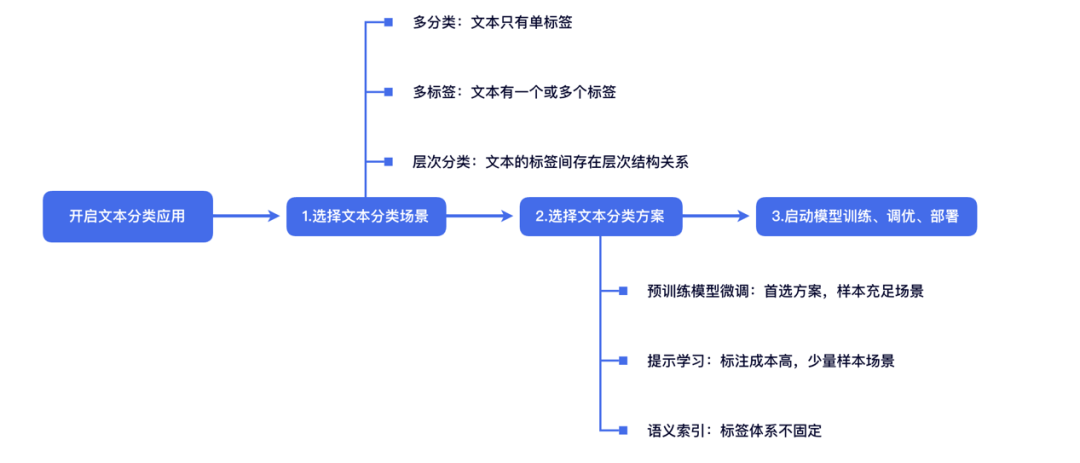
方案全覆盖:涵盖文本分类高频场景,开源微调、提示学习、基于语义索引多种分类技术方案,满足不同文本分类落地需求;
模型高效调优:强强结合数据增强能力与可信增强技术,解决脏数据、标注数据欠缺、数据不平衡等问题,大幅提升模型效果;
如有帮助,欢迎STAR支持我们的工作,项目地址:
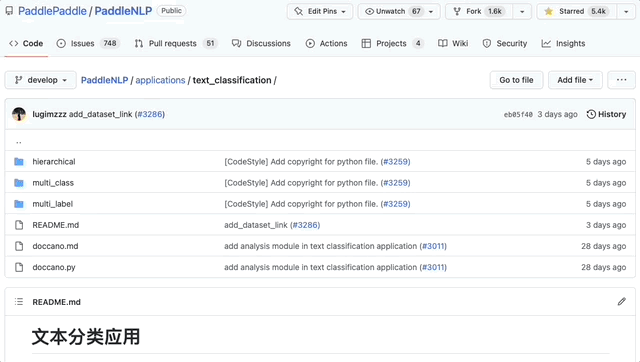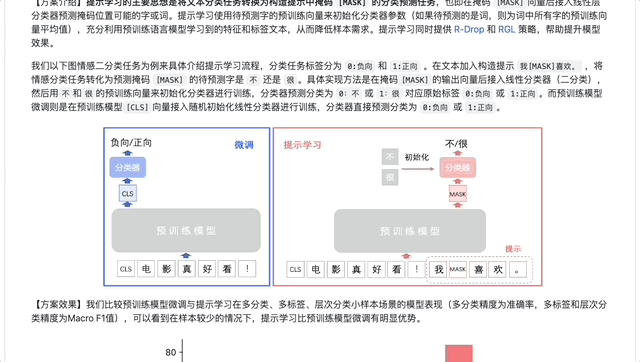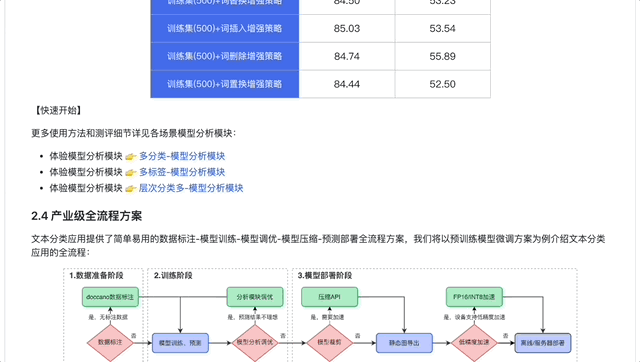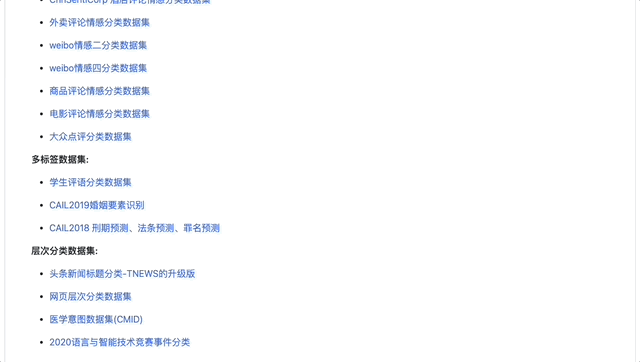
图:PaddleNLP文本分类详细文档一览

