在6月30日最新发布的MLPerf Training v2.0里,百度使用飞桨框架( PaddlePaddle )和百度智能云百舸计算平台提交的BERT Large模型GPU训练性能结果,在同等GPU配置下的所有提交结果里排名第一,超越了高度定制优化且长期处于领先位置的NGC PyTorch框架,向全世界展现了飞桨框架的性能优势。
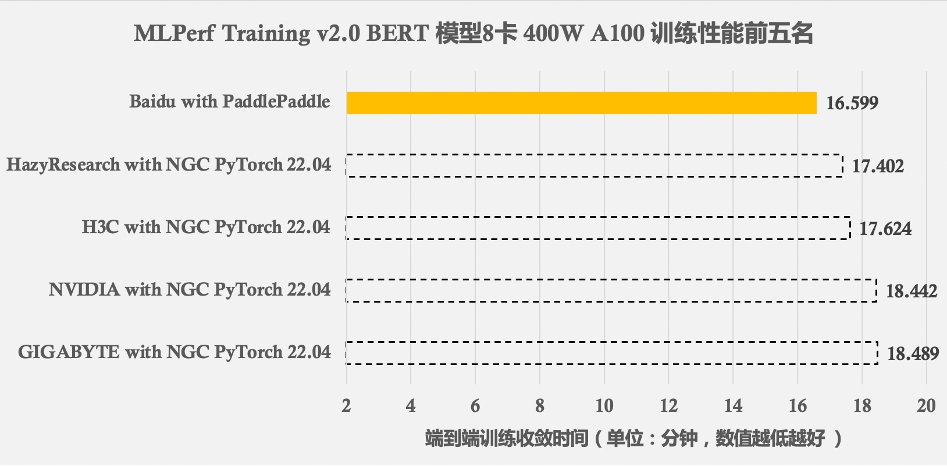
图1. MLPerf Training v2.0 BERT模型在8卡NVIDIA GPU A100( 400W功耗,80G显存 )下前五名的训练性能结果,百度飞桨方案比其他提交结果快5%-11%不等[1]
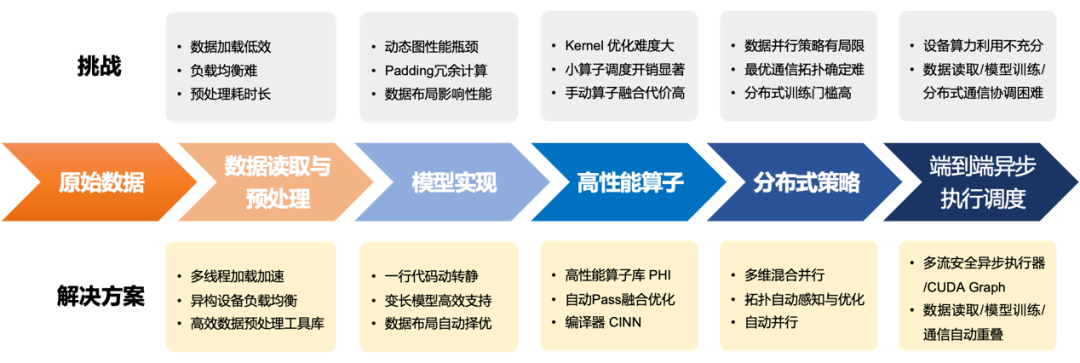
BERT模型是MLPerf Training v2.0自然语言处理领域的唯一基准模型。飞桨在BERT模型8卡GPU训练上创造了世界最优的训练性能,这来自于飞桨框架基础性能与分布式技术的领先性,以及飞桨与NVIDIA GPU的深度协同优化。对于深度学习模型训练任务,从数据读取到模型计算,从底层算子到上层分布式策略,从多设备负载均衡到全流程调度机制,都会影响最终训练性能。
飞桨基于领先的架构设计和长期的实践打磨,在高性能训练方面做出了系统性的优化工作,主要体现在如下几个方面:
针对变长序列输入模型大多采用的padding填充对齐方式[2-4]带来的冗余计算问题,提供对变长输入和对应模型结构的高效支持,让GPU算力资源专注于有效计算,尤其是对Transformer类模型计算效率提升明显。
针对分布式训练经常出现的负载不均衡问题,将模型训练和数据读取、预处理分配到不同设备上进行,确保异构算力物尽其用,实现数据IO和计算的平衡。
针对框架基础性能优化的极致需求,研发了高性能的高可复用算子库PHI ,充分优化GPU内核实现,提升算子内部计算的并行度,并通过算子融合降低仿存开销,发挥GPU的极限性能。
针对传统数据并行性能、显存瓶颈受限的问题,实现了融合数据并行、模型并行、分组参数切片并行等策略的混合并行分布式训练策略,部分场景下可实现超线性加速的分布式训练性能。
针对模型训练过程各环节存在的同步频率高、时间重叠度低等问题,设计异步调度机制,保证模型收敛的同时去除大部分同步操作,实现数据处理、训练和集合通信等各环节近乎全异步调度,提升端到端极致性能。
以下以MLPerf BERT模型为例,逐一介绍飞桨框架的各项优化内容,更详细的优化细节请参见http://arxiv.org/abs/2208.08124 。
