
人工智能技术的快速发展,给我们的生活和工作带来了各种有趣便利的体验。比如在视频通话和观看直播时的背景虚化、弹幕穿人等神奇的功能,给我们的视频通话及影音观看带来了更优质的体验和多维的乐趣。那这是靠什么AI黑科技实现的呢?

人像分割是将人物和背景在像素级别进行区分,通常可以分为半身人像的肖像分割和针对全身人像的通用人像分割两类。借助于深度学习技术,人像分割的效果和效率都得到快速突破,但是复杂、快速变换的人像边缘的分割精确性,以及即时的预测速度,仍是业界高手持续发力优化的地方。
而飞桨PaddleSeg此次升级发布的PP-HumanSeg v2人像分割方案,以96.63%的mIoU精度,手机端15.86ms的推理耗时,再次刷新开源人像分割算法SOTA指标。该方案可与商业方案媲美,而且支持零成本、开箱即用!
相比PP-HumanSeg v1,肖像分割模型的推理速度提升45.5%,mIoU精度提升3.03%,可视化效果更佳。通用人像分割模型的推理速度最高提升5.7%,mIoU精度最高提升6.5%。
不仅如此,PP-HumanSeg v2开源了PP-HumanSeg-14K数据集,其中包含14000张室内场景半身人像的图片。同时在易用性和部署全流程打通方面,PP-HumanSeg v2也做足了功课,致力提供更佳的开发体验。
还等什么,还不赶紧尝试将PP-HumanSeg v2方案应用到人像分割的业务产品中!
点击阅读原文获得链接
https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.6/contrib/PP-HumanSeg
PP-HumanSeg v2人像分割方案提供了肖像分割、通用人像分割、全流程训练和部署的能力。
肖像分割是对半身人像的图片进行分割,主要适用于视频通话和会议等场景。由于广泛部署到Web、手机和边缘设备,肖像分割在兼顾分割精度的前提下,需要具有极快的推理速度。PP-HumanSeg v2发布了全新肖像分割模型,主要做了三点改进:设计新的模型结构、使用迁移学习预训练、调整输入图像尺寸。