图:三类文本分类场景
方案一: 预训练模型微调
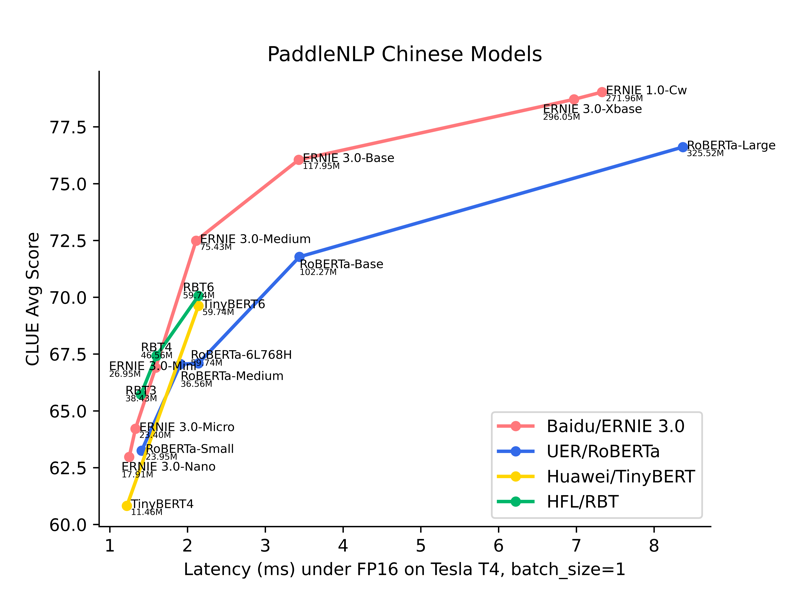
• 文心ERNIE 1.0-Large-zh-CW(24L1024H)
• 文心ERNIE 3.0-Xbase-zh(20L1024H)
• 文心ERNIE 2.0-Base-zh (12L768H)
• 文心ERNIE 3.0-Base (12L768H)
• 文心ERNIE 3.0-Medium (6L768H)
• 文心ERNIE 3.0-Mini (6L384H)
• 文心ERNIE 3.0-Micro (4L384H)
• 文心ERNIE 3.0-Nano (4L312H)
• … …
方案二: 提示学习
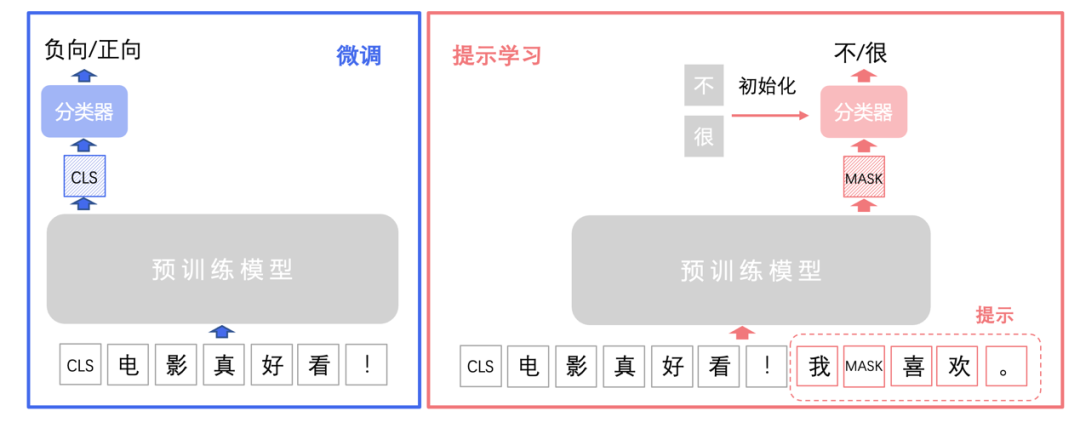
