本文将对Pipelines三大特色进行解读,全文约2千字,预计阅读时长1分半。
企业的NLP系统需求多种多样,例如智能客服、智能检索、文档信息抽取、商品评论观点分析等,虽然这些系统的外在形态千差万别,但是从技术基础设施角度看:
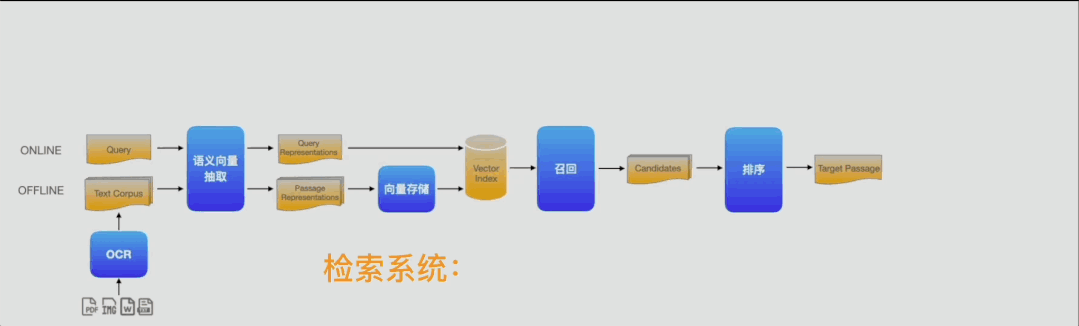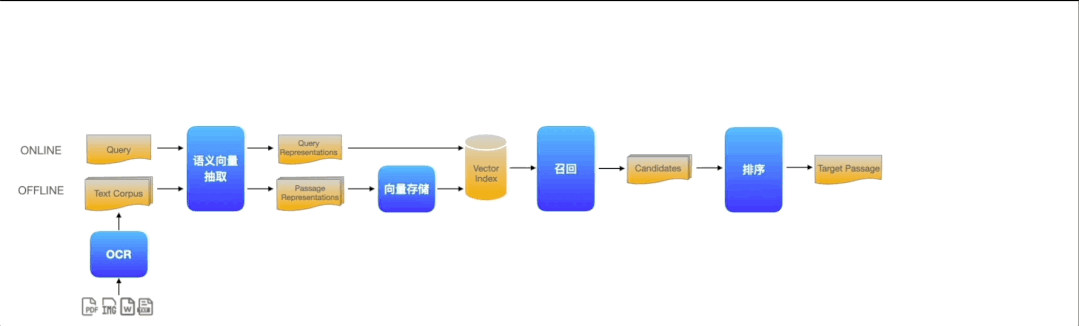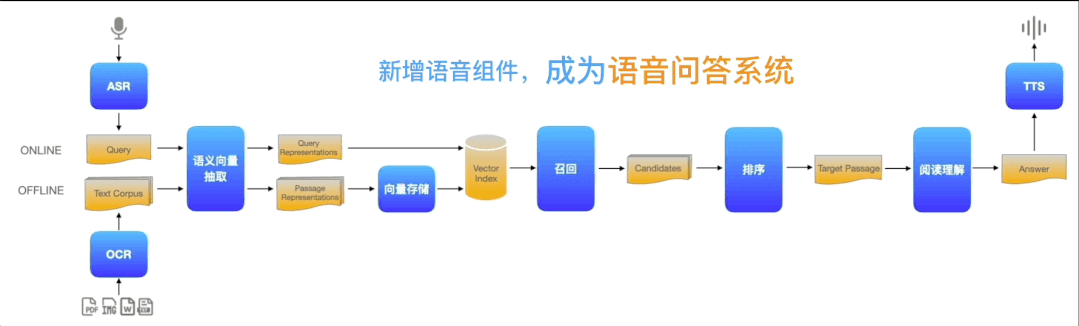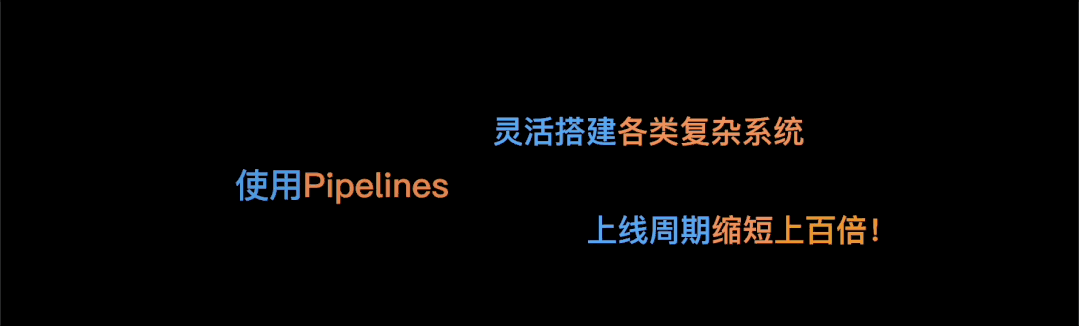
图1:通过增删基础组件实现多个复杂系统的迁移
如上图,举例来说:
(1)语义检索系统可以抽象为文档解析、语义向量抽取、向量存储、召回、排序5个基础组件
