信息抽取是NLP领域的重要任务之一,想必各位有信息抽取业务的NLPer都使用过UIE(Universal Information Extraction,通用信息抽取)技术了。UIE多任务统一建模特性大幅降低了模型开发成本和部署机器成本,相较于传统的预训练-微调范式,UIE基于Prompt的零样本抽取和少样本迁移能力更是惊艳!例如,在金融领域的事件抽取任务上,仅仅标注5条样本,F1值就提升了25个点!
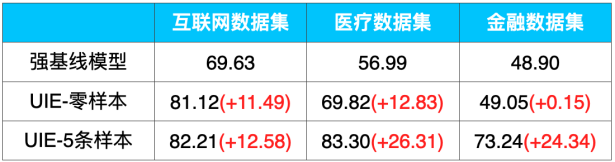
表1:UIE在中文信息抽取数据集上零样本和小样本效果
UIE两大升级点
UIE-M介绍
UIE-M基于百度自研的多语言预训练模型ERNIE-M。作为UIE系列的多语言版本,UIE-M模型不仅支持使用中文Prompt抽取中文和使用英文Prompt抽取英文,还支持中英文交叉抽取,例如,输入英文Prompt,能够同时抽取中文和英文文本中的关键信息(如下图),可以说非常酷炫了!仅需3行代码,调用PaddleNLP Taskflow API,即可快速使用:
>>> from pprint import pprint
>>> from paddlenlp import Taskflow
