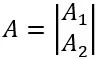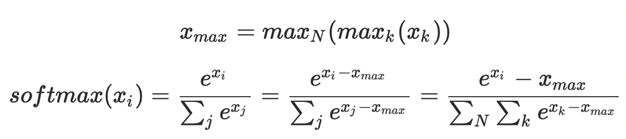随着模型规模的扩大,单卡显存容量无法满足大规模模型训练的需求。张量模型并行是解决该问题的一种有效手段。本文以Transformer结构为例,介绍张量模型并行的基本原理。
我们在上一篇《数据并行:提升训练吞吐的高效方法|深度学习分布式训练专题》详细介绍了利用数据并行进行大规模分布式训练。读者不禁要问:仅仅使用数据并行,是否可以完全满足大模型训练的要求?随着技术的发展,业界内训练的模型越来越大,模型朝着更深和更宽的方向发展。以自然语言处理(NLP)领域为例,模型从Bert发展到GPT,模型规模从数亿参数量增加到数百亿甚至是数千亿。当参数规模为千亿时,存储模型参数就需要数百GB的显存空间,超出单个GPU卡的显存容量。显然,仅靠数据并行无法满足超大规模模型训练对于显存的需求。为了解决这个问题,可以采用模型并行技术。与数据并行在不同设备都有完整的计算图不同,模型并行是不同设备负责单个计算图不同部分的计算。
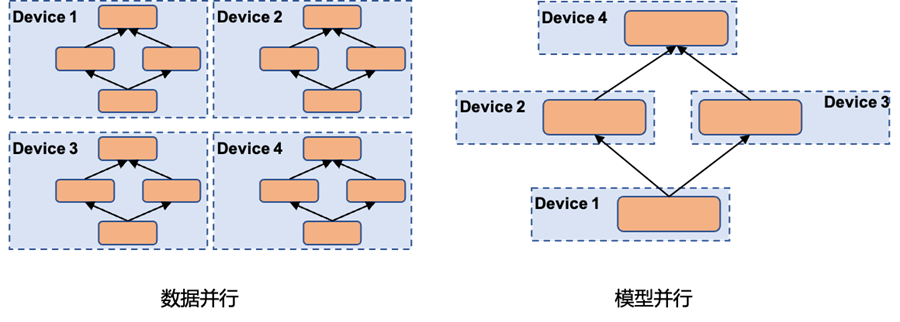
模型并行从计算图的切分角度,可以分为以下几种:
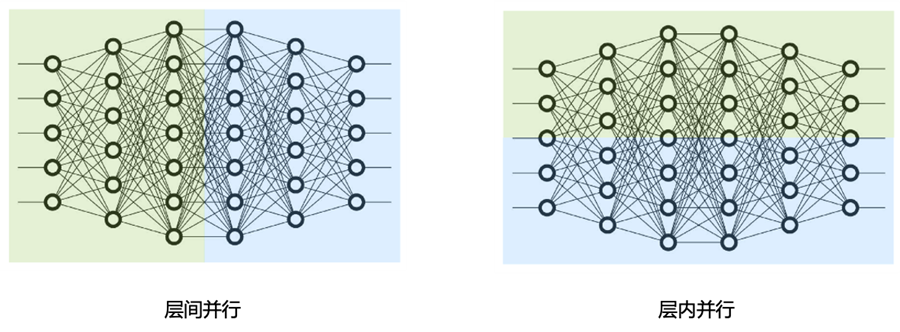
1、按模型的layer层切分到不同设备,即层间并行,我们称之为流水线并行,如下左图[1]。
2、将计算图中的层内的参数切分到不同设备,即层内并行,我们称之为张量模型并行,如下右图[1]。本文主要讲述张量模型并行。
张量模型并行原理
