PaddleOCR v2.6版本升级,为开发者带来了全新发布的
PP-Structurev2文档分析模型
,主要升级点包括:
-
新增图
像矫正和版面复
原模块、关键信息抽取能力全覆盖!
-
版面分析模块:
发布轻量级版面分析模型,
速度提升11倍
,平均
CPU耗时仅需41ms
!
-
表格识别模块:
设计3大优化策略,预测耗时不变情况下,模型
精度提升6%
。
-
关键信息抽取模块:
设计视觉无关模型结构,语义实体识别精度
提升2.8%
,关系抽取精度
提升超过9.1%
。

https://github.com/PaddlePaddle/PaddleOCR
PP-Structurev2模型结构如下所示,文档图像首先经过图像矫正模块,判断整图方向并完成转正,随后可以完成版面信息分析与关键信息抽取2类任务。
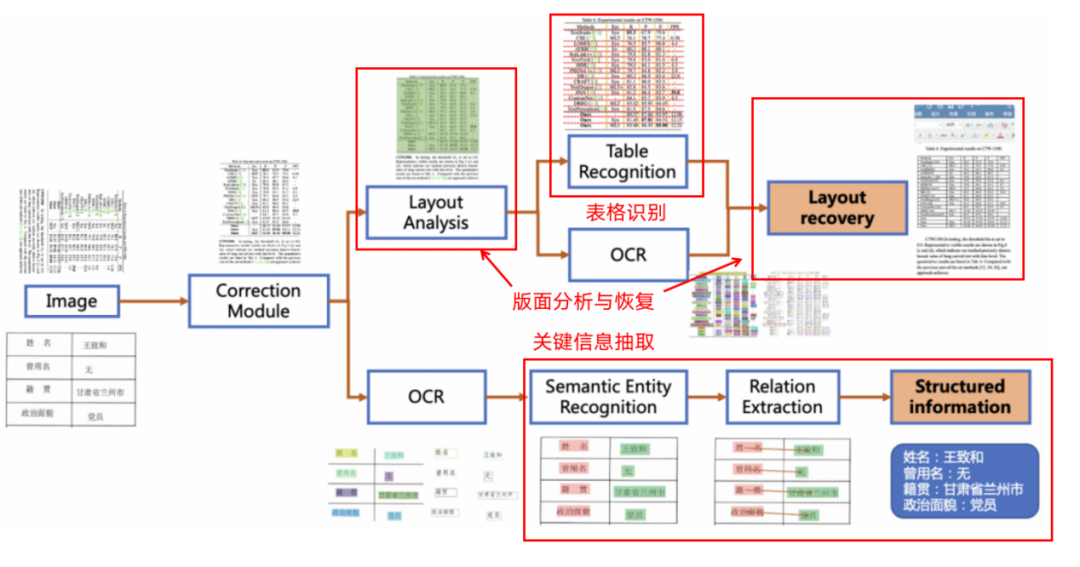
图2 PP-Structurev2流程图
从算法改进思路来看,对其中的3个关键子模块,共进行了8个方面的改进
:
PP-PicoDet:轻量级版面分析模型
FGD:兼顾全局与局部特征的模型蒸馏算法
区别一
:版面分析模型参数量减少95%,推理速度提升11倍,精度提升0.4%;
区别二:表格识别预测耗时不变,模型精度提升6%,端到端TEDS提升2%;
区别三
:关键信息抽取模型速度提升2.8倍,语义实体识别模型精度提升2.8%;关系抽取模型精度提升9.1%。
PP-Structurev2
核心8个优化策略详细解读