>>> schema = ['Time', 'Player', 'Competition', 'Score']
>>> ie = Taskflow('information_extraction', schema=schema, model="uie-m-base", schema_lang="en")
>>> pprint(ie(["2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!", "Rafael Nadal wins French Open Final!"]))
[{'Competition': [{'end': 23,
'probability': 0.9373889907291257,
'start': 6,
'text': '北京冬奥会自由式滑雪女子大跳台决赛'}],
'Player': [{'end': 31,
'probability': 0.6981119555336441,
'start': 28,
'text': '谷爱凌'}],
'Score': [{'end': 39,
'probability': 0.9888507878270296,
'start': 32,
'text': '188.25分'}],
'Time': [{'end': 6,
'probability': 0.9784080036931151,
'start': 0,
'text': '2月8日上午'}]},
{'Competition': [{'end': 35,
'probability': 0.9851549932171295,
'start': 18,
'text': 'French Open Final'}],
'Player': [{'end': 12,
'probability': 0.9379371275888104,
'start': 0,
'text': 'Rafael Nadal'}]}]UIE蒸馏版介绍
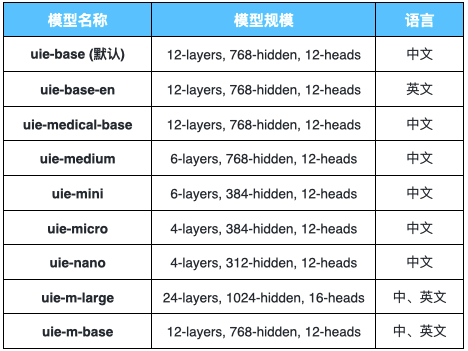
图1:PaddleNLP中开源的UIE模型
以上模型能够满足大部分开发者的需求。针对某些对性能要求极高或硬件性能较差的场景,PaddleNLP又双叒叕开源了UIE蒸馏版,进一步提升训练和预测性能。
建议各位STAR收藏起来
UIE在金融风控
业务中的应用
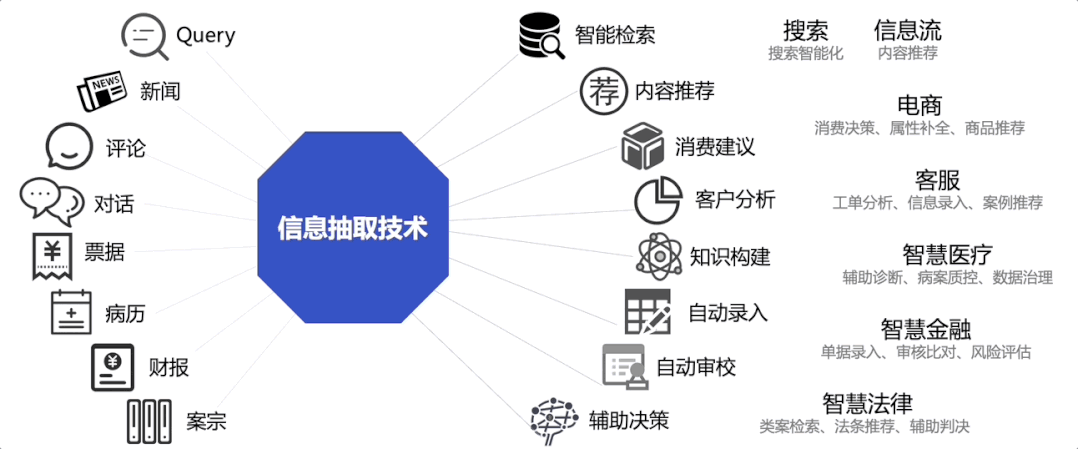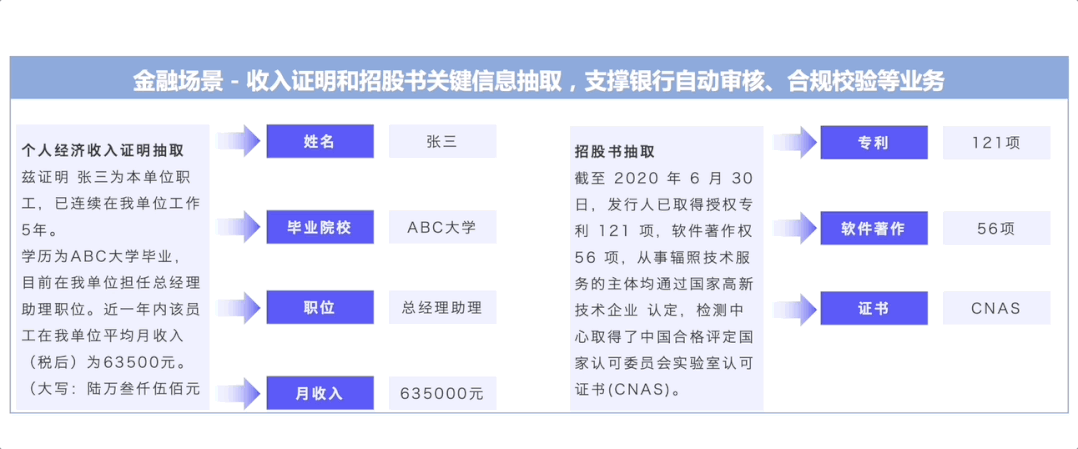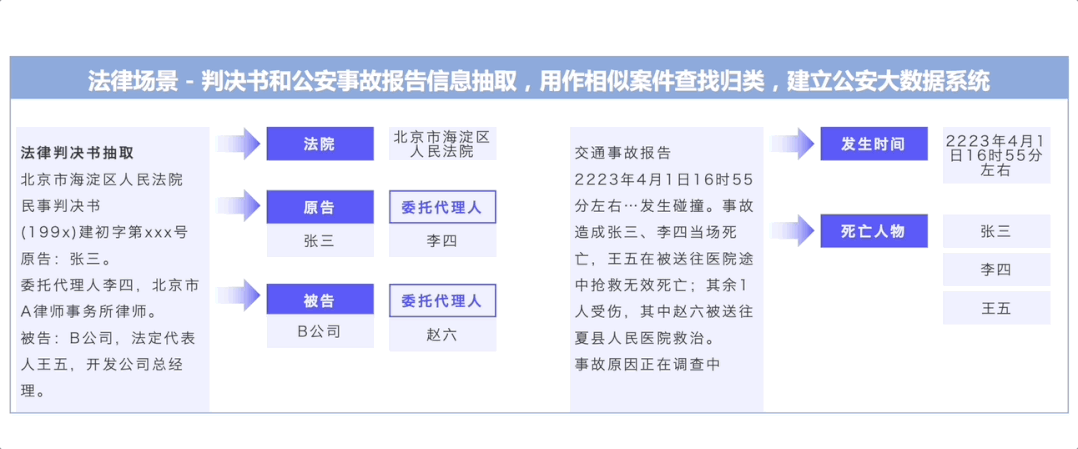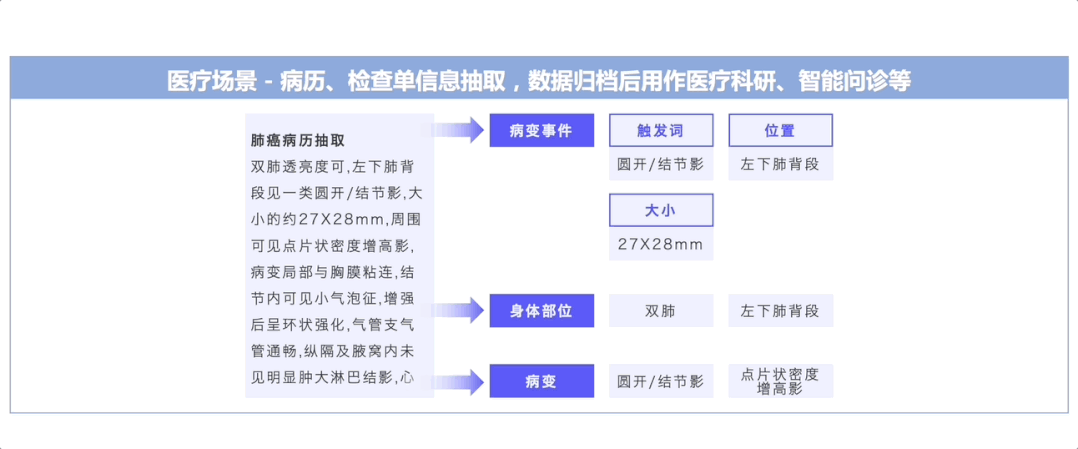