张量模型并行需要解决两个问题:参数如何切分到不同设备(切分方式);以及切分后,如何保证数学一致性(数学等价))。本文以NLP中的Transformer结构为例,介绍张量模型并行的切分方式和随机性控制。
切分方法
Transformer结构主要由嵌入式表示(Embedding)层、矩阵乘层(MatMul)和交叉熵loss计算层(CrossEntropy)构成。以上三种类型的组网层有较大的特性差异,需要设计对应的张量模型并行策略,但总体上看核心思想都是利用分块矩阵的计算原理,实现其参数切分到不同的设备[2]。下面详细介绍这三种层的切分方式。
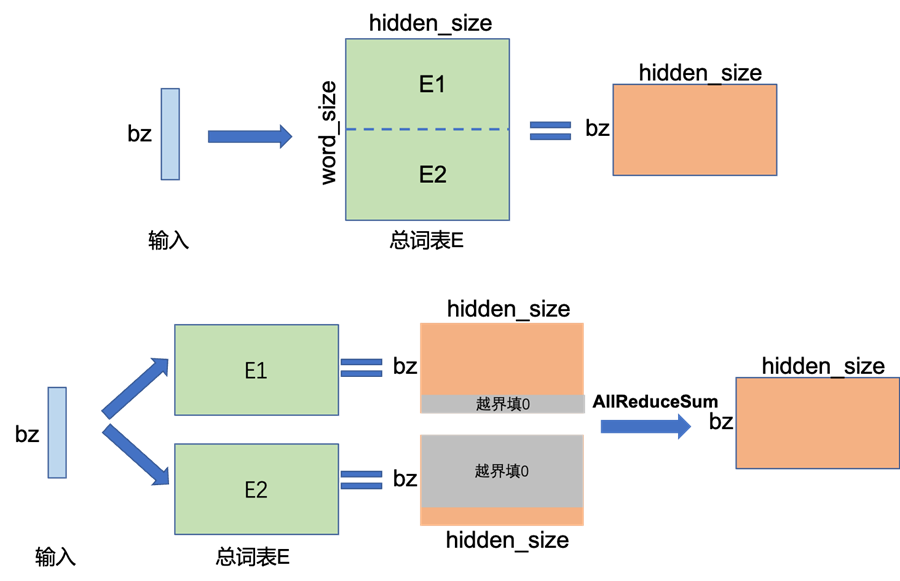
对于Embedding算子,如果总的词表非常大,会导致单卡显存无法容纳Embedding层参数。举例来说,当词表数量是50304,词表表示维度为5120,类型为FP32,那么整层参数需要显存大约为50304*5120*4/1024/1024=982MB,反向梯度同样需要982MB,仅仅存储就需要将近2GB。对于Embeeding层的参数,可以按照词的维度切分,即每张卡只存储部分词向量表,然后通过AllReduce汇总各个设备上的部分词向量结果,从而得到完整的词向量结果。
上图描述了单卡Embedding和Embedding两卡张量模型并行的示意图。在单卡上,执行Embedding操作,bz是batch size大小,Embedding的参数大小为[word_size, hidden_size],计算得到[bz, hidden_size]张量。下图为Embedding张量模型并行示例,其将Embedding参数沿word_size维度,切分为两块,每块大小为[word_size/2, hidden_size],分别存储在两个设备上,即每个设备只保留一半的词表。