我们选择PaddleSeg近期发布的超轻量级系列语义分割模型作为基础,进行特定优化得到肖像分割模型,整体结构如图2所示。首先,考虑到模型的算量要求很高,我们使用MobileNetV3作为骨干网络提取多层特征。分析发现MobileNetV3的参数主要集中在最后一个Stage,在不影响分割精度的前提下,我们只保留MobileNetV3的前四个Stage,顺利减少了68.6%的参数量。然后,对于16倍下采样特征图,我们使用SPPM模块汇集全局上下文信息。最后,我们使用三个Fusion模块不断融合深层语义特征和浅层细节特征。其中,最后一个Fusion模块再次汇集不同层次的特征图,输出分割结果。
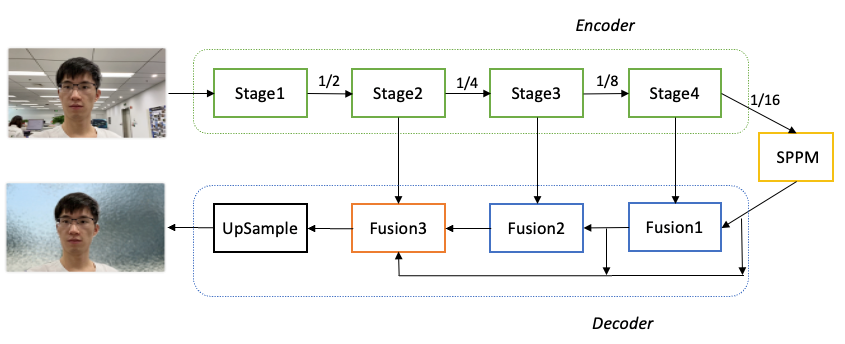
图2 PP-HumanSeg v2肖像分割模型结构
对于肖像分割任务,数据过少是影响分割精度的重要因素。PaddleSeg开源的PP-HumanSeg-14K数据集,有14000张室内场景半身人像的图片,一定程度缓解了数据过少的问题。针对该问题,我们进一步使用迁移学习的方法来提高模型的分割精度和泛化能力。首先,我们在大规模的通用人像分割数据集上进行预训练,然后再针对PP-HumanSeg-14K半身人像数据集进行微调。
大家通常会调整模型的深度和宽度来平衡分割精度和推理速度,而模型的输入尺寸也是一个需要重视的变量。手机和电脑端最常见的拍摄尺寸是1028x720,PP-HumanSeg v1肖像分割模型推荐将图片缩放为398x224进行预测。为了追求极致的推理速度,PP-HumanSeg v2肖像分割模型的最佳输入尺寸进一步缩小为256x144,将推理速度提升了52%(相比输入尺寸398x224)。更小的输入尺寸,不可避免减少了输入信息量,但是得益于PP-HumanSeg v2模型具有更强的学习能力,最终也有不错的分割效果。
基于上述改进,PP-HumanSeg v2肖像分割模型对比PP-HumanSeg v1,推理速度(手机端)提升45.5%,mIoU精度提升3.03%,可视化效果更佳。此外,该模型支持手机拍摄的横屏和竖屏输入图像,针对室内场景可以开箱即用。
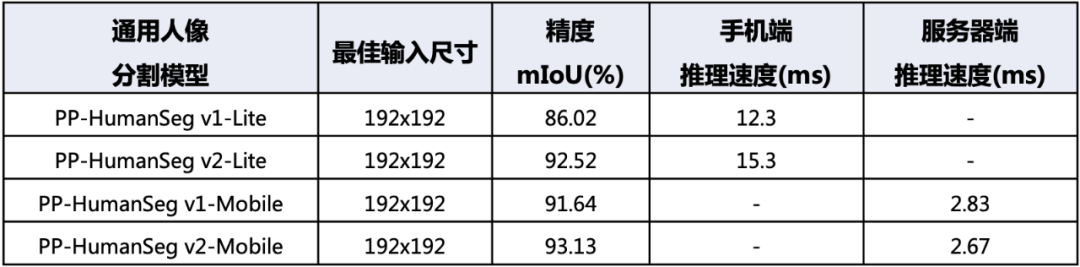
针对通用人像分割任务,我们使用PaddleSeg的SOTA模型在大规模数据集上训练,发布了两个型号的PP-HumanSeg v2通用人像分割模型。PP-HumanSeg v2-Lite通用人像分割模型,使用和肖像分割模型类似的结构,适合部署在手机端ARM CPU上。相比PP-HumanSeg v1-Lite模型,它的精度mIoU提升6.5%。PP-HumanSeg v2-Mobile通用人像分割模型,使用PaddleSeg自研的PP-LiteSeg模型结构,适合部署在服务器端GPU上。相比PP-HumanSeg v1-Mobile模型,它的精度mIoU提升1.49%,推理速度提升5.7%。