图2:UIE在各行业中的应用示例
如上图所示,UIE发布以来,已被广泛应用于金融、医疗、互联网等各行各业中。下面以金融领域——上市公司风险识别业务为例,介绍UIE的行业应用效果。
针对证监会、银监会发布的监管处罚的公告,上市公司公告中对于证券价格影响较大的事件、媒体发布的关于损害公司声誉的负面言论等各类风险舆情,业务人员需要定时进行搜索、归集,然后撰写每日风险总结报告。人工进行公告信息抽取不仅工作量繁重,且准确率与覆盖率不足,难以满足日益增长的数据量以及快节奏的需求变动。目前,已有众多金融科技企业应用UIE技术,解决了这一难题。

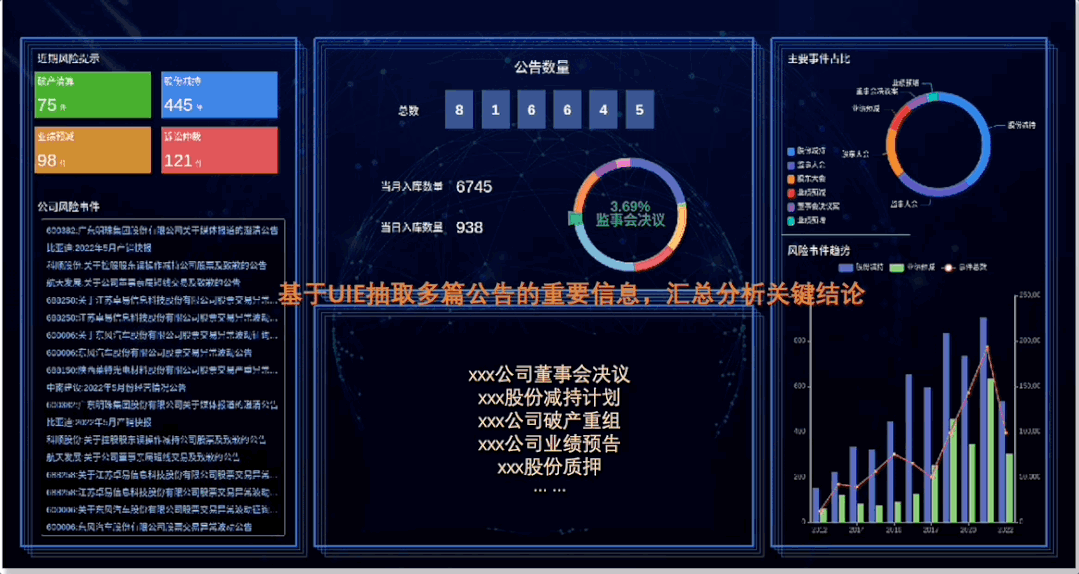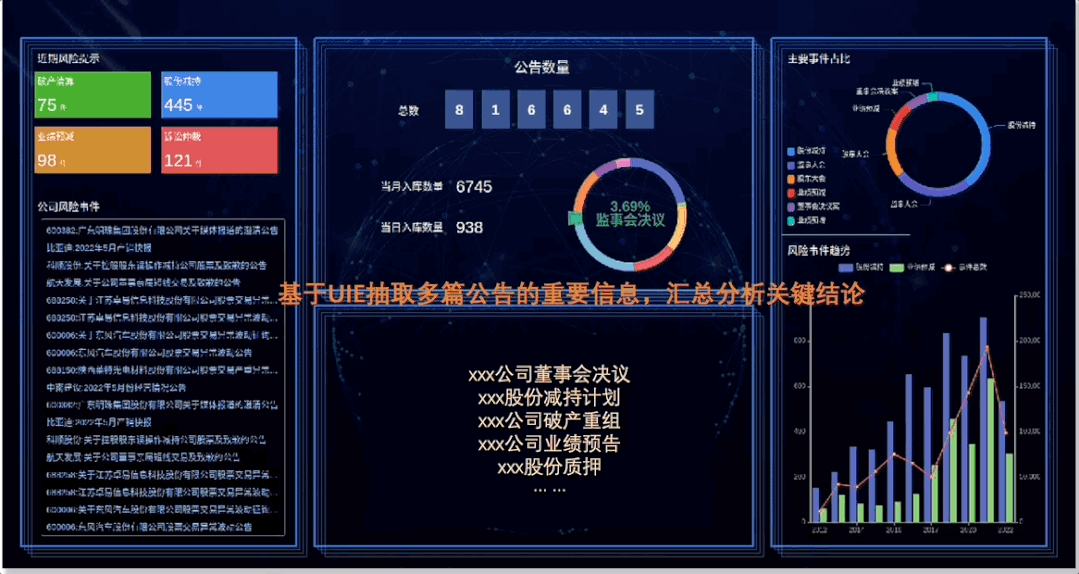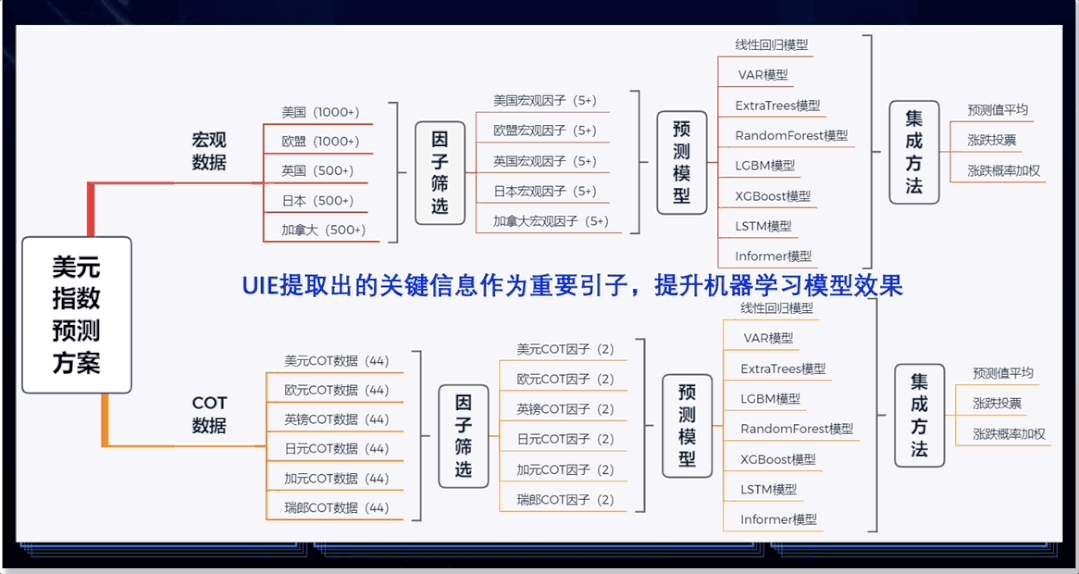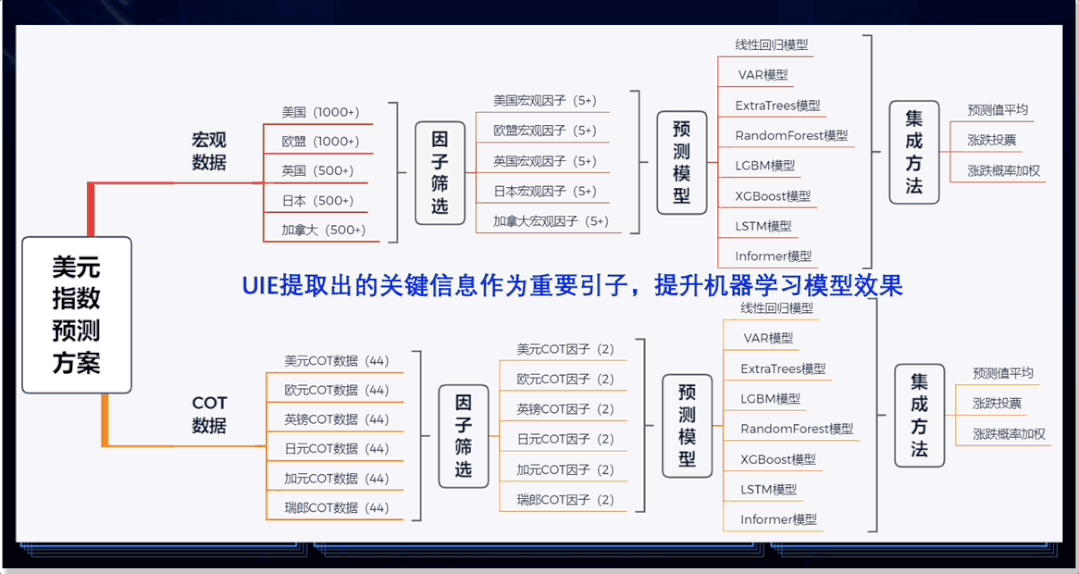
图3:上市公司信息抽取效果直观展示
应用一:从微观(单篇)和宏观(多篇)层面分析、汇总、展示重要信息;
图4:UIE在金融场景中的典型应用