版面分析指的是对图片形式的文档进行区域划分,定位其中的关键区域,如文字、标题、表格、图片等,PP-Structurev1使用了PaddleDetection中开源的高效检测算法PP-YOLOv2完成版面分析的任务。
在PP-Structurev2中,我们发布基于PP-PicoDet的轻量级版面分析模型,针对版面分析场景定制图像尺度,同时使用FGD知识蒸馏算法,进一步提升模型精度,
最终CPU上41ms即可完成版面分析
。
PP-PicoDet:轻量级版面分析模型
PP-PicoDet是PaddleDetection中提出的轻量级目标检测模型,通过使用PP-LCNet骨干网络、CSP-PAN特征融合模块、SimOTA标签分配方法等优化策略,最终在CPU与移动端具有卓越的性能。我们将PP-Structurev1中采用的PP-YOLOv2模型替换为PP-PicoDet,同时针对版面分析场景优化预测尺度,从针对目标检测设计的640*640调整为更适配文档图像的800*608,在1.0x配置下,模型精度与PP-YOLOv2相当,CPU平均预测速度可提升11倍。
FGD(Focal and Global Knowledge Distillation for Detectors),是一种兼顾局部全局特征信息的模型蒸馏方法,分为Focal蒸馏和Global蒸馏2个部分。Focal蒸馏分离图像的前景和背景,让学生模型分别关注教师模型的前景和背景部分特征的关键像素;Global蒸馏部分重建不同像素之间的关系并将其从教师转移到学生,以补偿Focal蒸馏中丢失的全局信息。版面分析实验结果表明,FGD蒸馏算法能够进一步提升模型精度。

图3 版面分析效果图(分类为文字、图片、表格、图注、标注等)