自然语言处理领域的输入数据大部分都是变长的,为了组网和计算方便,往往会通过padding的方式将每个序列填充为等长的长度,但带来了冗余数据和冗余计算,如图3所示。为了提升MLPerf BERT模型性能,需要去除这些冗余数据带来的冗余计算量。
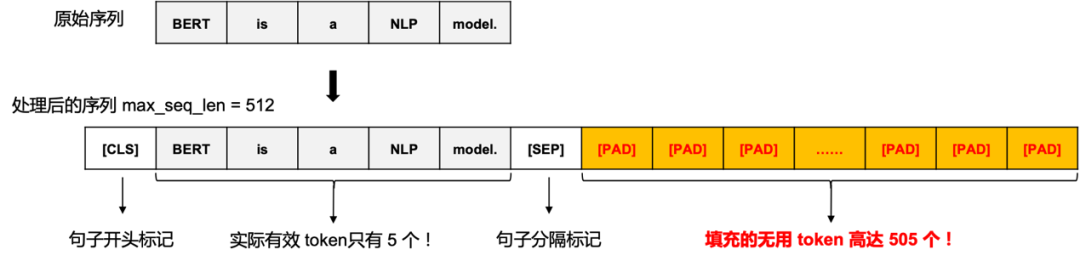
图3. 序列数据 padding 的示意图
BERT Encoder是BERT的主要组成部分,其中的Multi-Head Attention部分的优化是提升BERT训练性能的关键。Multi-Head Attention的主体结构如图4所示。
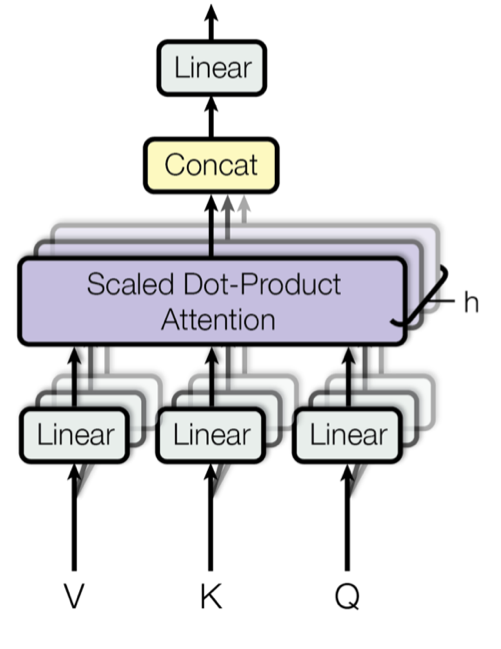
图4. Multi-Head Attention的主体结构
在参考NVIDIA Apex Library实现的基础上[5],飞桨实现了支持变长的融合 Multi-Head Attention算子,即unpad FMHA(Fused Multi-Head Attention)算子,我们将Encoder模块使用unpad计算方法进行实现。相比padding的方法,unpad的实现传入的输入有一些变化。
首先,如图5所示,输入张量的维度由原来的[batch_size, max_seq_len]被压缩(不同样本的有效 token 被线性平铺)存储为[ntokens],其中batch_size为批大小,max_seq_len为padding的最大序列长度, ntokens代表当前mini-batch有效token总个数。
其次,要求传入能够反映变长序列实际长度的辅助信息,如batch_offset和max_seqlen_cur_bs等,其中batch_offset代表当前mini-batch中样本有效序列长度的前缀和信息,max_seqlen_cur_bs代表当前mini-batch样本的最大序列长度。这些信息会传入到unpad FMHA算子进行辅助计算。
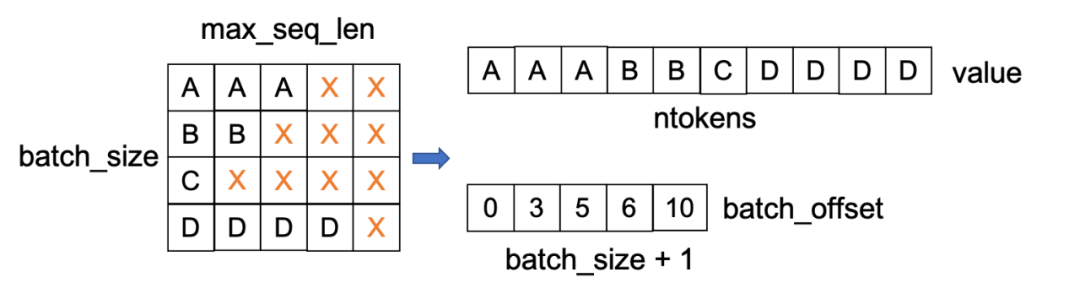
图 5. unpad方法输入张量的存储变化
对BERT Encoder模块使用unpad优化后,端到端获得了大约2.3倍的性能提升。
在变长输入下,很难实现出一个适合所有序列长度分布的、统一的最优CUDA Kernel。举例来说,我们编写了一个在max_seq_len_cur_bs=512的情况下性能最好的CUDA Kernel ,但很难保证在max_seq_len_cur_bs=128的情况下性能也是最优的。不同序列长度分布有对应的不同的最优CUDA Kernel实现,Kernel 的分块大小、shared memory和寄存器使用情况也会有所不同。
