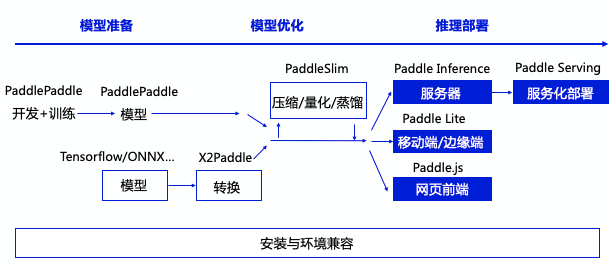
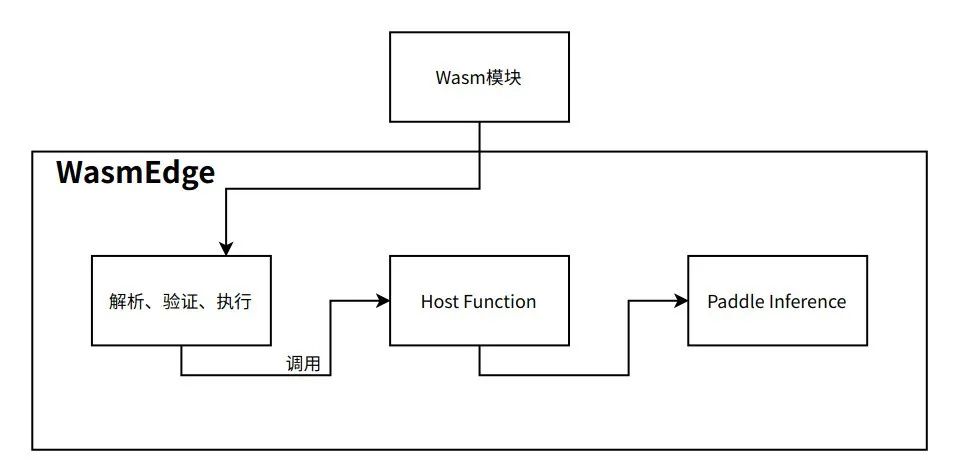
WebAssembly与WASI
在设计嵌入式、Serverless等场景的时候,我们可以选择使用Wasm作为安全的二进制格式。Wasm模块可以被动态分发到系统中,按需执行并限制访问的资源。当需要访问文件等敏感资源时,Wasm模块调用Host Funtcion发出请求,由Runtime判断是否提供资源。
WasmEdge
Linux等平台可以使用安装脚本:
Bash
curl -sSf https://raw.githubusercontent.com/WasmEdge/WasmEdge/master/utils/install.sh | bashPowerShell
winget install wasmedge
Paddle Inference
这次我们将使用C++预测库,我也曾在往期的在线分享中介绍过将C++预测库制作成Node.js下的插件供js程序调用,原理是使用N-API完成Node.js与C++双方的数据类型转换。
为WasmEdge
添加自定义Host Function
Runtime此时相当于一个中间件,调用Paddle Inference库完成推理,将结果复制到模块的线性内存中。为WasmEdge添加Host Function比较简单,我们fork一份源码,做出下面的修改:
修改CMake规则,添加Paddle Inference相关内容:
CMakeLists.txt#L70-L277
添加自定义函数:
wasifunc.cpp#L2087-L2169、wasimodule.cpp#L75修改对应的头文件和类声明等。
C++
Expect<uint32_t>
WasiPaddleYolov3::body(Runtime::Instance::MemoryInstance *MemInst,
uint32_t ResPtr, uint32_t MaxResLength, uint32_t ResLengthPtr) {
using paddle_infer::Config;
using paddle_infer::CreatePredictor;
using paddle_infer::Predictor;
Config config;
config.SetModel("/path/to/model.pdmodel", "/path/to/model.pdiparams");
config.EnableMKLDNN();
auto predictor = CreatePredictor(config);
const int height = 608;
const int width = 608;
const int channels = 3;
std::vector<int> input_shape = {1, channels, height, width};
std::vector<float> input_data(1 * channels * height * width);
for (size_t i = 0; i < input_data.size(); ++i) {
input_data[i] = i % 255 * 0.13f;
std::vector<int> input_im_shape = {1, 2};
std::vector<float> input_im_data(1 * 2, 608);
std::vector<float> out_data;
if (auto Res = run(predictor.get(), input_data, input_shape, input_im_data,
input_im_shape, &out_data);
unlikely(!Res)) {
return __WASI_ERRNO_CANCELED;
auto copyOutputData =
