模型压缩的价值与意义
图1 端侧和边侧应用对模型压缩的需求
模型压缩面临的技术挑战
传统的模型压缩技术是比较高门槛的技术,其难度主要来源于以下4点:
在不考虑时间成本的情况下,当前最好的模型压缩方法都依赖于训练过程。但是由于没有原始数据或者算法复杂度,用户无法拿到训练代码也无法复现训练过程。
仅以离线量化(Post Training Quantization)为例,经典常用的离线量化算法就有8种(包括KLD,ABS_MAX,AVG,MSE,HIST,EMD,Bias Correctiony以及AdaRound),每种离线量化算法有2~4个参数对压缩的效果有影响。如何针对特定场景下的模型,高效地选择合适的离线量化算法及其参数,是困扰模型压缩技术项目落地的主要问题。
除了离线量化,模型压缩还有剪枝、蒸馏等多种压缩技术,随着模型小型化需求的增加,多种压缩算法也可叠加组合使用。压缩算法之间会相互影响,其效果不能简单累加 。如何从多种候选压缩算法中,选择合适的一组压缩算法,这件事深度依赖人工经验和长期的实验。
模型结构方面,主干网络层出不穷,激活函数持续演进。不同的结构和激活函数对压缩的敏感性不同,可无损压缩的比例也不同。部署环境方面,芯片特性、推理库的优化细节,都是在压缩时需要考虑的因素。综合考虑模型结构和部署环境,靠手动压缩,很难达到预期目标。
ACT重点模型效果提升示例
ACT核心技术方案详解
快速开始使用ACT
更多模型效果提升Benchmark
ACT自动压缩工具效果展示
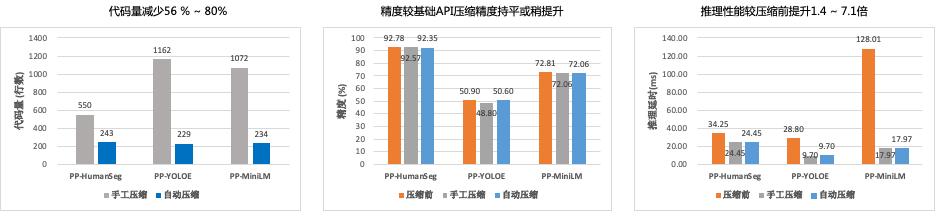
相比传统的模型压缩方法,自动化压缩代码量减少50%以上。传统的压缩方法,比如量化训练和稀疏化训练,不仅需要用户提供模型结构定义代码,还会侵入修改用户的训练代码。自动化压缩则是直接加载推理模型,新增1~2行代码调用压缩API即可。