在实际训练过程中,unpad FMHA算子会根据当前mini-batch样本的max_seqlen_cur_bs的值来选择最合适的CUDA Kernel执行,其选取Kernel 的原则如下所示,其中FMHA_128 、FMHA_256、FMHA_384和FMHA_512为根据不同max_seq_len_cur_bs的值所实现的最优CUDA Kernel。
if (0 < max_seqlen_cur_bs <= 128)
FMHA_128(...);
else if (128 < max_seqlen_cur_bs <= 256)
FMHA_256(...);
else if (256 < max_seqlen_cur_bs <= 384)
FMHA_384(...);
else if (384 < max_seqlen_cur_bs <= 512)
FMHA_512(...);
由上述选取CUDA Kernel的原则可以发现,根据max_seqlen_cur_bs选取的CUDA Kernel,往往偏向于数值更大的CUDA Kernel。例如,如果一个mini-batch中只有少量序列的长度为512,其他序列的长度都小于128,那么上述原则选取的CUDA Kernel则是FMHA_512,而不是FMHA_128。我们在MLPerf BERT模型实际测试中发现,训练过程中几乎全部选择的都是FMHA_512的 CUDA Kernel,这使得序列长度较小的样本的计算无法达到更好的性能。
为了解决该问题,我们对mini-batch内样本进行分组,让不同小组的样本选择最合适的FMHA Kernel,从而提升整体性能。首先,对mini-batch内样本按照序列长度进行分组,例如根据上述CUDA Kernel选取原则分为 (0, 128], (128, 256], (256, 384], (384, 512] 这4组。然后根据分组情况,每个小组launch相应的 FMHA Kernel。每个小组在调用FMHA Kernel时,需要根据组内的样本个数和token信息重新设置batch_size大小和相关输入的地址偏移。如图6所示,同一个mini-batch的7个样本,根据样本的长度划分成了四个不同的小组(具有相同颜色标识的矩形块属于同一个小组),并分别launch了对应的CUDA Kernel。对于256这个分组(图中黄色的序列),其有2个样本,会调用FMHA_256 Kernel,调用时需设置batch_size为2,max_seqlen_cur_bs为256。
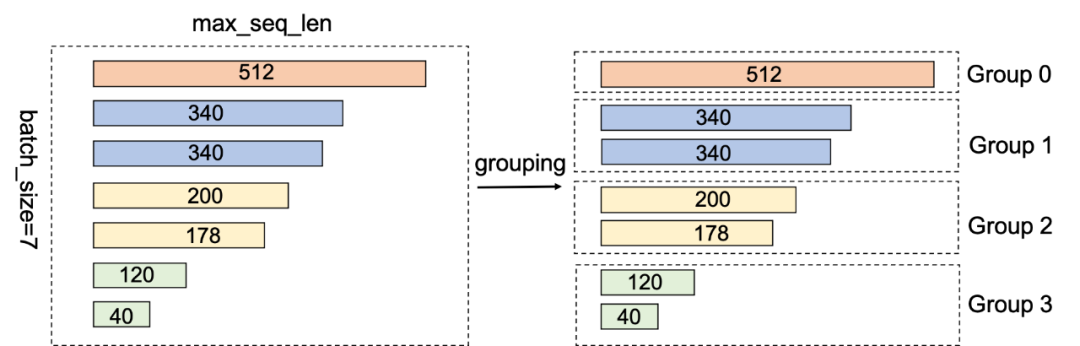
图6. 分组示意图
