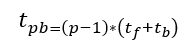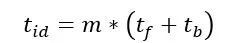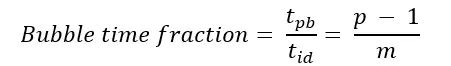实践证明,更大的模型在不少场景取得了更好的效果。但随着参数规模的扩大,AI加速卡存储(如GPU显存)容量问题和卡的协同计算问题成为了训练超大模型的瓶颈。流水线并行从模型切分和调度执行两个角度解决了这些问题。本文将从流水线并行介绍、主流实现方式以及一般调优技巧三方面从浅到深讲解流水线并行,希望能帮助您更好地理解和使用流水线并行功能。
模型切分一般有两种方式:参数(Tensor)切分和图切分。在上一篇张量模型并行中介绍过,张量模型并行可以把shape较大的参数(Tensor)切分到多个卡,从而有效减小在每个卡上的参数量。但是,采用这种方式单机8卡(V100,32GB)最多训练10B左右的Dense模型,而且由于其通信和计算不能重叠的特点一般不适合多机之间使用。更大的模型需要从层(Layer)级别进行进一步的图切分以减少单卡存储的容量需求,同时隐藏卡之间的通信时间,更加充分利用GPU卡的算力。为此业界提出了流水线并行的方式解决上述切分和调度的问题。
流水线并行介绍
图(a)
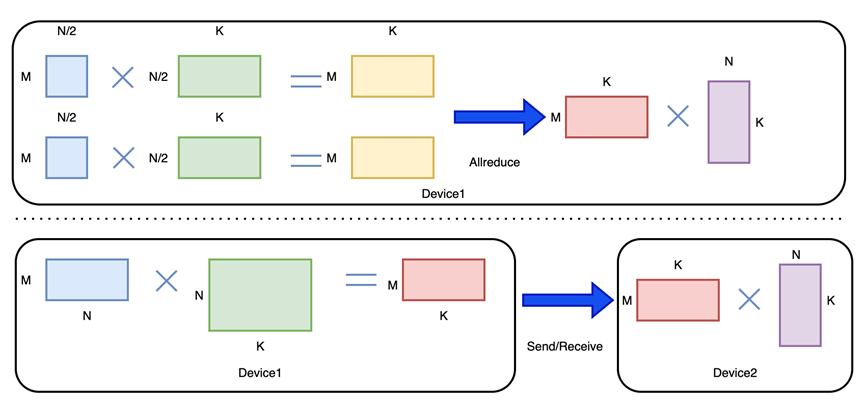
广义上讲,流水线并行从图切分的角度,将模型进一步按层切分到不同的设备上,相邻设备间在计算时只需要传递邻接层的中间变量和梯度。如上图(a)所示,这里引用上一篇张量模型并行中矩阵乘的介绍,对FFN(Feedforward Network)采用张量模型并行,把fc层参数切分到设备内的不同卡上,在同一设备内进行Allreduce求和的全量通信参数为 2*M*K(M:矩阵行维度, K:矩阵列维度)。而采用流水线并行将FFN层作为切分点切分模型层,在device间只需要 send/receive (发送\接收)M*K 的参数量,因此相比张量模型并行,流水线并行通信参数量更少。如下图(b)所示,以Gpipe论文中的示例进行说明,朴素的流水线并行,同一时刻只有一个设备进行计算,其余设备处于空闲状态,计算设备利用率通常较低。
图(b)
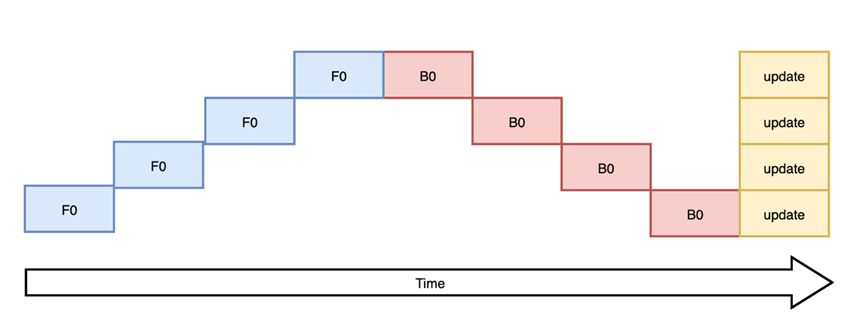
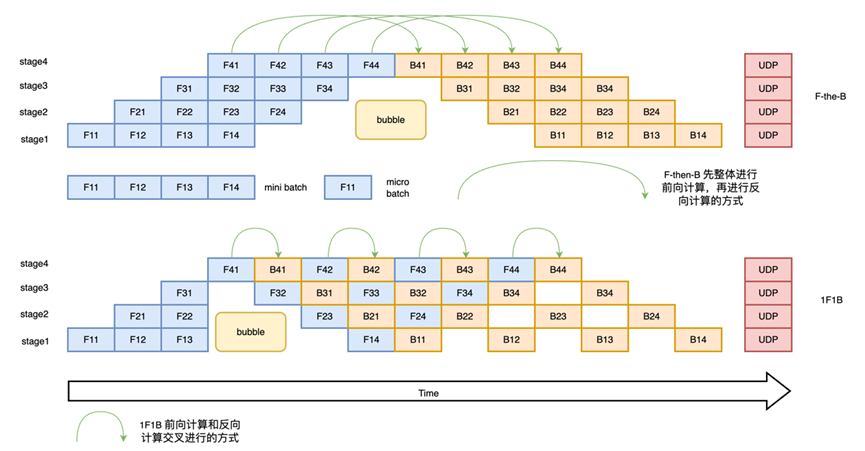
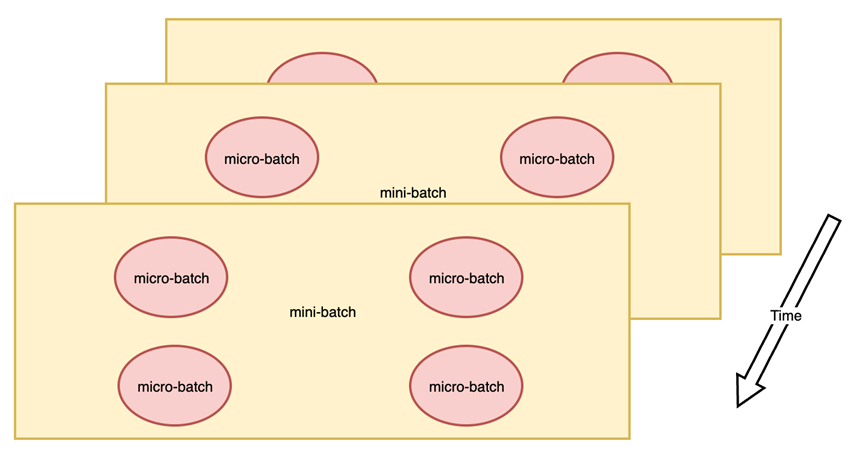