图2 自动化压缩效果
自动化压缩后的推理性能收益也基本与手工压缩持平,相比压缩前,推理速度可以提升1.4~7.1倍。
除了以上3个不同场景下的典型模型,我们还在更多开源模型上验证了自动化压缩的效果,主要覆盖了图像分类、图像语义分割、 NLP预训练模型和图像目标检测4个场景。另外,自动化压缩还支持PyTorch、TensorFlow产出的推理模型。
ACT核心技术方案详解
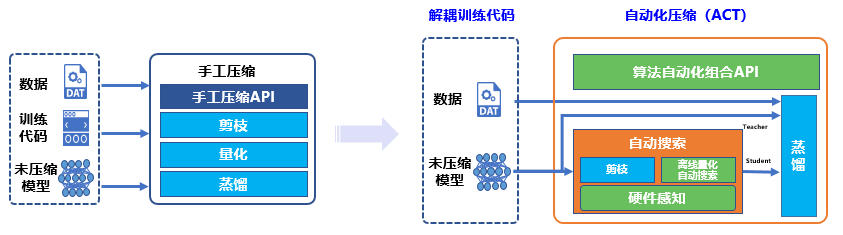
解耦训练代码
用户只用提供推理模型和无标注数据,就可以执行量化训练、稀疏训练等依赖训练过程的压缩方法。
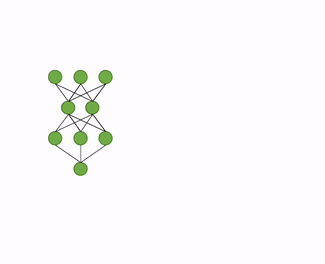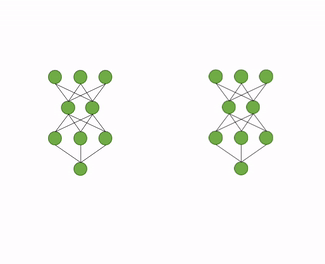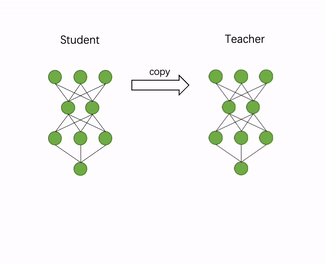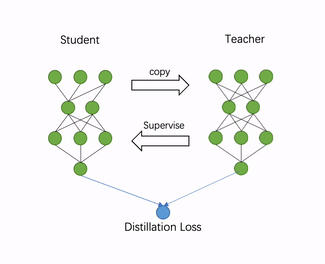
自动化压缩功能利用了知识蒸馏技术,自动为推理模型添加训练逻辑。首先,加载用户指定的推理模型文件,并将推理模型在内存中复制一份,作为知识蒸馏中的教师模型,原模型则作为学生模型。然后,自动地分析模型结构,寻找适合添加蒸馏loss的层,一般是最后一个带可训练参数的层。最后,教师模型通过蒸馏loss监督原模型的稀疏训练或量化训练。过程如图4所示。
图4 自动化压缩流程
Distillation:
# alpha: 蒸馏loss所占权重;可输入多个数值,支持不同节点之间使用不同的ahpha值
alpha: 1.0
# loss: 蒸馏loss算法;可输入多个loss,支持不同节点之间使用不同的loss算法
loss: l2
