、处理、归纳和推理,其广泛应用于消费决策、舆情分析、个性化推荐等领域,具有很高的商业价值。一种细粒度情感分析方案:评论观点抽取与分析范例,此方案不仅能分析出商品具体属性的好坏,同时能帮助用户定位详细的评价观点。

评论属性观点繁多
:评论中可能存在某个商品的多个属性,同时每个属性可能会存在多个观点词,需要同时抽取属性和观点词,同时将属性和相应观点词进行有效匹配。
模型情感信息敏感度低
:模型在训练过程中,可能对某些样本中的关键情感信息不敏感,导致抽取或预测准确度不高。
数据少且标注困难
:评论观点抽取相关训练数据较少,且相关数据集标注较为困难。
模型预测效率要求高
:业务数据累积较多,期望对数据进行高效高精度分析处理。
针对上述难点,本项目提出的的情感分析解决方案如下图所示,整个情感分析的过程大致包含两个阶段,依次是评论观点抽取模型,属性级情感分类模型。
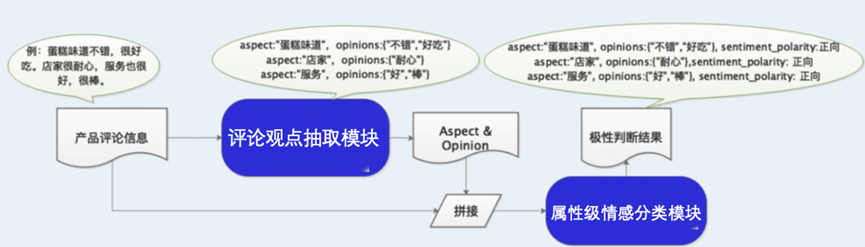
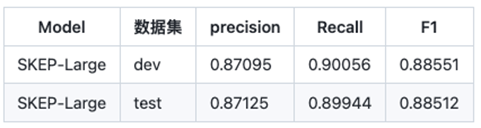
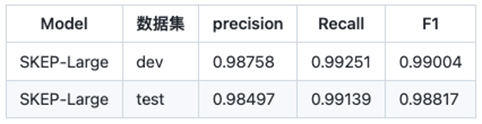
本项目使用了百度自研的 SKEP 预训练模型,其在预训练阶段便设计了多种情感信息相关的预训练目标进行训练,作为一种情感模型,其更适合用于评论观点抽取任务,以及属性级情感分类任务。
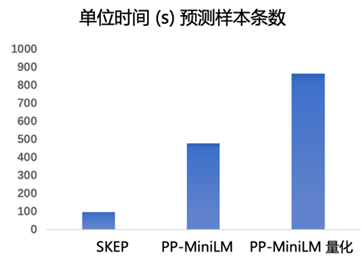
为了提升模型预测效果,本项目采用了
PaddleNLP
联合
PaddleSlim
发布的模型蒸馏、剪裁、量化等级联模型压缩方案。
此外,本项目还定义了简便的数据标注规则,并打通了Doccano数据标注平台,本项目可以直接对Doccano的导出数据进行自动处理,转化为适合模型输入的形式,方便易用。
考虑到不同用户可能有不同的需求,本范例提供了如下的方式学习或使用本项目。
检索系统已经是我们日常生活中获取信息的不可或缺的一部分,在我们的生活中,有很多地方都有检索系统的身影,除了百度等搜索引擎以外,还有在电商购物的搜索,知乎的站内搜索,微信的视频和公众号文章的搜索,以及万方、知网的科研文献搜索等等,这些场景都离不开搜索技术。
本次开源的范例项目开源了一套低门槛、端到端的检索系统方案,可以在多场景快速部署实现搜索功能。无标注数据,仅有无监督数据也可以得到一个效果不错的文本语义检索模型。
句级别语义鸿沟
:基于关键词检索的方法优化起来较为繁琐,不能很好的对句子级别的语义信息进行建模,无法跨越句子级别的语义鸿沟。
数据少标注成本高
:在系统搭建初期或者数据体量比较小的场景,并没有很多标注好的句子对,且标注的成本很高。
语义检索系统方案复杂
:语义监测方案是一个系统性工程,需要了解完整的检索系统流程是什么,如何评估检索系统的好坏,如何调优等等。