(2)在此基础上,只需串接1个答案定位模型组件即可构成阅读理解式问答系统
(3)更进一步,在问答流水线的起点和终点分别加入ASR(语音转换文本)和TTS(文本转换语音)2个模型组件即可构成智能语音客服系统
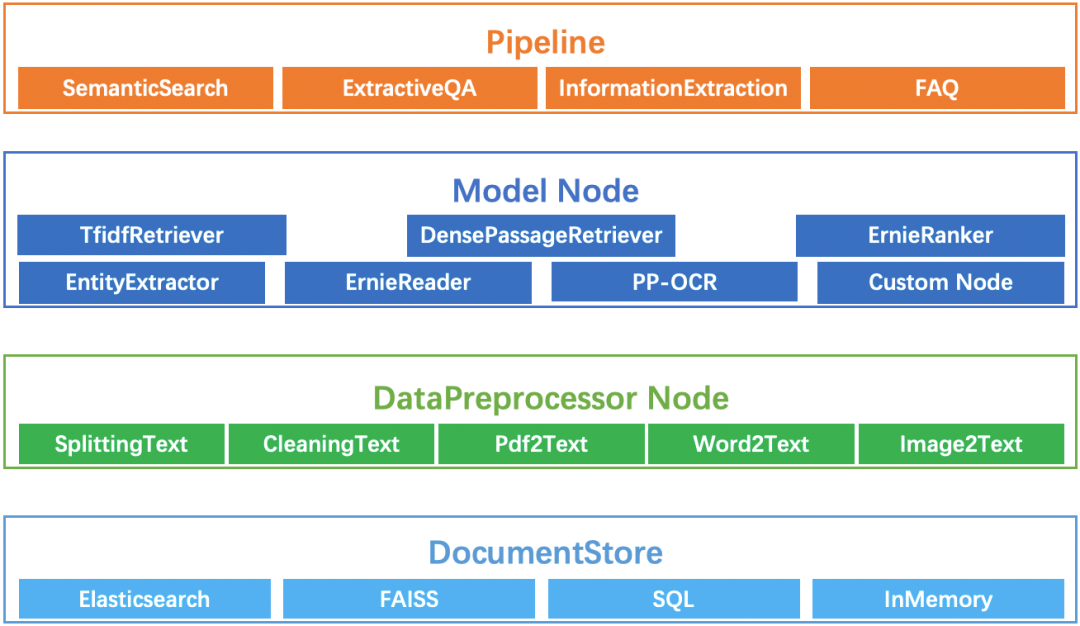
图2:Pipelines基础组件示例
Pipelines除深度兼容PaddleNLP中的模型外,还可兼容飞桨生态下任意模型、AI开放平台算子、其它开源项目如Elasticsearch等作为基础组件。用户可通过对基础组件进行扩展来满足个性化需求,从而实现任意复杂系统的灵活定制开发。
戳官方地址,查看详情:

除小模型外,Pipelines中也可直接使用PaddleNLP近期开源的24层模型ERNIE 1.0-Large-zh-CW,效果优于同等规模的RoBERTa-wwm-ext-large。