默认情况下,不同分组的FMHA Kernel在同一个stream中执行。同一个stream中的Kernel会按照Kernel launch的顺序依次来执行。只有当前一个launch的Kernel执行完成,后面launch的Kernel才开始调度。事实上,由于不同分组的FMHA Kernel是独立且没有数据依赖的,可以使用多stream技术进一步提升性能。多stream情况下,调度器会根据当前GPU资源使用情况,同时调度来自不同stream的FMHA Kernel,从而提高GPU的资源利用率,提升Multi-Head Attention模块的整体性能,如图7所示。
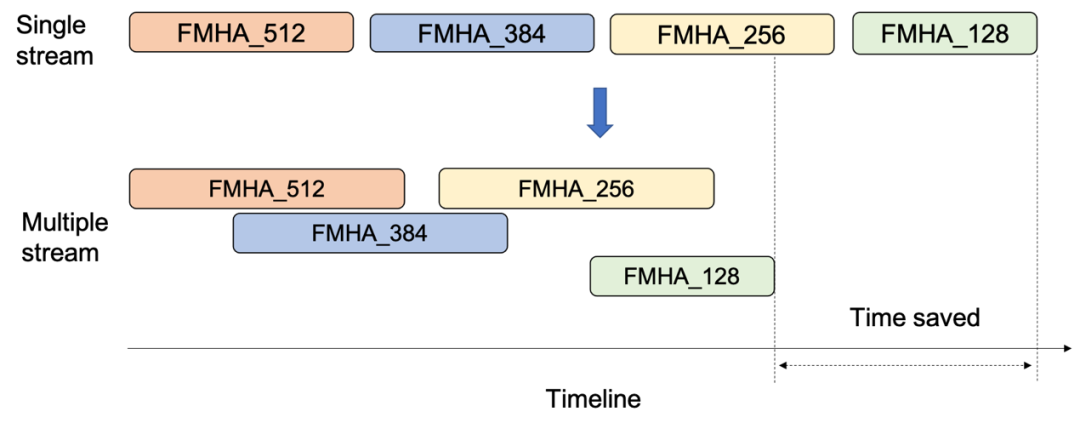
图7. FMHA kernels overlap示意图
我们需要使用CUDA event控制不同stream 上 Kernel的执行顺序,从而保证计算结果的正确性。图8展示了Kernel的依赖关系。我们将Multi-Head Attention模块之前的最后一个算子和之后的第一个算子对应的CUDA Kernel分别称为A Kernel和C Kernel。为了保证计算结果的正确性,需要保证FMHA模块的所有 Kernel 的执行必须在A Kernel完成之后才开始执行,且C Kernel必须等 FMHA 中所有Kernel执行完成后再开始执行。如图8所示,使用多stream优化后,Multi-Head Attention 模块的多个FMHA Kernel的执行获得了很好的overlap,GPU计算资源可以得到更充分的利用。
实验结果显示,对序列数据分组和多stream优化给Multi-Head Attention模块带来了大约20%的性能提升,端到端大约提升了3.5%~3.7%。
BERT模型的最开始部分是Embedding模块。该模块由三个Embedding层、两个Add层和一个Dropout和LayerNorm层组成。通过分析发现,如果对batch_size和max_seq_len维度合并,对该模块所有算子的计算逻辑没有影响。因此,我们对该模块也进行了unpad的计算优化。实验结果显示,BERT Embedding模块使用unpad优化后,端到端获得了0.4%~0.9%左右性能提升。
为了实现负载均衡、改善模型收敛性,NVIDIA提出了一种名为Exchange Padding的多卡输入数据编排方法[6],如图9所示。具体的步骤为(假设输入数据已经padding至最大序列长度):
-
对所有卡上的padding后的输入数据进行AllGather操作,使得每个卡均能获得所有卡上的全量输入数据。
-
每个卡根据实际序列长度( padding 前的实际序列长度)分别对AllGather后的数据进行排序。
-