当每张卡查询各自的词表时,如果无法查到,则该词的表示为0,各自设备查询后得到[bz, hidden_size]结果张量,最后通过AllReduce_Sum通信,跨设备求和,得到完整的全量结果,可以看出,这里的输出结果和单卡执行的结果一致。
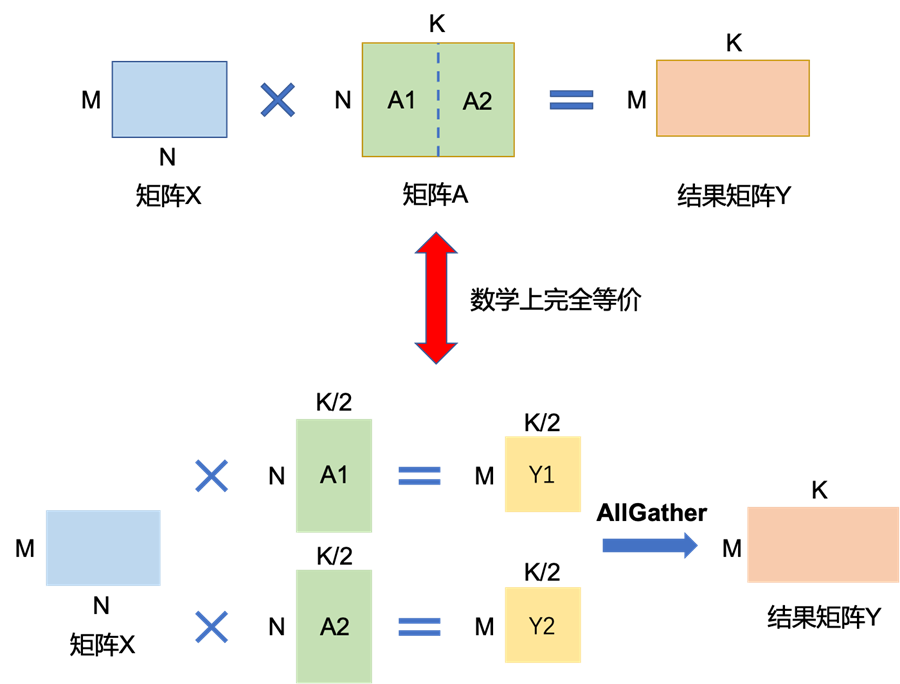
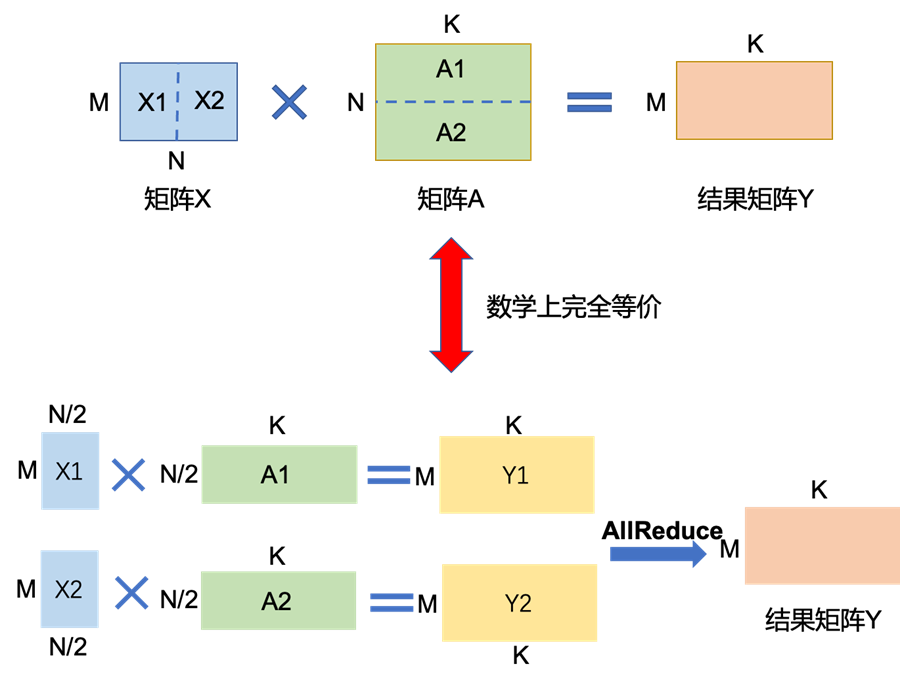
矩阵乘的张量模型并行充分利用矩阵分块乘法的原理。举例来说,要实现如下矩阵乘法Y=X*A,其中X是维度为MxN的输入矩阵,A是维度为NxK的参数矩阵,Y是结果矩阵,维度为MxK。如果参数矩阵A非常大,甚至超出单张卡的显存容量,那么可以把参数矩阵A切分到多张卡上,并通过集合通信汇集结果,保证最终结果在数学计算上等价于单卡计算结果。这里,参数矩阵A存在两种切分方式:
参数矩阵A按列切块。如下图所示,将矩阵A按列切成
分别将A1,A2放置在两张卡上。两张卡分别计算Y1=X*A1和Y2=X*A2。计算完成后,通过collective通信AllGather(一种跨GPU卡的通信方式),获取其它卡上的计算结果,拼接在一起得到最终的结果矩阵Y。综上所述,通过将单卡显存无法容纳的矩阵A拆分,放置在两张卡上,并通过多卡间通信,即可得到的最终结果。该结果在数学上与单卡计算结果上完全等价。
参数矩阵A按行切块。如下图所示,将矩阵A按行切成
为了满足矩阵乘法规则,输入矩阵X需要按列切分X=[X1 | X2]。同时,将矩阵分块,分别放置在两张卡上,每张卡分别计算Y1=X1*A1,Y2=X2*A2。计算完成后,通过collective通信Allreduce_sum,归约其他卡上的计算结果,可以得到最终的结果矩阵Y。同样,这种切分方式,既可以保证数学上的计算等价性,并解决单卡显存无法容纳,又可以保证单卡通过拆分方式可以装下参数A的问题。