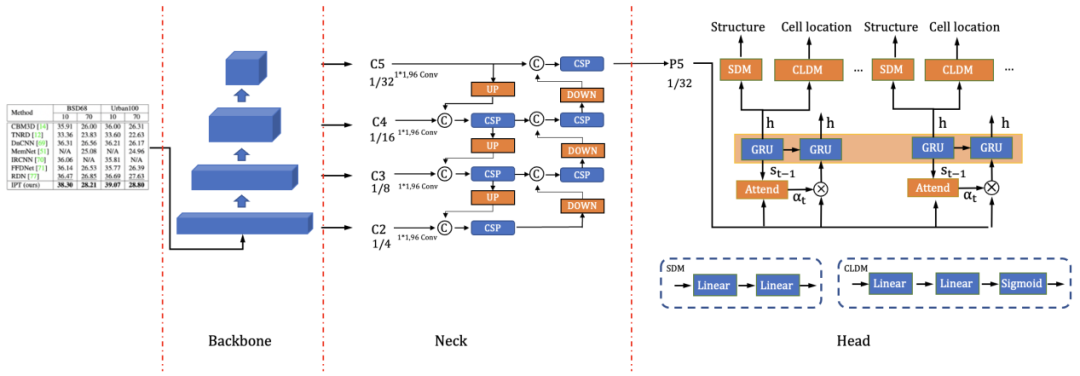
基于深度学习的表格识别算法种类丰富,PP-Structurev1基于文本识别算法RARE研发了端到端表格识别算法TableRec-RARE,模型输出为表格结构的HTML表示,进而可以方便地转化为Excel文件。TableRec-RARE中,图像输入到骨干网络后会得到四个不同尺度的特征图,分别为C2(1/4),C3(1/8),C4(1/16),C5(1/32),Head特征解码模块将C5作为输入,并输出表格结构信息和单元格坐标。
本次升级过程中,我们对模型结构和损失函数等5个方面进行升级,提出了 SLANet (Structure Location Alignment Network) ,模型结构如下图所示,详细解读请参考技术报告。
可视化结果如下,左为输入图像[1],右为识别的HTML表格结果
图5 可视化结果
在PubtabNet英文表格识别数据集上,和其他方法对比如下。SLANet平衡精度与模型大小,推理速度最快,能够适配更多应用场景:
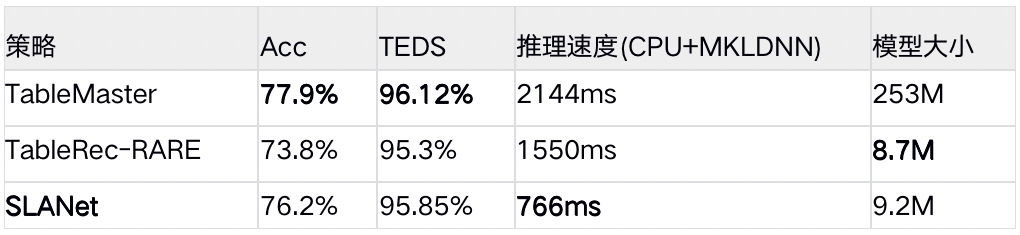
表1 SLANet模型与其他模型效果对比
*测试环境:飞桨版本为2.3.1,CPU为Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz,开启mkldnn,线程数为10。
PP-LCNet: CPU友好型轻量级骨干网络