与之相对应,将朴素流水线并行的 batch 再进行切分,减小设备间空闲状态的时间,可以显著提升流水线并行设备利用率。如图(c)F-then-B 调度方式所示,将原本的 mini-batch(数据并行切分后的batch)划分成多个 micro-batch(mini-batch再切分后的batch),每个 pipeline stage (流水线并行的计算单元)先整体进行前向计算,再进行反向计算。通过在同一时刻分别计算模型的不同部分,F-then-B 可以显著提升设备资源利用率。但也不难看出这种 F-then-B 模式由于缓存了多个 micro-batch 的中间变量和梯度,显存的实际利用率并不高。
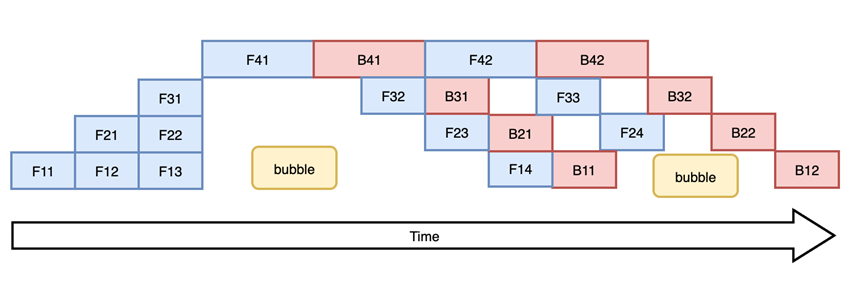
由此产生出 1F1B (在流水线并行中,pipeline stage 前向计算和反向计算交叉进行的方式)流水线并行方式解决了这个问题。在 1F1B 模式下,前向计算和反向计算交叉进行,可以及时释放不必要的中间变量。我们以下图(c)1F1B中 stage4 的 F42(stage4的第2个 micro-batch 的前向计算)为例,F42 在计算前,F41 的反向 B41(stage4的第1个 micro-batch 的反向计算)已经计算结束,即可释放 F41 的中间变量,从而 F42 可以复用 F41 中间变量的显存。1F1B 方式相比 F-then-B 方式峰值显存可以节省37.5%,对比朴素流水线并行峰值显存明显下降,设备资源利用率显著提升。
图(c)
F-then-B和 1F1B 调度方式都采用增加 batch 数量,即将 mini-batch 切分为 micro-batch 增加设备资源利用率。下面我们从 micro-batch 角度从理论上推导下计算空闲,即 bubble 和 micro-batch 实际计算时间之间的关系。引用 NVIDIA 在其训练超大语言模型论文对于 bubble 时间的计算公式:
其中:
tpb: 一个 mini-batch 中bubble的时间, p:pipeline stage的数量
其中:
由上述两个公式可以得到:
由此不难看出,在pipeline stage数p一定的情况下,影响 bubble 占比的是一个 mini-batch 中 micro-batch的数量 m 。在保证 m >> p 的情况下,可以有效降低 bubble 占比。
流水线并行实现