根据每个卡的rank id进行Interleaving Slice操作,得到每个卡上最终的输入数据,即rank id为i的GPU进程获取到的样本编号为i, i + num_devices, i + 2 * num_devices, ...,其中 num_devices为GPU总数。例如,在图9中,Worker 0分到了编号为0和2的样本数据,Worker 1则分到了编号为1和3的样本数据。
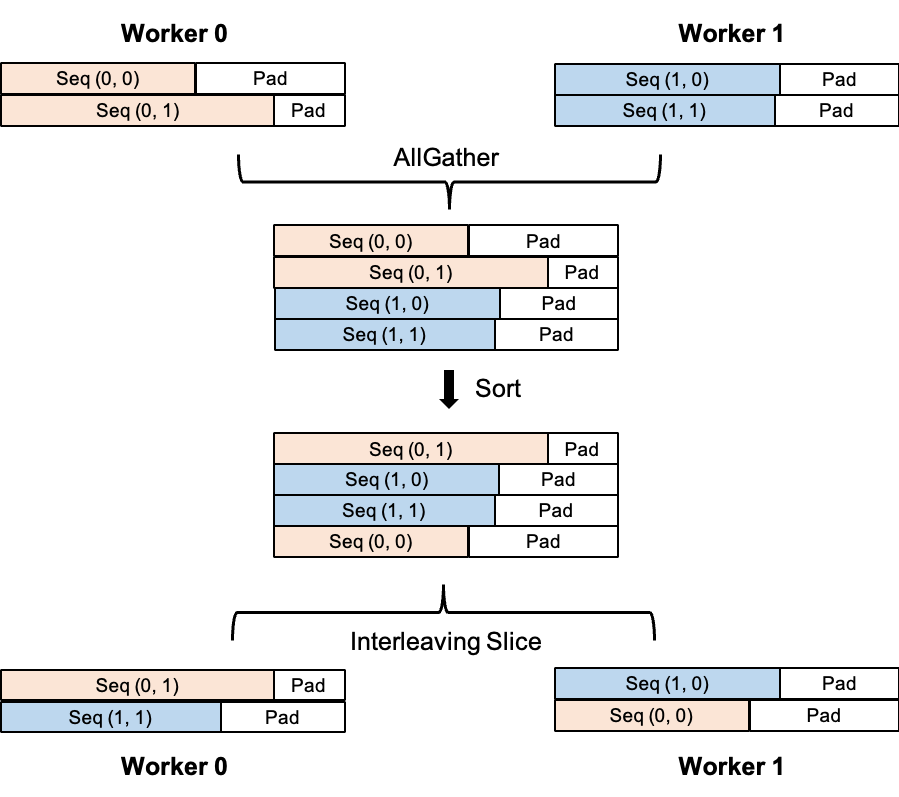
图9. Exchange Padding的流程
在NGC PyTorch的实现中,Exchange Padding的三个步骤均是在GPU上进行的,而且Exchange Padding和模型训练是串行进行的,每个mini-batch训练前必须先等待Exchange Padding操作完成。然而,在MLPerf极限性能优化的情况下,GPU计算负载是非常重的,利用率往往可达98%以上,在GPU上进行Exchange Padding操作必然会消耗一定的GPU计算资源,影响模型训练性能;此外,Exchange Padding和模型训练过程串行进行也会降低模型整体训练效率。
基于此,我们提出了一种在CPU端做Exchange Padding的方法,具体的Timeline如图10所示,整体端到端训练时间提升了1.5%。具体方式为:
-
Exchange Padding操作在CPU端完成,减少GPU端的计算负载。
-
在模型训练过程中,预先对下一个mini-batch的输入数据进行Exchange Padding操作,使得CPU端的Exchange Padding操作和GPU端的模型训练操作完全overlap起来,消除现有方案每个mini-batch开始前必须串行等待Exchange Padding完成所耗费的时间。
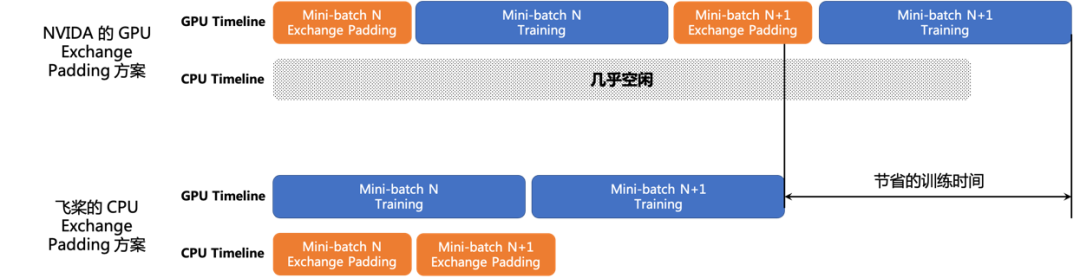
图10. CPU Exchange Padding实现方案的Timeline
在上述Exchange Padding的操作中,AllGather要求输入数据必须是带padding信息的。因此在输入变长Encoder模块前,必须进行padding移除的操作来去除填充的无用token。在这个padding移除的过程中会产出许多耗时较短的算子,这些算子仅与输入数据相关,与模型参数无关。在NVIDIA的BERT实现中,这些小算子均是在GPU中计算的,且与训练过程串行进行,影响模型训练速度。借助我们提出的CPU端的Exchange Padding操作,我们将这些小算子的计算从GPU端全部挪到CPU端进行,所有计算均与Exchange Padding过程一同完成,使得这些小算子的计算完全与模型训练过程overlap起来,测试结果表明,此项优化策略带来了1.3%的端到端性能提升。