由于通用人像分割任务的场景变化很大,大家需要根据实际场景评估PP-HumanSeg通用人像分割模型的精度。如果满足业务要求,大家可以直接使用。如果不满足业务要求,大家可以基于PP-HumanSeg通用人像分割模型进行进一步优化,可以达到事半功倍的效果。
PP-HumanSeg v2人像分割方案不仅开源了更佳的模型,还提供了二次训练和部署的功能代码。使用提供的肖像分割和通用人像分割配置文件,大家只需要准备好数据即可训练。模型支持在不同硬件上进行应用部署,包括NVIDIA GPU、X86 CPU、ARM CPU、浏览器Web。
此外,我们对模型预测结果使用形态学后处理操作,滤除背景干扰,保留人像主体。如下图所示,原始预测图像中每个像素数值表示前景的概率。首先使用阈值操作滤除概率较小的像素,然后使用腐蚀和膨胀操作消除细条,腐蚀操作的核尺寸小于膨胀操作,掩码图像作用在原始预测结果上,得到最终预测的结果。可见,通过形态学后处理,可以有效提升人像分割的可视化效果。

图 3 形态学后处理的分割图像
贴心的PaddleSeg团队还为大家准备了在线体验PP-HumanSeg v2人像分割能力的小工具,支持在线上传图片即可完成人像抠图,并下载效果图。
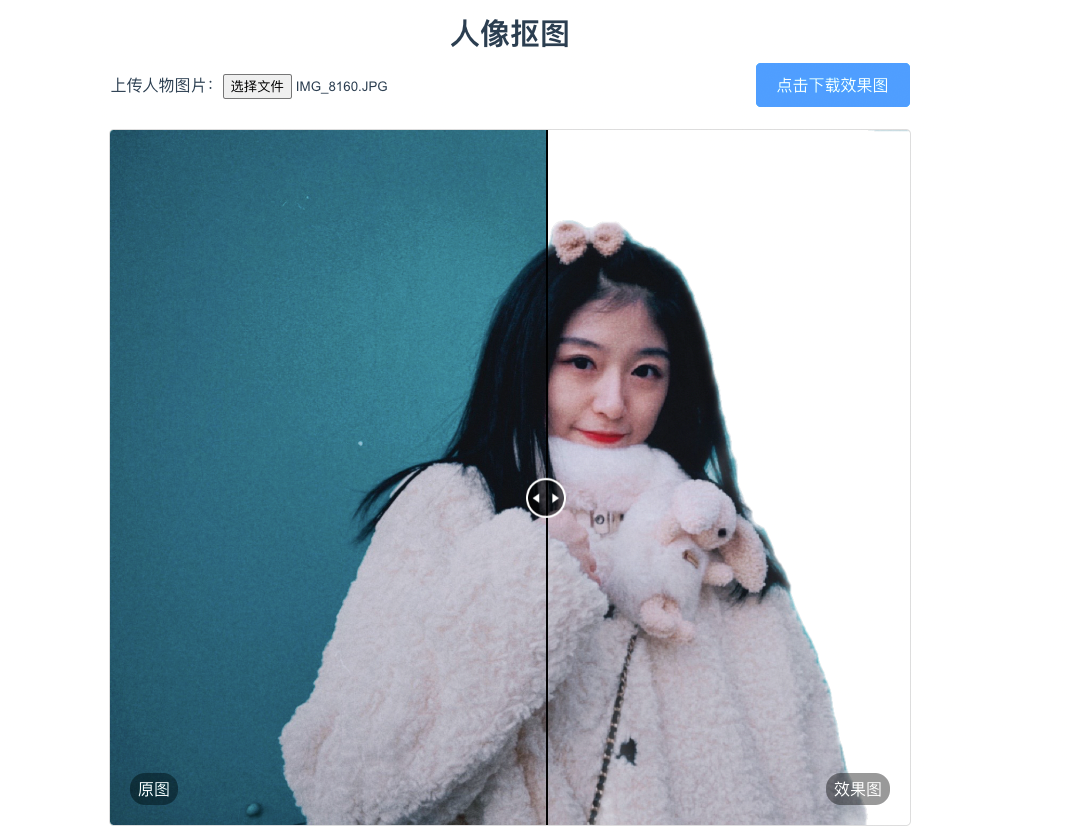
图4 PP-HumanSeg v2在线网站体验效果图
加入PaddleSeg PP-HumanSeg v2技术交流群,还有更多惊喜福利等你来拿喔!
福利一:获取PP-HumanSeg-14K半身人像数据集
福利二:获取PaddleSeg详解本次升级内容的直播课链接
福利三:获取PaddleSeg团队整理的重磅学习礼包,包括:
-
语义分割场景应用合集:包括Matting扣图、交互式分割、人像分割、3D医学图像分割等10+垂类模型,覆盖通用、工业、互娱、医疗的主要分割垂类应用
-
-
PaddleSeg实操产业范例:车道线分割、工业瑕疵检测等10+全流程项目
*Tips:所有福利都在群公告中,等大家来获取!

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~