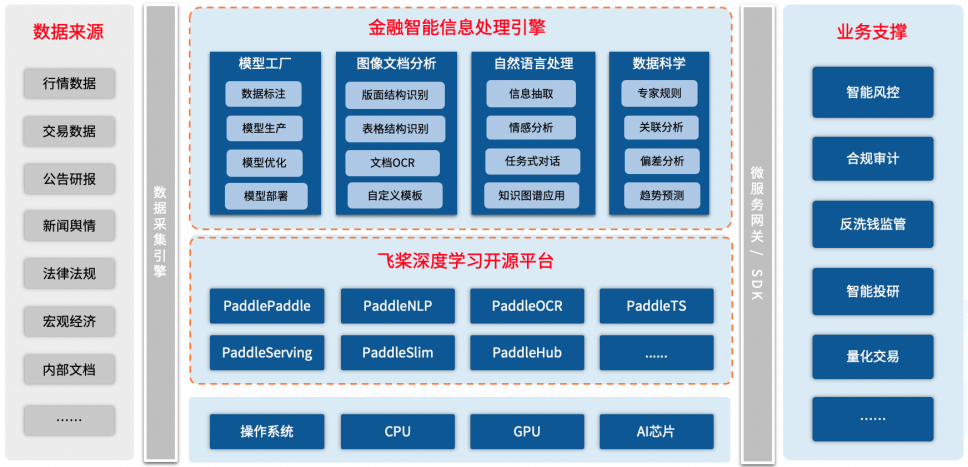
金仕达作为资本市场专业化技术服务商,依托在监管科技领域丰富的业务积累和对场景的深度理解,运用飞桨深度学习平台,采用NLP(自然语言处理)、数据科学等技术构建金融智能信息处理引擎,支撑智能风控、合规审计、反洗钱、量化交易等核心业务。
需求理解不对称,客户说的真的是他想要的吗?
场景方案复用性差,只能做定制化解决方案吗?
AI技术与客户需求间的鸿沟巨大,如何逾越?
金融领域机器学习、深度学习之谜?
附:“乘风而起,AI赋能智慧金融创新发展”系列课程海报(如已在前文扫码入群,则报名成功,无需重复操作)
欢迎STAR支持:
参考
[1] Unified Structure Generation for Universal Information Extraction
[2]https://github.com/PaddlePaddle/PaddleNLP/blob/develop/model_zoo/ernie-3.0
拓展阅读
四大"AI+金融"场景,10+真实产业范例,智慧金融行业实战课火爆开启

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~