# node: 蒸馏节点,即某层输出的变量名称,可以选择:
# 1. 使用自蒸馏的话,蒸馏节点仅包含学生网络节点即可, 支持多节点蒸馏;
# 2. 使用其他蒸馏的话,蒸馏节点需要包含教师网络节点和对应的学生网络节点,
# 每两个节点组成一对,分别属于教师模型和学生模型,支持多节点蒸馏。
node:
- relu_30.tmp_0
# teacher_model_dir: 保存预测模型文件和预测模型参数文件的文件夹名称
teacher_model_dir: ./inference_model
# teacher_model_filename: 预测模型文件,格式为 *.pdmodel 或 __model__
teacher_model_filename: model.pdmodel
# teacher_params_filename: 预测模型参数文件,格式为 *.pdiparams 或 __params__
teacher_params_filename: model.pdiparams
离线量化自动搜索
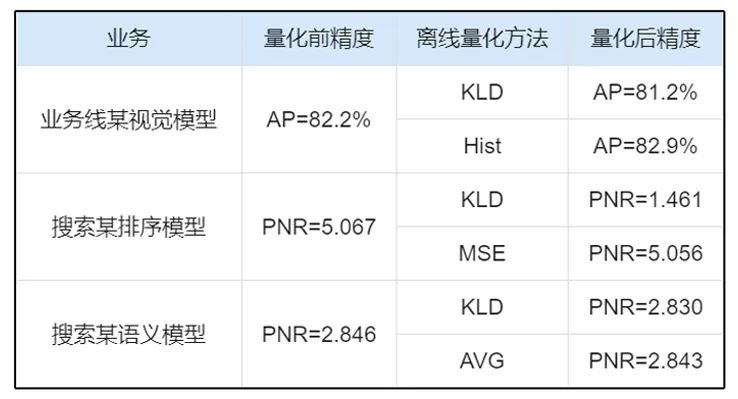
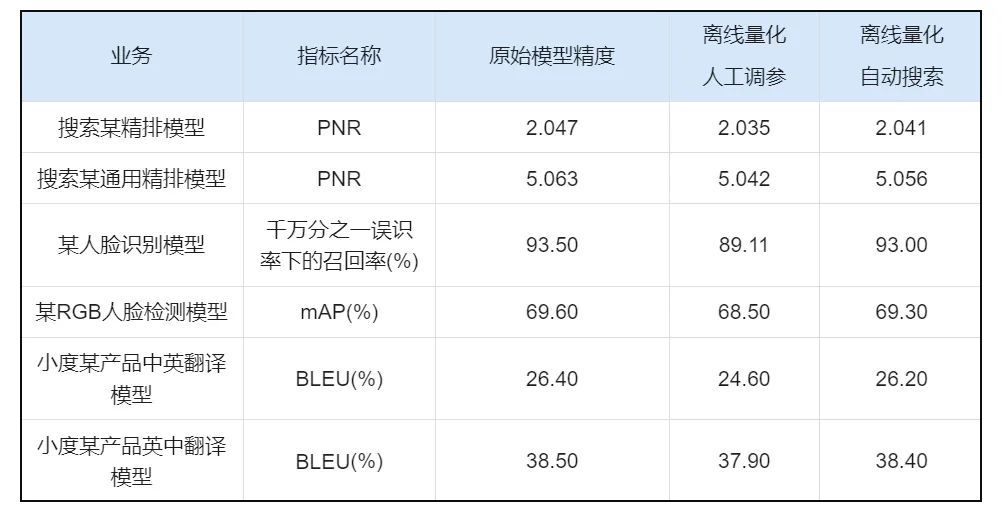
表1 各业务模型适用不同的量化方法
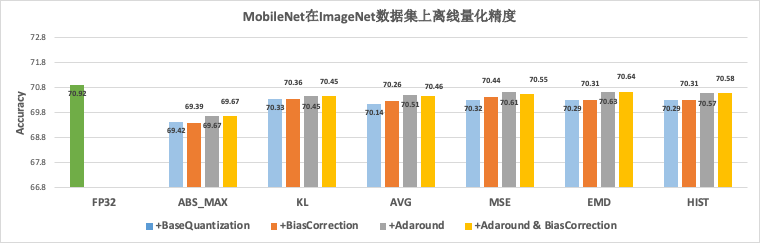
举例来说,在搜索场景中,模型多、迭代速度快,离线量化是最适合该场景的压缩方法。如上表所示,在实践中发现,不同的业务模型适用不同的离线量化算法。受此驱动,PaddleSlim实现了多种离线量化算法。如下图所示,不同的离线量化算法在MobileNetV1模型上表现各异,部分算法还可以组合使用。
图5 离线量化精度对
算法自动组合