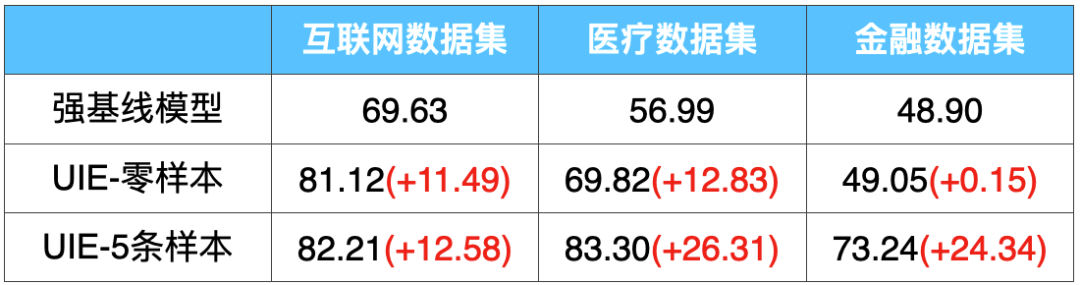
除多任务通用的预训练模型外,Pipelines中还集成了面向特定任务的模型,如通用信息抽取技术UIE,其多任务统一建模特性大幅降低了模型开发成本和部署的机器成本,基于Prompt的零样本抽取和少样本迁移能力更是惊艳!例如,在金融领域的事件抽取任务上,仅仅标注5条样本,F1值就提升了25个点!
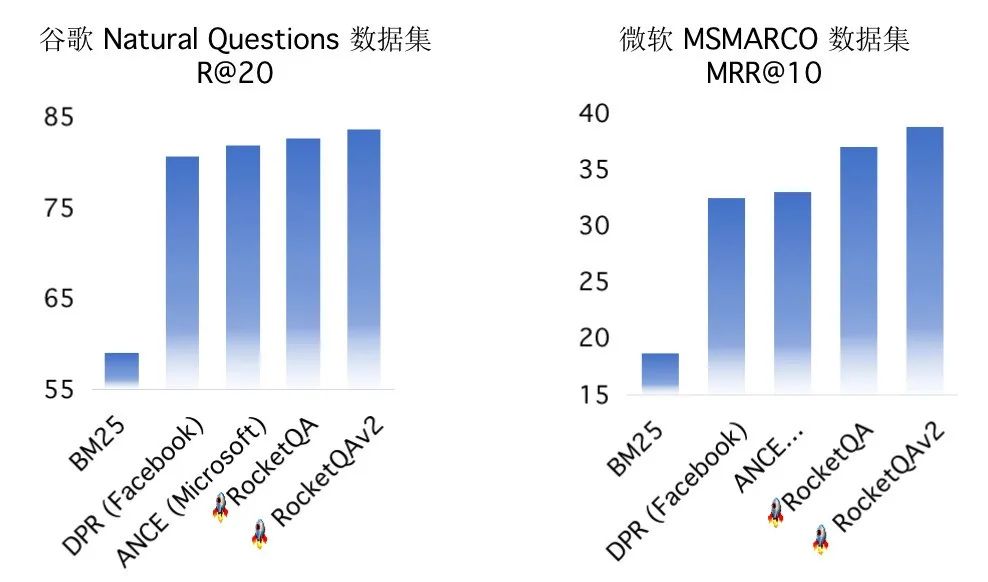
这些强大的NLP模型可以直接使用Pipelines的模型Node来调用,例如,使用下面的方式就可以使用效果突出的RocketQA语义召回技术,是不是十分简单粗暴!