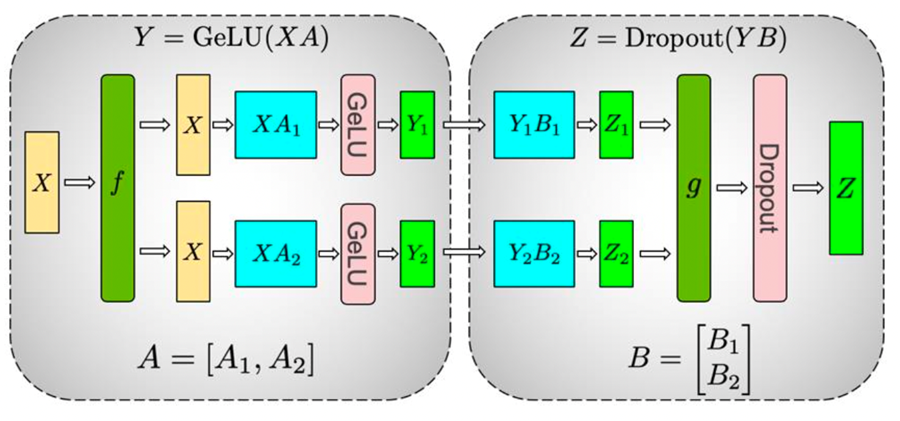
Transformer中的FFN结构均包含两层全连接(FC)层,即存在两个矩阵乘,这两个矩阵乘分别采用上述两种切分方式,如下图所示。对第一个FC层的参数矩阵按列切块,对第二个FC层参数矩阵按行切块。这样第一个FC层的输出恰好满足第二个FC层数据输入要求(按列切分),因此可以省去第一个FC层后的AllGather通信操作。
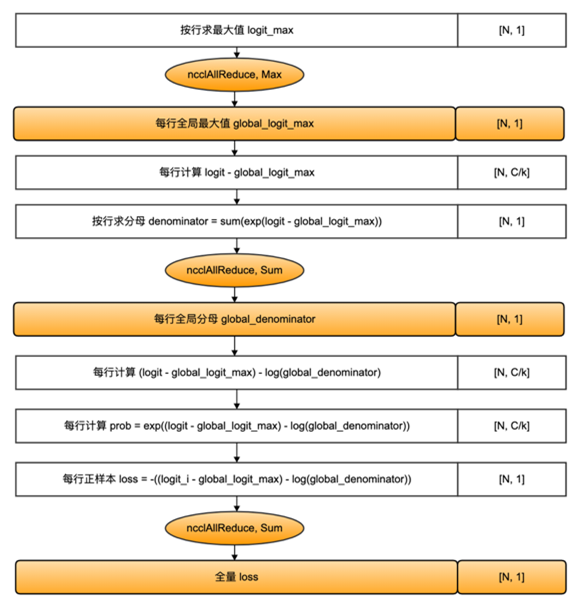
分类网络最后一层一般会选用softmax和cross_entropy算子来计算交叉熵损失。如果类别数量非常大,会导致单卡显存无法存储和计算logit矩阵。针对这一类算子,可以按照类别数维度切分,同时通过中间结果通信,得到最终的全局的交叉熵损失。
首先计算的是softmax值,如下公式,其中N表示张量模型并行的设备号
得到softmax之后,同时对标签target按类别切分,每个设备得到部分loss,最后在进行一次通信,得到全量的loss。整个过程,只需要进行三次小量的通信,就可以完成CrossEntropyLoss的计算,流程图如下所示:
具体的计算步骤如下图所示。
随机性控制
通过上面的分析发现,只需要对参数切分,并在算子实现层面加入额外的通信算子,可以实现张量模型并行。为了保证数学一致性,除了添加跨设备的通信外,还需要额外考虑由于模型切分到不同设备而带来的问题。