为了更极致的压缩取得更好的加速,通常可以将稀疏化方法和量化方法叠加使用。两种方法的叠加效果不仅取决于部署环境,还取决于模型结构。自动压缩功能会分析模型结构,并根据模型结构特点和用户指定的部署环境,自动选择合适的组合算法。
硬件感知
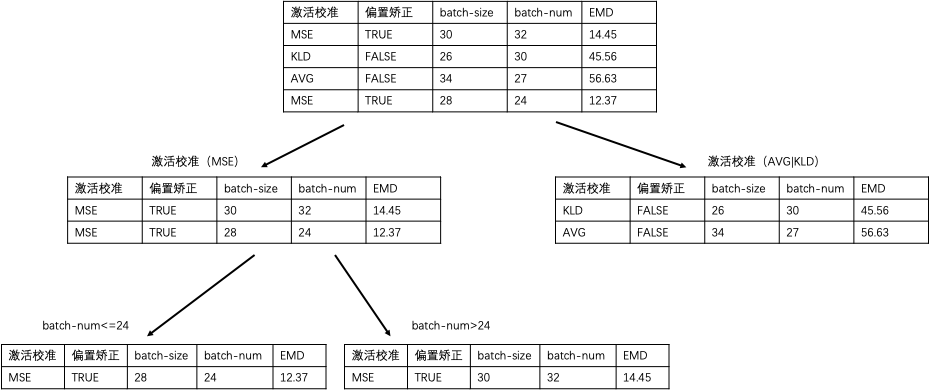
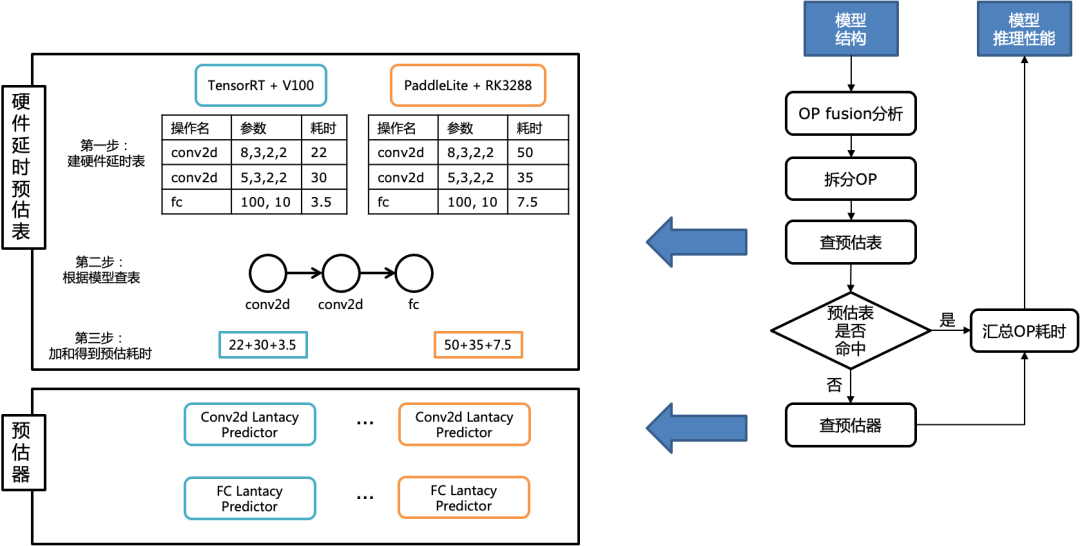
在选定组合压缩算法后,如何确定各个压缩算法的参数,则是另一个难点。压缩算法的参数设定与部署环境密切相关,需要考虑芯片特性、推理库的优化程度等各种因素。硬件感知模块作为部署环境的代理,建模并学习部署环境的特性,为参数设定提供性能查询服务。
图7 延时预估功能原理图
预估表:针对每种部署环境,采样并测试大量算子的推理性能,并记录在数据表中。数据表中的每一行包括算子类型,算子本身的参数(如:输入形状stride、padding等),稀疏度,是否量化等信息。预估表可以准确预估命中的算子的信息,但是难以覆盖算子所有可取的参数。
预估器:使用预估表中的数据,为每类算子训练一个预测器,用于预测推理性能。预估器的准确性不如预估表,但是有更强的泛化能力,可以覆盖算子参数的更多取值。
第一步:分析模型结构,对推理模型做OP融合(为了得到最终在部署时执行的OP);
第二步:对第一步产出的推理模型中的所有OP,依次查预估表,如果无法命中,则查预估器;
第三步:累加所有OP的耗时得到候选模型最终的推理性能。
在以上功能的支持下,我们可以快速得到各种压缩参数下的模型推理性能,再根据用户指定的在特定硬件的推理加速倍数,锁定少量候选模型,最后逐个验证候选模型的精度。
快速开始使用ACT
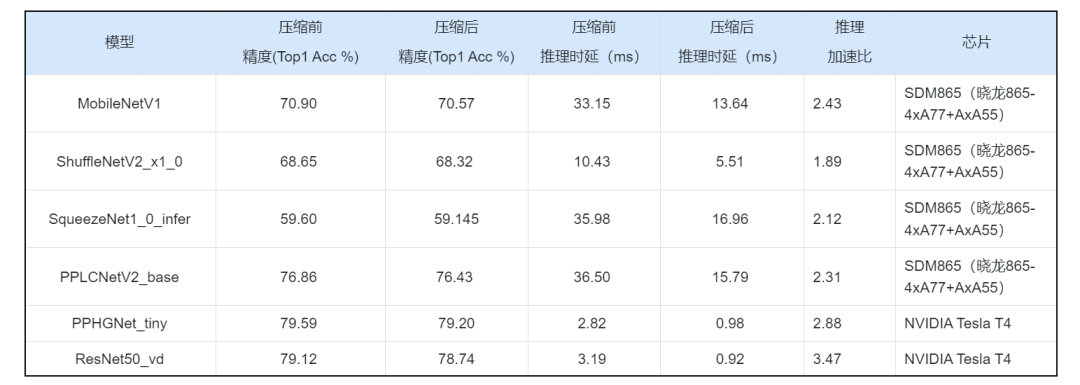
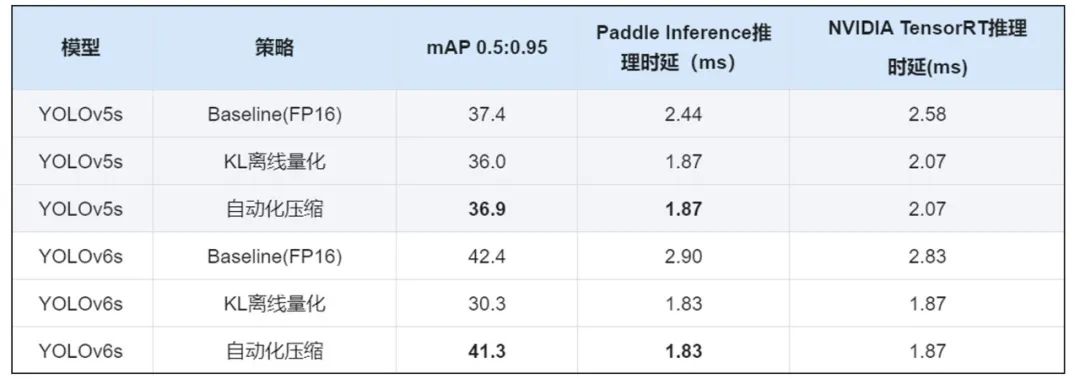
在自动压缩完成之后,分别执行精度评估脚本和速度评估脚本,可以分别获得自动压缩前后的精度和速度对比,如下表所示。
更多模型效果提升
Benchmark
图像分类
值得强调的是,PP-LCNetv2和PP-HGNet是飞桨模型团队针对特定芯片设计的高效模型结构。在人工深度优化的基础上,自动化压缩可以进一步提升这些模型的推理性能。
图像语义分割
自动化压缩在PP-HumanSeg-Lite、PP-LiteSeg、HRNet和UNet等模型上,精度几乎无损,在NVIDIA GPU上的加速达1.23~1.49倍。
NLP中文预训练模型
关于测试环境、数据集等更多信息,请参考:
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/example/auto_compression/nlp
其他框架的模型压缩效果
除了对飞桨模型的压缩效果显著,PaddleSlim自动化压缩还支持其它框架产出的推理模型。
mAP的指标均在COCO val2017数据集中评测得到
测试环境:
Top1_Acc是在ImageNet1k分类数据集上测试得到
测试环境:骁龙865 4A77 4A55
具体压缩方法请参考:
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/example/auto_compression/pytorch_huggingface
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/example/auto_compression/pytorch_yolov5
私享线上交流会
想了解更多自动模型压缩工具产品信息,可以参看github或点击阅读原文详细了解:

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~