在深度学习训练中,高性能算子开发与优化是非常重要的一环。对于单个算子而言,飞桨框架通过提高算子并行度、使用更优的GPU指令、减少GPU仿存开销等方式对进行优化,提升算子性能。对于多个算子而言,飞桨通过算子融合的方式,减少仿存开销和CUDA Kernel Launch延时 ,以发挥GPU的极限性能。
对于BERT模型来说,混合精度是提升训练速度的有效方法,除了sum和mean之外的几乎所有算子都采用FP16进行计算。然而FP16类型的Embedding反向性能存在一定的问题。Embedding反向计算时,不同线程可能会写入同一个结果,因此会存在写冲突问题。为此,飞桨采用原子指令来解决写冲突,当输入为FP16类型时,底层会调用CUDA的 atomicAdd(half* ) 指令进行计算。然而,由于硬件对该指令的支持不够好,使得Embedding算子的耗时比较异常,达到了模型总耗时的9.1%左右,严重影响了模型的吞吐。
针对此问题,飞桨使用了CUDA的atomicAdd(half2* ) 指令替换原先的 atomicAdd(half* ) ,对Embedding算子的反向计算进行了优化。相比于 atomicAdd(half* ) ,atomicAdd(half2* ) 能一次完成两个FP16数据的原子加法,而且在GPU底层有相关的硬件加速支持,性能更优。优化后,Embedding 算子总耗时占比从原来的9.1%降到了0.5%,模型端到端获得了10%左右的性能提升。
cuBLASLt提供了支持GEMM和其他小算子融合的API [7]。我们充分利用 cuBLASLt的融合API对BERT模型中广泛存在的Linear算子进行融合优化。如下所示,前向和反向过程中,分别对GEMM和bias (广播加法操作),以及GEMM和 dbias(规约操作) 进行融合。
实验结果显示,使用该优化,单模块大约提升5%~20%,模型端到端大约获得5.5%性能提升。
BERT模型常见Residual Add等分支结构,同一个Tensor在前向阶段可能同时作为Linear和另一个算子的输入,从而导致反向阶段会出现一次梯度累加操作,即在反向阶段可能会出现如下算子列表:
dX_1 = ... # X的一部分梯度源自于另一个OP
dX_2 = linear_grad(dOut, Weight)
dX = dX_1 + dX_2
反向阶段需要计算linear_grad和add两个OP。根据矩阵乘法反向求导的数学公式,Linear的反向也是矩阵乘法操作,因此上述计算公式等价于:
dX_1 = ...