PP-LCNet是结合Intel-CPU端侧推理特性而设计的轻量高性能骨干网络,在图像分类任务上,该方案在“精度-速度”均衡方面的表现比ShuffleNetV2、MobileNetV3、GhostNet等轻量级模型更优。PP-Structurev2中,我们采用PP-LCNet作为骨干网络,表格识别模型精度从71.73%提升至72.98%;同时加载通过SSLD知识蒸馏方案训练得到的图像分类模型权重作为表格识别的预训练模型,最终精度进一步提升2.95%至74.71%。
CSP-PAN:轻量级高低层特征融合模块
对骨干网络提取的特征进行融合,可以有效解决尺度变化较大等复杂场景中的模型预测问题。早期,FPN模块被提出并用于特征融合,但是它的特征融合过程仅包含单向(高->低),融合不够充分。CSP-PAN基于PAN进行改进,在保证特征融合更为充分的同时,使用CSP block、深度可分离卷积等策略减小了计算量。在表格识别场景中,我们进一步将CSP-PAN的通道数从128降低至96以降低模型大小。最终表格识别模型精度提升0.97%至75.68%,预测速度提升10%。
PP-Structurev2中,我们设计SLAHead模块,对单元格token和坐标之间做了对齐操作,如下图b所示。在SLAHead中,每一个step的隐藏层状态表征会分别送入SDM和CLDM来得到当前step的token和坐标,每个step的token和坐标输出分别进行concat得到表格的html表达和全部单元格的坐标。此外,我们在结构与回归分支使用更多的全连接层,增加二者特征的区分度。
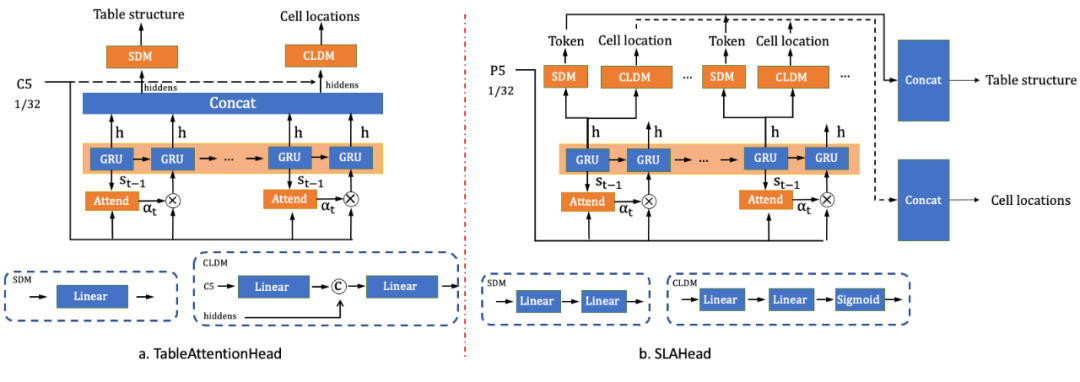
图6 SLAHead结构