飞桨分别实现了上面介绍过的 F-then-B 和 1F1B 两种流水线调度方式。虽然 1F1B 方式显存利用率高于 F-then-B 的方式,但是 1F1B 实现比较复杂,使用门槛比较高,需要用户明确自己模型在哪些位置需要做通信;而 F-then-B 的实现相对 1F1B 更加简单,通信不容易出现问题,因此建议用户调模型时选择 F-then-B 流水线调度方式,性能优化时再改为 1F1B 调度方式。在实现流水线并行策略时,飞桨主要针对调度执行环节做了一些优化设计。下面我们从通信调度、显存调度两方面分别进行介绍。
通信调度
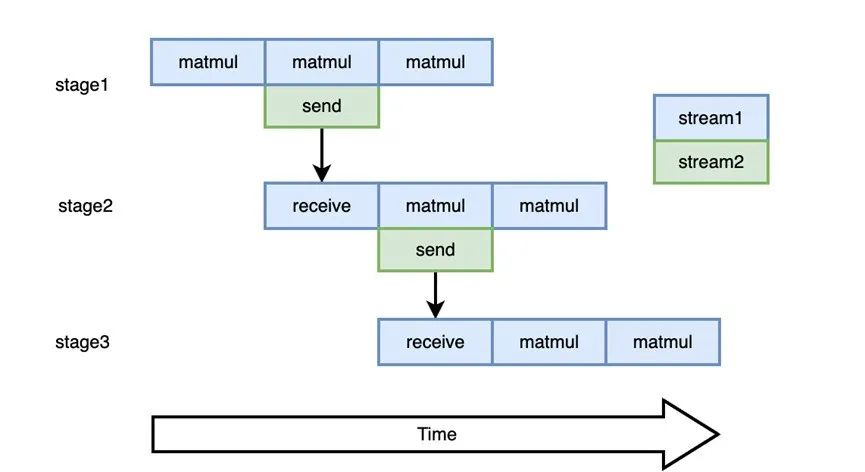
首先,从模型切分角度来考虑,通过流水线并行切分后的模型仍然可以看作是一个完整的计算图;只不过需要用通信来串联起每个计算单元,即 pipeline stage。这里我们可以简单理解,由于在相邻 pipeline stage 间需要交互中间变量和梯度,不可避免需要对交互后的变量进行同步操作,保证交互的变量已经被发送或是接收。如果我们只是在单一计算流(计算进程)进行这一操作,那么增加的通信操作无疑会增加不必要的计算空闲。所以我们在实现时,对于不同 pipeline stage 做不同流的 send\receive(发送\接收)操作,如下图(d)所示。在计算流进行第二步 matmul 计算时,同时在通信流(通信进程)发送第一步 matmul 运算后的中间变量结果给下一个 pipeline stage。通过在时间维度复用计算和通信操作,可以有效减少计算空闲,显著提升流水线并行效率。
图(d)
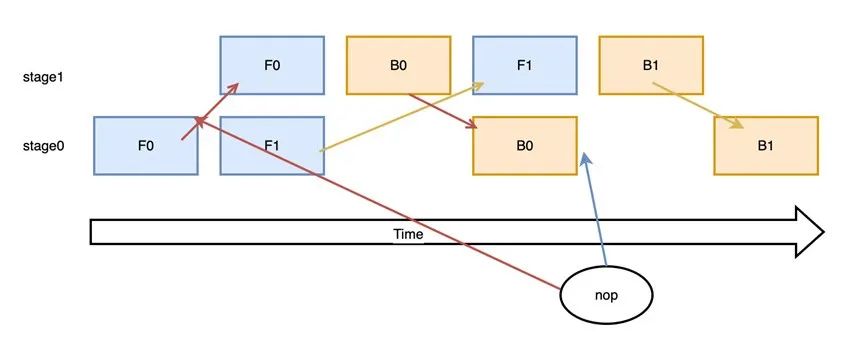
正如上文介绍的,流水线并行由于采用多流通信机制。通常需要在每个 micro-batch 的反向阶段增加同步操作,保证当前 micro-batch 在前向阶段向下一个 pipeline stage 传输的变量已经被接收。这样的同步操作往往也增加了很多不必要的通信调度时间。如下图(e)所示,飞桨在实现多流通信时,为了通信和计算可以更好的 overlap;通过拓扑分析,在 micro-batch 的 receive 之后增加 nop op(nop的蓝色箭头),hold住同 micro-batch 前向 send 变量(nop的红色箭头),取消一次同步操作。经测试在同样规模的模型下,由于在调度侧减少同步op的数量,并通过垃圾回收机制控制变量的生命周期。调度时间和峰值显存都有明显下降。
图(e)
显存调度
图(f)