由于张量模型并行实际目的,是解决单设备无法运行大模型的问题,因此,张量模型并行虽然在多个设备上运行,其运行的结果需要完全等价单设备运行。为了等价单设备模型初始化,张量模型并行需要对随机性进行控制。张量模型并行的随机性主要分为两种:参数初始化的随机性和算子计算的随机性。下面,我们将分别介绍这两类随机性。
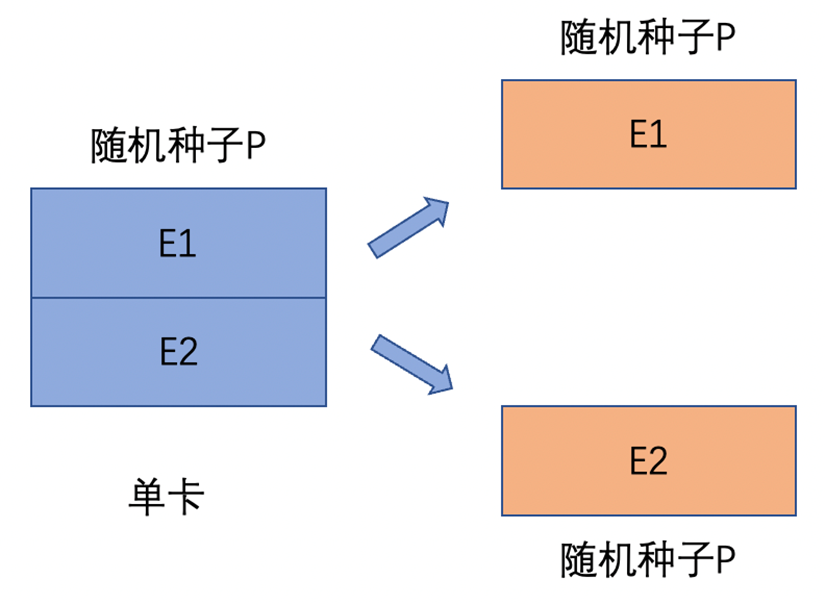
多卡的参数初始化要等价于单卡初始化结果。下图就是一个典型的错误示范:如果将一个设备的参数E,按照张量模型并行切分到2个设备上,分别为E1和E2,同时这两个设备的随机种子相同均为P,那么参数初始化后,两个设备的参数将会初始化为相同的数值,显然这和起初一个设备上参数E数学不等价,或者说它失去了一半的随机性。
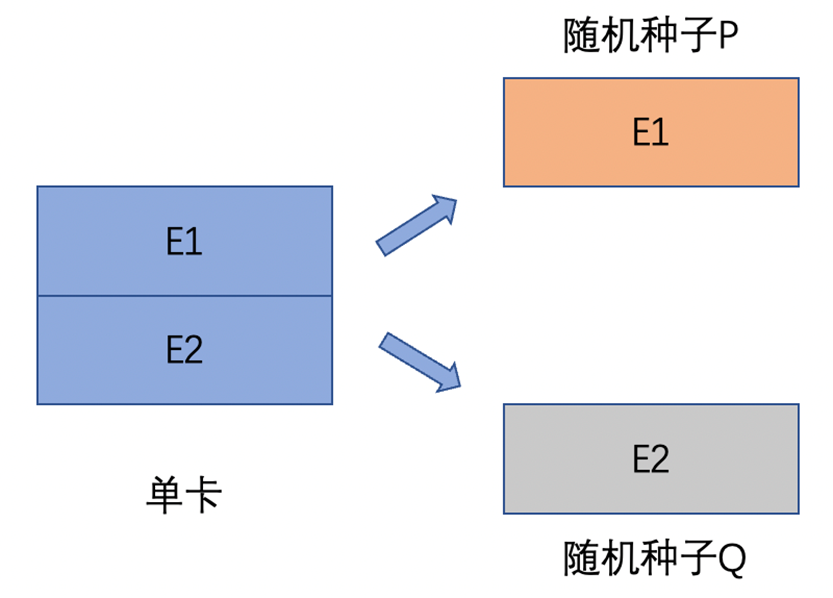
正确的做法,应该将参数切分到多个卡上后,再修改相应卡的随机性,保证各个卡的随机种子不同,这样从随机角度而言,多卡参数初始化的随机性与单卡相同。如下图所示,切分到不同设备后,卡1随机种子为P,卡2随机种子为Q,保证两者不同:
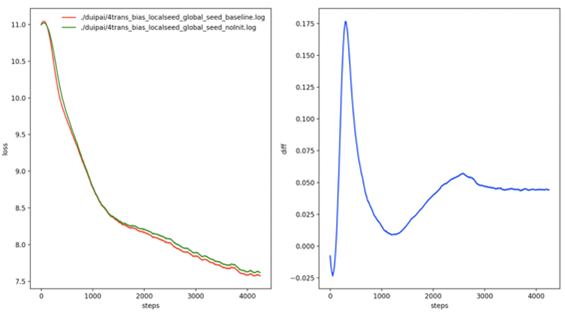
在实现了张量模型并行的Transformer结构。如果错误方法,使用相同的随机种子初始化各卡的参数,那么将严重影响收敛效果,如下图所示。其中,绿色曲线表示多卡训练loss曲线,红色曲线表示单卡训练loss曲线;可以看出多卡训练的loss曲线下降速度逐渐变慢。
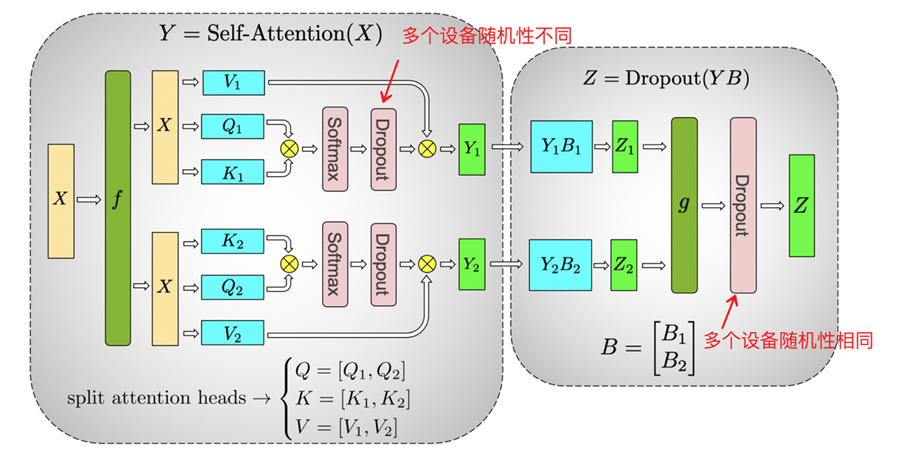
Dropout是常见的具有随机性的算子。在张量模型并行和该算子结合使用时,需要特别注意对该算子随机性的控制。例如,Transformer结构的self-attention模块中就大量使用了Dropout算子,根据使用的位置不同,Dropout将存在两种随机性,需要利用两套随机种子进行控制。