关键信息抽取指的是针对文档图像的文字内容,提取出用户关注的关键信息,如身份证中的姓名、住址等字段。主要优化策略如下:
VI-LayoutXLM:
视觉特征无关的多模态预训练模型结构
LayoutLMv2以及LayoutXLM中引入视觉骨干网络,用于提取视觉特征,并与后续的text embedding进行联合,作为多模态的输入embedding。但是该模块为基于ResNet_x101_64x4d的特征提取网络,特征抽取阶段耗时严重,因此我们将其去除,同时仍然保留文本、位置以及布局等信息,最终发现针对LayoutXLM进行改进,下游SER任务精度无损,针对LayoutLMv2进行改进,下游SER任务精度仅降低2.1%,而模型大小减小了约340M。具体消融实验可以参考技术报告。
PP-Structurev2中,我们对模型结构以及下游任务训练方法进行升级,提出了VI-LayoutXLM(Visual-feature Independent LayoutXLM),具体流程图如下所示。
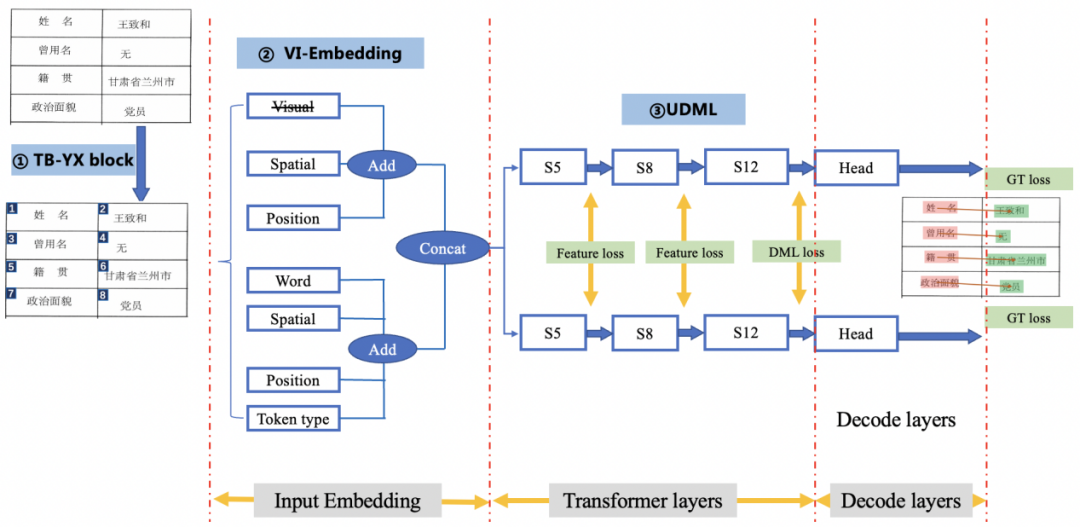
图7 关键信息抽取流程图
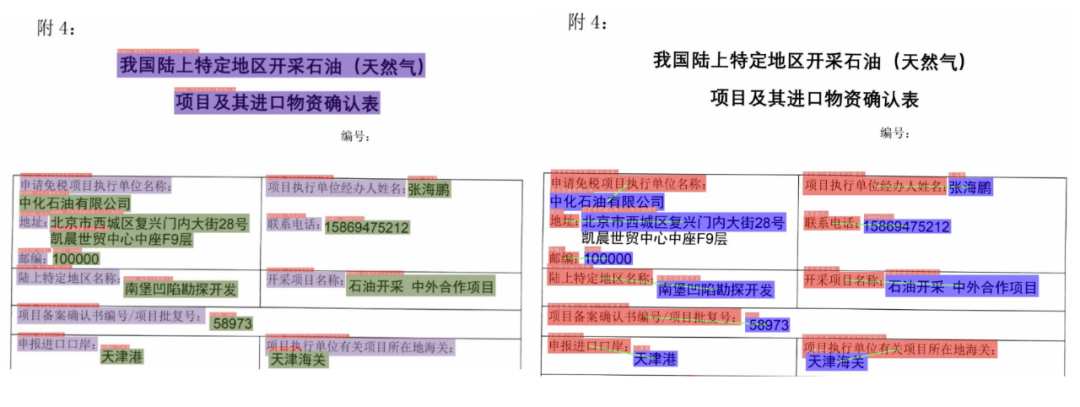
在XFUND数据集上,与其他方法的效果对比如下所示。
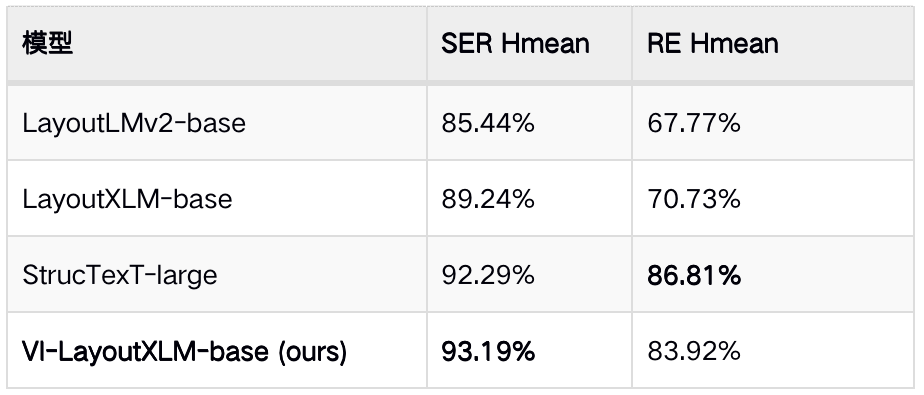
表2 VI-LayoutXLM模型与其他模型效果对比
TB-YX:考虑阅读顺序的文本行排序逻辑