dX.ShareDataWith(dX_1) # dX与dX_1共享显存空间
dX = dX + linear_grad(dOut, Weight) = dX + matmul(dOut, transpose(Weight))
其中,dX=dX+matmul(dOut, transpose(Weight))可以利用cuBlasLt GEMM API设置beta参数等于1来实现,从而将原先的linear_grad和add两个算子融合为一个新的linear_grad算子(cublasLt GEMM API beta=1),减少框架调度开销和Kernel Launch Latency。实际测试结果表明,此优化带来了端到端1.1%的训练加速效果。
算子dropout
与算子residual add+layer_norm融合
在Encoder模块中,有两次dropout+residual add+layer_norm的调用。由于dropout算子和residual add算子都属于elementwise类型的算子,且 layer_norm属于批规约类型的算子,因此,这三个算子可以非常自然的按照 layer_norm的并行逻辑进行融合。相比融合前,前向和反向Kernel launch次数由原来的6次降为2次,GPU显存访问量大约由原来的12次降为4次。实验结果显示,使用该优化,单模块大约提升5%~30%,模型端到端大约获得2.3%性能提升。
在MLPerf BERT模型分布式训练过程中,LAMB优化器需要进行L2-Norm等复杂计算,计算量往往较大。借鉴NVIDIA Apex library的DistributedFusedLAMB的实现,我们在飞桨上实现了优化版本的分布式优化器,其底层原理是通过ZeRO Stage 2[2]的方式,将每个卡上需要更新的参数量减少至原来的1/num_devices (其中,num_devices 为GPU总数),以减少计算开销。
在此基础上,我们针对优化器内部的重点计算Kernel进行了深度优化。DistributedFusedLAMB 内部会将FP16参数梯度、FP16参数、FP32 Master Weight的显存空间融合为连续空间,以减少通信开销。DistributedFusedLAMB需要计算以下几个重要的CUDA Kernel:
-
FP16参数梯度的平方和,用于做global norm clipping。
-
-
每个参数对应的Trust Ratio Tensor的L2-Norm。
在NVIDIA Apex library的DistributedFusedLAMB的实现中,以上3 个CUDA Kernel都是通过MultiTensorApply的方式来实现的,其原理是将每个Tensor按给定的chunk_size切分为一系列的chunk,并每隔一定数量的Tensor或chunk launch一次CUDA Kernel,每个CUDA Kernel的同一个block对同一个chunk内的数据进行处理。在NVIDIA Apex library的实现中,launch Kernel的时候需要记录每个chunk的起始显存指针,每个CUDA Kernel的入参必须包含N 个chunk 的起始显存指针( N 为 chunk 的数量),因此限制了每个CUDA Kernel处理的Tensor或chunk数量( CUDA Kernel 入参总大小一般不能超过4KB),即CUDA Kernel的gridDim大小,并行度较低。
然而,在 DistributedFusedLAMB的实现中,FP16参数梯度、FP16参数、FP32 Master Weight的显存空间是连续的。利用显存连续的特点,我们对CUDA Kernel的入参进行优化,仅传入每个chunk所属Tensor的指针首地址和每个Tensor的长度即可。由于Tensor个数往往远小于chunk的数量,因此此方案下CUDA Kernel的gridDim大于原有方案,一方面可以提高CUDA Kernel的计算并行度,另一方面可以减少CUDA Kernel launch的个数。特别地,在计算FP16参数梯度的平方和时,由于参数梯度空间是连续的,我们可以直接调用cub::DeviceReduce来直接计算,而不需要通过MultiTensorApply的方式来完成。