retriever = DensePassageRetriever(
document_store=document_store,
query_embedding_model=“rocketqa-zh-dureader-query-encoder”,
passage_embedding_model=“rocketqa-zh-dureader-query-encoder”,
max_seq_len_query=args.max_seq_len_query,
max_seq_len_passage=args.max_seq_len_passage,
batch_size=args.retriever_batch_size,
use_gpu=use_gpu,
embed_title=False
)端到端全流程
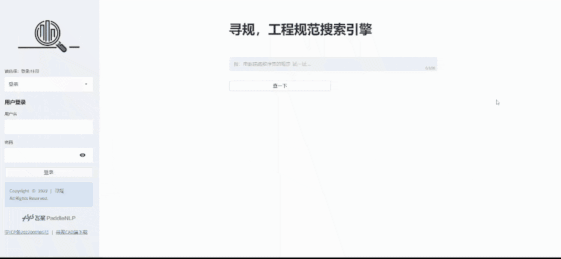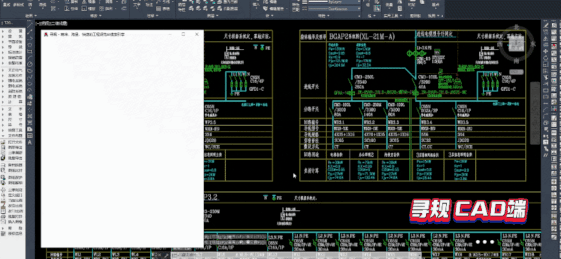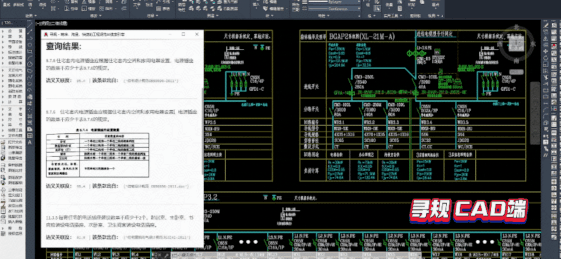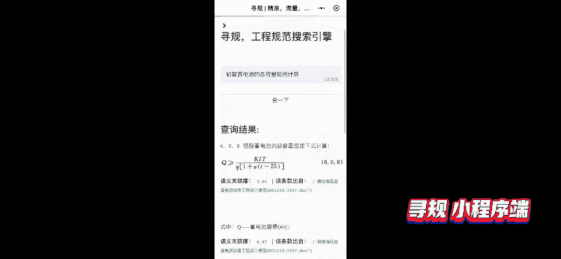