文本阅读顺序对于信息抽取与文本理解等任务至关重要,传统多模态模型中,没有考虑不同OCR工具可能产生的不正确阅读顺序,而模型输入中包含位置编码,阅读顺序会直接影响预测结果,在预处理中,我们对文本行按照从上到下,从左到右(YX)的顺序进行排序,为防止文本行位置轻微干扰带来的排序结果不稳定问题,在排序的过程中,引入位置偏移阈值Th,对于Y方向距离小于Th的2个文本内容,使用X方向的位置从左到右进行排序。
UDML(Unified-Deep Mutual Learning)联合互学习是PP-OCRv2与PP-OCRv3中采用的对于文本识别非常有效的提升模型效果的策略。在训练时,引入2个完全相同的模型进行互学习,计算2个模型之间的互蒸馏损失函数(DML loss),同时对transformer中间层的输出结果计算距离损失函数(L2 loss)。使用该策略,最终XFUND数据集上,SER任务F1指标提升0.6%,RE任务F1指标提升5.01%。
飞桨社区开发者吴泓晋(GitHubID:whjdark)基于最新发布的PP-Structurev2文档分析模型,开发了一款PDF转Word小工具,导入PDF文件可一键转换为可编辑Word,支持文字、表格、标题、图片的完整恢复。
软件的使用十分简单,解压压缩包,运行exe安装完成后打开软件,上传图片,点击转换后即可转换得到Word文件。
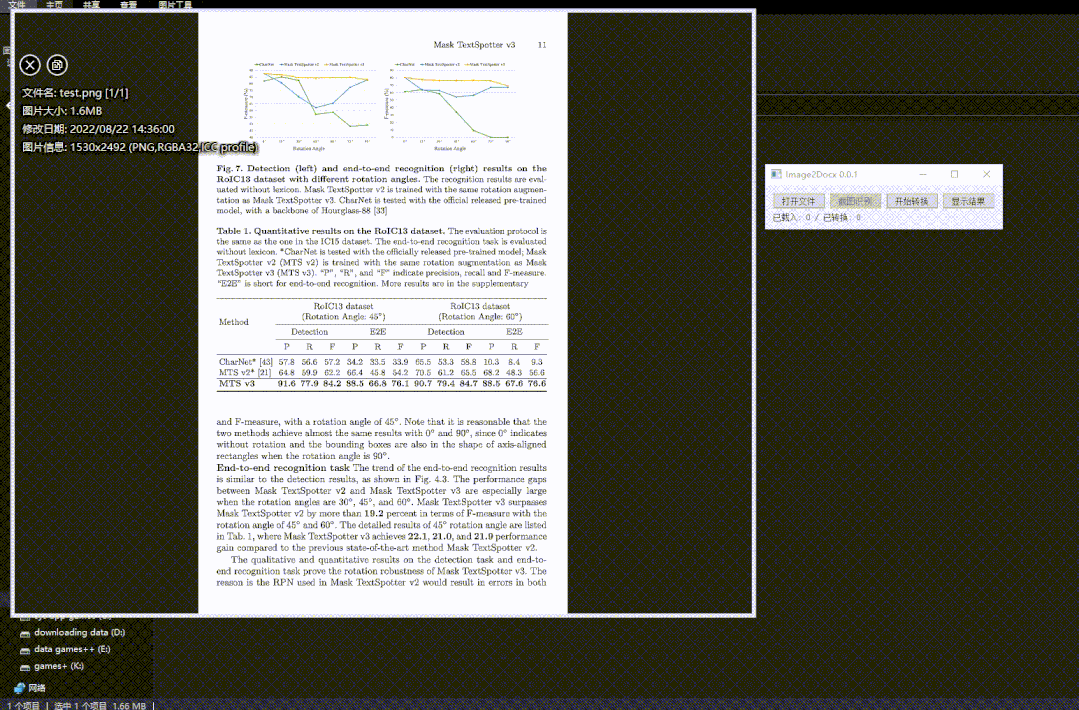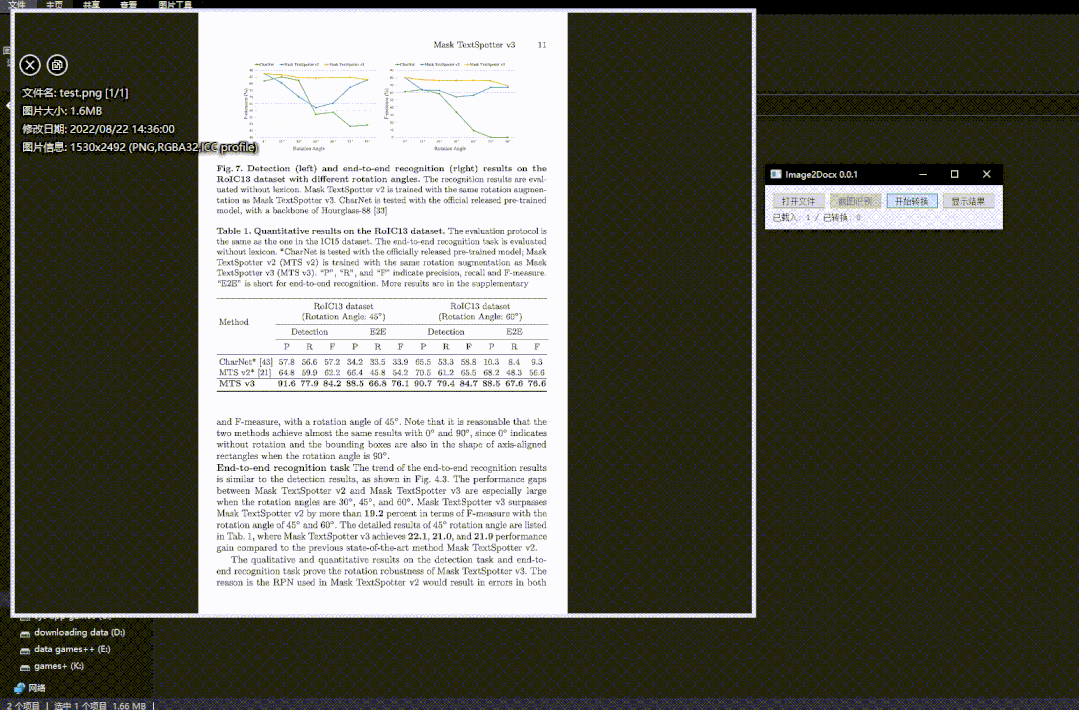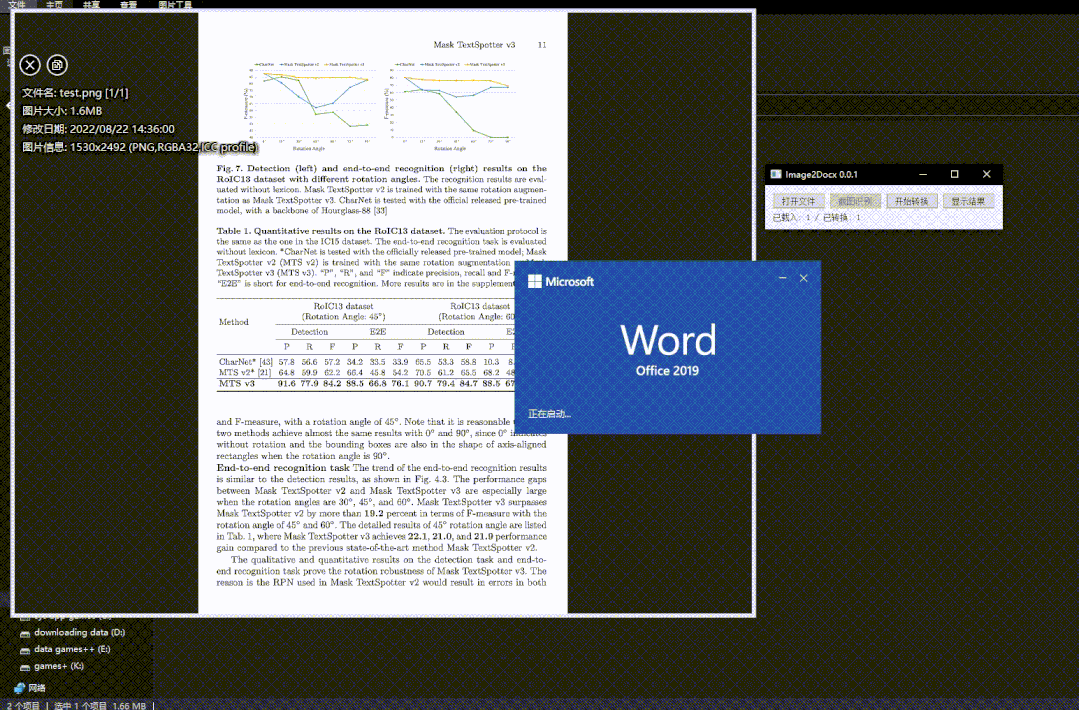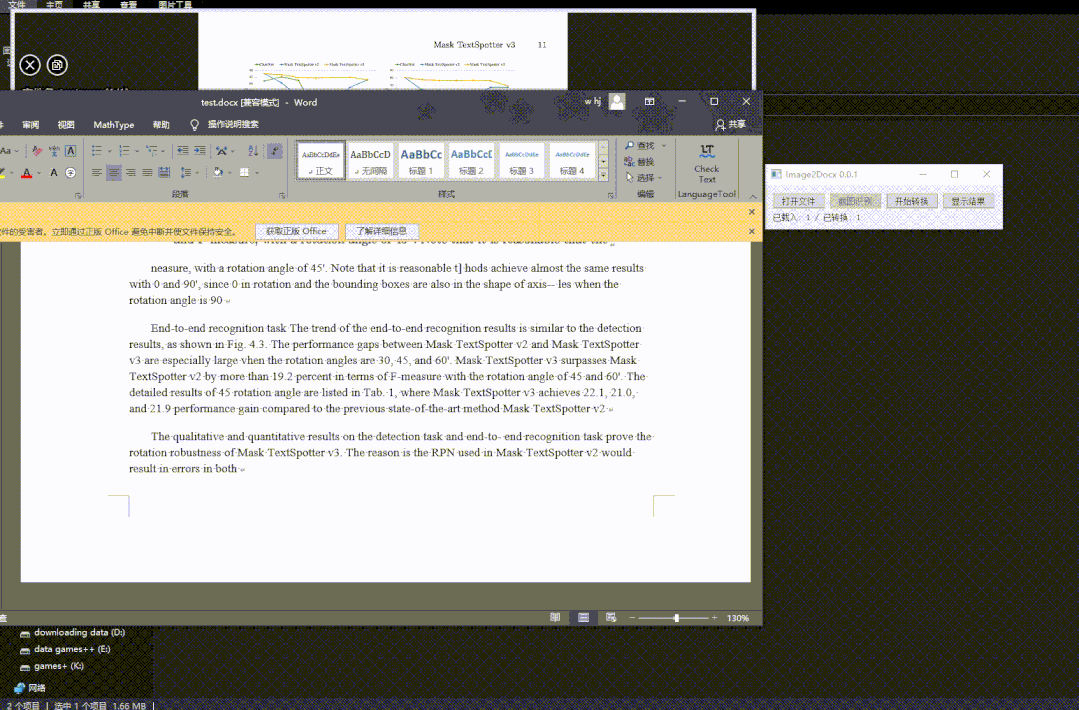
福利二:获取PaddleOCR详解本次升级内容的直播课链接;
福利三:获取PaddleOCR团队整理的10G重磅OCR学习大礼包,包括:
-
《动手学OCR》电子书,配套讲解视频和Notebook项目;
-
OCR场景应用集合:包含数码管、液晶屏、车牌、高精度SVTR模型等7个垂类模型,覆盖通用,制造、金融、交通行业的主要OCR垂类应用;
-
-
方式一: 微信扫描下方二维码,关注公众号,填写问卷后进入微信群

[1] 图片源于网络
[2] XFUN数据集:Xu Y, Lv T, Cui L, et al. XFUND: A Benchmark Dataset for Multilingual Visually Rich Form Understanding[C]//Findings of the Association for Computational Linguistics: ACL 2022. 2022: 3214-3224.
https://www.paddlepaddle.org.cn
https://github.com/PaddlePaddle/PaddleOCR
https://gitee.com/paddlepaddle/PaddleOCR
https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/ppstructure/docs/PP-Structurev2_introduction.md
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~