如上图的Self-Attention结构中包含了两类Dropout操作。其中,左侧的Dropout操作的对象是切分矩阵的中间计算结果,该结果在不同的切分设备上是不同的,因此需要保证不同卡上随机种子不同。与之不同,对于右侧的Dropout (Z=Dropout(YB))而言,Y*B矩阵乘后,调用了AllGather,保证所有卡的都得到了相同的计算结果,之后在经过Dropout后,需要保证各个卡之间的结果不变,因此这个Dropout的随机种子需要在多卡下是相同的。
总结
综上所述,本文讲述了Transformer模型中的张量模型并行,通过将计算图的参数切分到多个设备上,然后通过额外的设备间通信,解决模型训练的显存消耗超过单卡显存容量的问题,再结合随机性的控制,保证计算结果在数学上和单设备结果的一致。上述的实现方式实现简单,也便于拓展到其他模型中,但是模型中存在大量无法切分的layer层,那么会增加大量的冗余计算,需要设计更通用的张量模型并行方案。感兴趣的同学欢迎点击链接(https://github.com/PaddlePaddle/FleetX)深入了解张量模型并行。
相关阅读
问卷调研
由白玉兰开源开放社区携手飞桨社区发起《中国AI开发者调研》,探索国内AI产业落地现状,预期于2022年世界人工智能大会发布相关报告。欢迎各位开发者朋友积极参与问卷,30%概率获得100元京东e卡的奖励!扫描下方二维码或点击阅读原文即可参与!

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~