利用参数、参数梯度的显存连续的特点,我们对DistributedFusedLamb中的主要CUDA Kernel进行了优化。实际测试结果表明,在MLPerf BERT模型训练中,飞桨的DistributedFusedLAMB性能较NVIDIA Apex library提升22% ,端到端带来了18.3%的性能提升,8卡加速比达到8.1至8.2 ,实现了超线性加速。
在以上讲述数据读取和模型训练负载均衡的时候,我们已经提到了飞桨的数据读取和模型训练异步执行的方案。除此以外,飞桨也默认实现了异步通信的功能。在这些基础上,我们还对模型训练和预测过程中存在的CPU与GPU间的内存/显存拷贝问题进行了优化,这些拷贝操作会阻塞GPU的异步执行,影响端到端的训练效果。
例如,学习率的值是在CPU上计算得到的,却需要在GPU上进行使用( Host to device memory copy )。为了减少CPU、GPU之间的交互,我们将学习率计算挪到GPU上。这可以借助飞桨自定义外部算子的能力,新编写一个计算学习率的算子进行实现。
又如,在每个mini-batch训练完成后,我们常常会打印出当前mini-batch的loss和accuracy等指标,但这会带来额外的Device to host memory copy。在满足MLPerf规则的前提下,我们将原先每个mini-batch均打印一次loss和accuracy的方式改为了每隔335步进行,大幅度地减少了CPU和GPU间的同步开销。
再如,在预测阶段,MLPerf需要统计全量数据集下的Masked Language Model Accuracy指标。常规的实现是,获取每个mini-batch下的Accuracy指标,然后在CPU端进行累加统计,但这会带来每个mini-batch预测均有Device to host memory copy的同步开销。我们通过新增GPU 上的 Accuracy累加统计算子,当且仅当最后一个mini-batch预测时才取出GPU上累计的Accuracy指标的值,减少同步开销。
测试结果显示,上述训练阶段的优化手段在端到端中带来了约0.4%的性能提升,预测阶段的优化手段在端到端中大约提升了0.17% 。
飞桨在MLPerf Training v2.0中获得了BERT模型训练性能世界第一的瞩目成绩。这不仅得益于飞桨框架在性能优化领域的长期耕耘,更离不开硬件生态的助力。近年来,飞桨的技术实力深受广大硬件厂商认可,合作日趋紧密,软硬一体协同发展,生态共创硕果累累。前不久(5月26日),NVIDIA与飞桨合作推出的NGC-Paddle正式上线。同时在本次MLPerf中,Graphcore也通过使用飞桨框架取得了优异成绩。未来,飞桨将继续打造性能优势,在软硬协同性能优化和大规模分布式训练方面持续技术创新,为广大用户提供更加便捷、易用、性能优异的深度学习框架。

本文封面图由AI作画神器文心·一格创作
[1]The MLPerf™ Training v2.0 results.
https://github.com/mlcommons/training_results_v2.0
[2]DeepSpeed library.
https://github.com/microsoft/DeepSpeed
[3]DeepLearningExamples library.
https://github.com/NVIDIA/DeepLearningExamples
[4]PaddleNLP library.
https://github.com/PaddlePaddle/PaddleNLP
[5]Apex unpad fmha. https://github.com/NVIDIA/apex
[6]The MLPerf™ Training v1.1 results.
https://github.com/mlcommons/training_results_v1.1
[7]cuBLASLt GEMM fusions.
https://docs.nvidia.com/cuda/cublas/index.html#cublasLtEpilogue_t
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~