Pipelines内置的语义检索系统包括文档解析(支持PDF、WORD、图片等解析)、海量文档建库、模型组网训练、服务化部署、前端Demo界面(便于效果分析)等全流程功能。

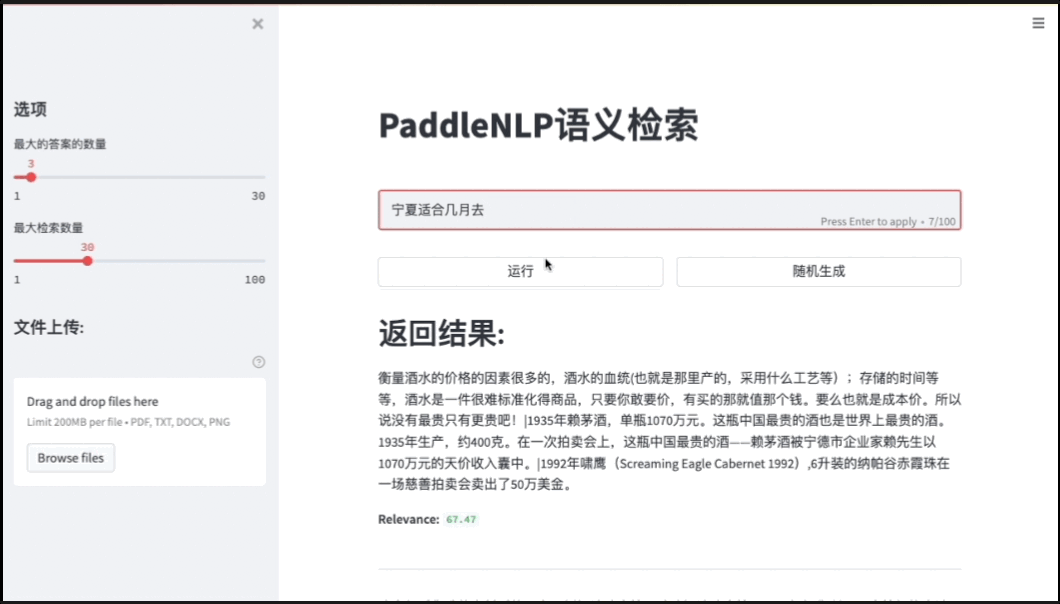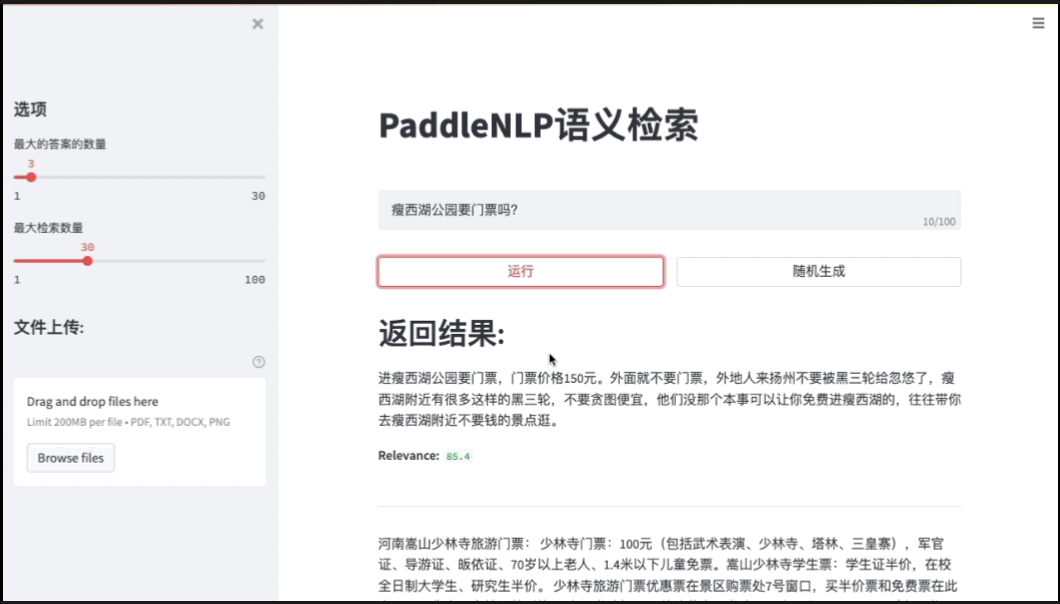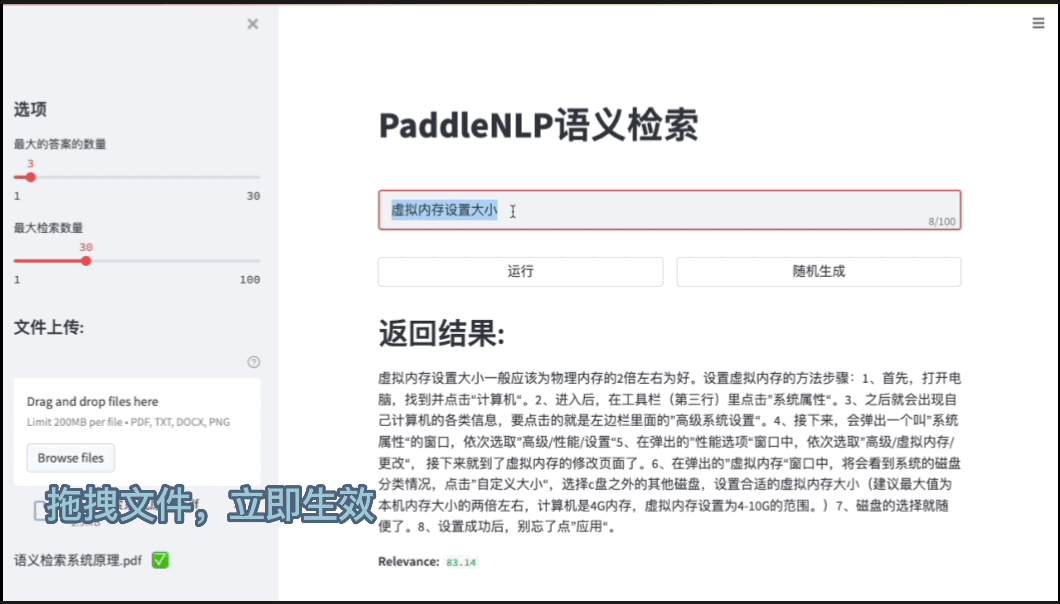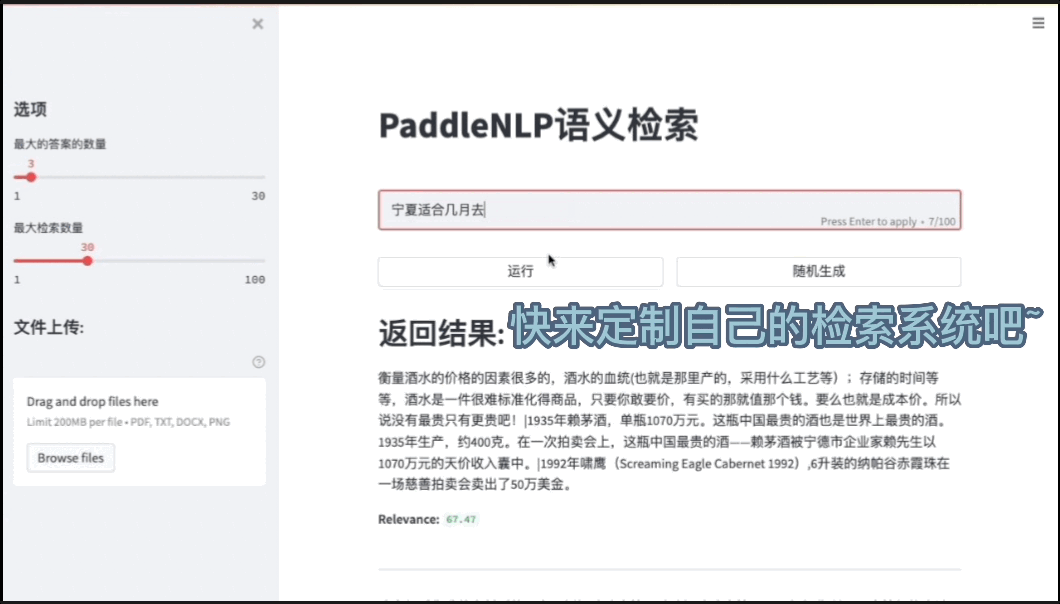 图6:检索系统前端Demo
图6:检索系统前端Demo
效果领先速度快
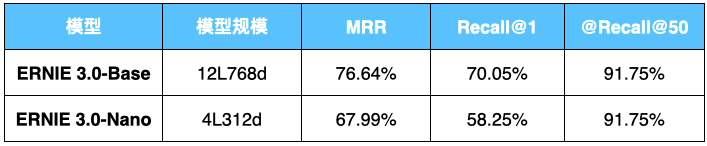
表3:Pipelines检索系统精度(数据集:DuReader_retrieval )
低门槛一键部署
用户可以基于Docker采用如下命令默认一键部署端到端语义检索系统。
# 启动GPU容器
docker-compose -f docker-compose-gpu.yml up -d(https://xungui365.com/)
预置更丰富的基础组件库
支持跨模态通用文档预训练模型ERNIE-Layout的调用,支持图片、文档的解析;
支持飞桨语音模型库PaddleSpeech的PP-TTS和PP-ASR各类语音模型串联;
支持PaddleNLP通用信息抽取UIE、文本分类等NLP组件直接调用。
预置更多流水线系统
多模态信息抽取系统;
跨模态智能文档问答系统;
智能语音指令系统系统。
欢迎来自学术界和工业界的朋友加入PaddleNLP Pipelines开源项目,扩展新的组件,或者定制自己的NLP流水线系统。欢迎各位提需,加入社区讨论。
https://github.com/PaddlePaddle/PaddleNLP
为了充分和开发者交流产品使用中遇到的难题,共同进步,PaddleNLP核心开发成员将和大家线上交流,针对性讨论大家遇到的问题和需求。欢迎各位扫码进群,获取线上会议链接!限定200席,报满为止。报名还可获得:
入群方式
微信扫描下方二维码,关注公众号,填写问卷后进入微信群
查看群公告领取福利
PaddleNLP项目地址
https://github.com/PaddlePaddle/PaddleNLP
Gitee:
https://gitee.com/paddlepaddle/PaddleNLP

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~