进而还可以发现,由于 mini-batch 被切分为多个 micro-batch,如果对每个 micro-batch 都进行参数更新,无疑在计算和显存上会增加大量开销。为了进一步降低计算和显存开销,飞桨对同一 mini-batch 下的 micro-batch 先进行梯度累加,再统一更新参数。具体来说,就是使用 mirco-batch 数据进行训练,即通过“前向+反向”网络计算得到梯度,其间会有一部分显存/内存用于存放梯度,然后对每个 micro-batch 计算出的梯度进行累加,当累加的次数达到 acc_step (需要梯度聚合的step数)时,使用累加的梯度对模型进行参数更新,从而达到 mini-batch 数据训练的效果。
在宏观上看,梯度累加是将训练一个 mini-batch 的过程由原来的 “前向 + 反向 + 更新” 改变成 “(前向 + 反向 + 梯度累加)* k + 更新”,通过在最终更新前进行k 次梯度累加模拟出 mini-batch 的效果,从而减少计算和显存多余开销。
流水线并行调优技巧
模型切分
这里主要介绍下流水线并行模型切分的一般调优策略。使用流水线并行做模型切分时,需要注意模型切分后各个 pipeline stage 的计算量是否均衡,避免由于某一 pipeline stage 的计算量明显大于其他 pipeline stage,导致 pipeline stage 间的等待。
图(g)
以上图(g)为例,假设流水线并行最后一个 pipeline stage 的计算量明显大于其他pipeline stage。在时间维度表现为计算时间明显大于其他 pipeline stage。这样会造成其他 pipeline stage 的计算等待,降低设备利用率。所以在对模型进行切分时,需要综合考虑模型各个部分的计算量、集群通信资源和设备拓扑方式,保证每个 pipeline stage 的计算、通信相对一致。
如果想深入了解模型切分的一般规则,欢迎感兴趣的同学点击阅读原文链接查看更多示例代码:
https://github.com/PaddlePaddle/FleetX
总结
综上所述,流水线并行将模型按照模型层切分到多个设备上,同时在调度上优化设备间的调度逻辑,使得超大规模模型训练既在设备上可以减小参数规模,也可以提升设备利用率。如果想进一步了解飞桨分布式使用方法,可以参考飞桨分布式训练Fleet下的相关API,通过使用Fleet下的相关分布式接口,即可快速开始使用飞桨进行大规模分布式训练。
相关阅读

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~