[&MemInst](uint8_t_ptr Base, uint32_t Length,
const std::vector<float> &Data) {
for (uint32_t Item = 0; Item < Length && Item < Data.size(); Item++) {
auto *p = MemInst->getPointer<float *>(
Base + sizeof(float) * Item, sizeof(float));
*p = Data[Item];
auto *const ResLength = MemInst->getPointer<__wasi_size_t *>(
ResLengthPtr, sizeof(__wasi_size_t *));
copyOutputData(*(MemInst->getPointer<uint8_t_ptr *>(ResPtr, sizeof(uint8_t))),
MaxResLength, out_data);
*ResLength = out_data.size();
return __WASI_ERRNO_SUCCESS; 在最关键的WasiPaddleYolov3::body函数体中,大体上和正常调用Paddle Inference类似,不同体现在我们获取参数和返回结果上。由于Wasm模块的内存是由Runtime提供的线性内存,我们读入参数和复制结果的时候需要使用特定的函数去拿到指针。作为参数的指针在Wasm模块中也需要提前申请好内存。
编译和执行
Bash
mkdir build
cd build
cmake -DCMAKE_BUILD_TYPE=Debug -DPADDLE_LIB=PATH_TO_INFERENCE -DPP_WITH_MKL=ON -DPP_WITH_GPU=OFF -DPP_WITH_STATIC_LIB=OFF -DPP_USE_TENSORRT=OFF .. && make -j
Rust
fn main() {
const MAX_LENGTH : u32 = 1024;
let mut buf: Vec<f32> = vec![0f32; MAX_LENGTH as usize];
let mut buf_ptr = buf.as_mut_ptr() as u32;
let mut res_len: u32 = 0;
unsafe {
let res = wasi_host::pp_yolov3(&mut buf_ptr, MAX_LENGTH, &mut res_len);
println!("Res: {}", res);
}
println!("Res_len: {}", res_len);
println!("Buf: {:?}", buf);
}
mod wasi_host {
#[link(wasm_import_module = "wasi_snapshot_preview1")]
extern "C" {
pub fn pp_yolov3(
res: *mut u32,
max_len: u32,
res_len: *mut u32,
) -> u32; Bash
wasmedge ./target/wasm32-wasi/debug/wasm_yolov3.was
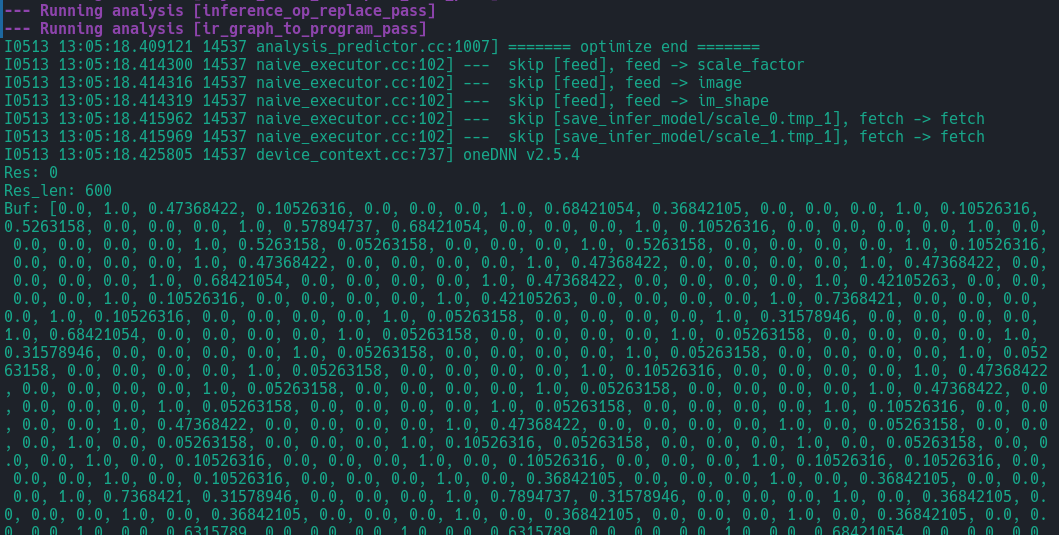
总结
将Paddle Inference和WasmEdge结合起来可以赋予Wasm模块进行模型推理的能力,以上的例子只是一个初步的尝试。读者可以将图片读入等功能一并添加进来,构建完整的推理程序。这样做可以将AI能力提供给所有部署的模块,而不需要在每个模块中重复代码。得益于WebAssembly的能力,Serverless等场景进行AI推理将更为简单。
关于作者
个人博客:https://www.lirui.tech
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~