针对上述难点,本项目最终选用了PaddleNLP的Neural Search中的技术方案,并且使用飞桨服务化部署框架Paddle Serving 进行服务化部署。
Neural Search是一个实用的完整的文本语义检索应用,主要由召回和排序两个模块组成。该应用从实际的痛点出发,然后涉及网络选择和调整、策略增强、超参数调节、预训练模型使用5个方面,对各个模块的模型进行优化,并经过千万级别的数据预训练,百万级别的数据进行无监督训练,最终在GPU上预测时间可达到毫秒级别。
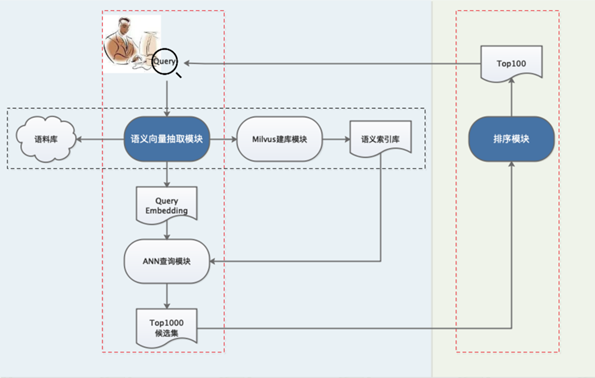
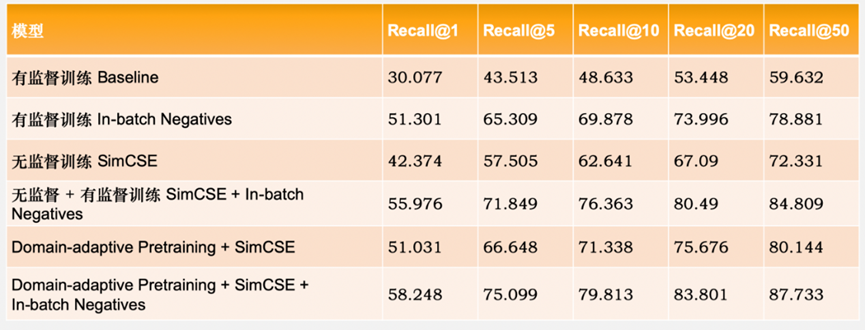
本方案的NLP核心能力基于百度文心大模型。首先利用文心 ERNIE 1.0 模型进行 Domain-adaptive Pretraining,在得到的预训练模型基础上,进行无监督的 SimCSE 训练,最后利用 In-batch Negatives 方法进行微调,得到最终的语义索引模型,把语料库中的文本放入模型中抽取特征向量,进行建库之后,就可以很方便得实现召回了。以Recall@50指标进行评估,召回模型效果可以达到87.7%。
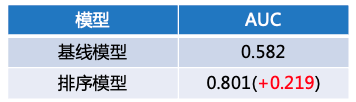
排序模型使用了百度文心大模型中最新的文心ERNIE-Gram模型,相比于基线方法,有不小的提升:
部署方面使用配备Paddle Serving的C++和Pipeline方式的灵活部署,满足用户批量预测、数据安全性高、延迟低的需求,快速在本地完成部署方案,本次范例包含模型转换配置到部署请求的全流程讲解,欢迎小伙伴们关注直播。
PaddleNLP是百度飞桨自然语言处理模型库,具备易用的文本领域API、丰富的预训练模型、多场景的应用示例、以及依托飞桨框架底层算子优化的高性能推理能力,旨在提升开发者在文本领域的开发效率。PaddleNLP提供了语义检索、情感分析、FAQ问答等产业级系统方案,采用前沿技术方案,打通数据标注、模型预训练及微调、部署全流程,十分简单易用,极大地降低开发门槛。
为了让小伙伴们更便捷地实践和应用以上两个场景方案,百度高工将于
4月20日
和
4月21日19:00
为大家深度解析从数据准备、方案设计到模型优化部署的开发全流程,手把手教大家进行评论观点抽取及分析和文本语义检索落地应用的代码实践。
欢迎小伙伴们扫码进群,免费获取直播课和回放视频链接,
更有机会获得覆盖智慧城市、工业制造、金融、互联网等行业的飞桨产业实践范例手册!
也欢迎感兴趣的企业和开发者与我们联系,交流技术探讨合作。

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~