提示学习(Prompt Learning)适用于标注成本高、标注样本较少的文本分类场景。在小样本场景中,相比于预训练模型微调学习,提示学习能取得更好的效果。提示学习的主要思想是将文本分类任务转换为构造提示(Prompt)中掩码的分类预测任务,使用待预测字的预训练向量来初始化分类器参数,充分利用预训练语言模型学习到的特征和标签文本,从而降低样本量需求。PaddleNLP集成了R-Drop 和RGL等前沿策略,帮助提升模型效果。
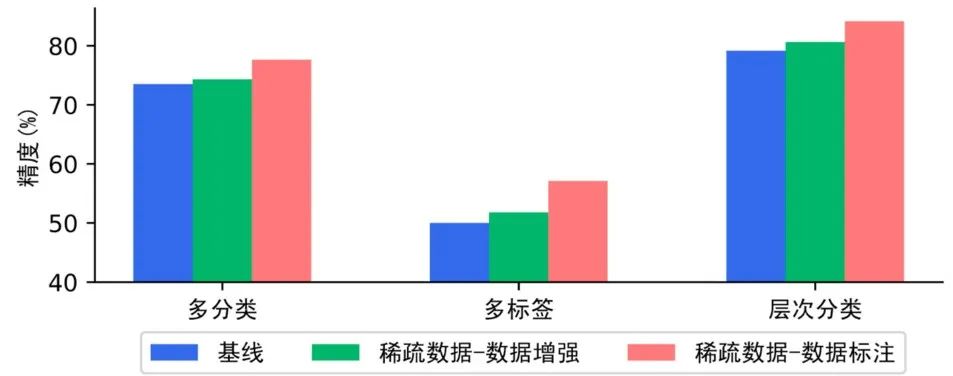
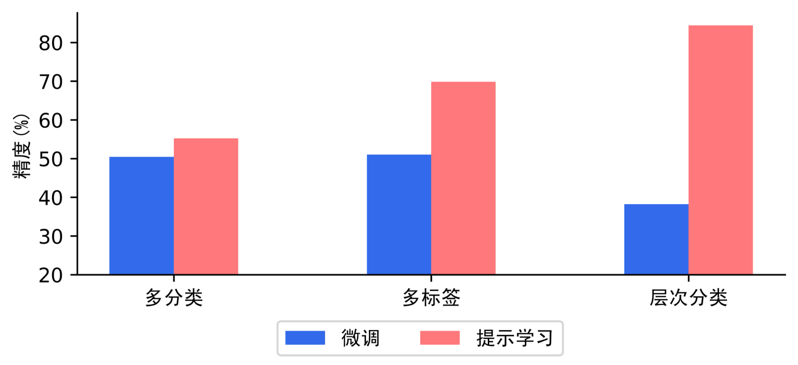
如下图,在多分类、多标签、层次分类任务的小样本场景下,提示学习比预训练模型微调方案,效果上有显著优势。
方案三: 语义索引
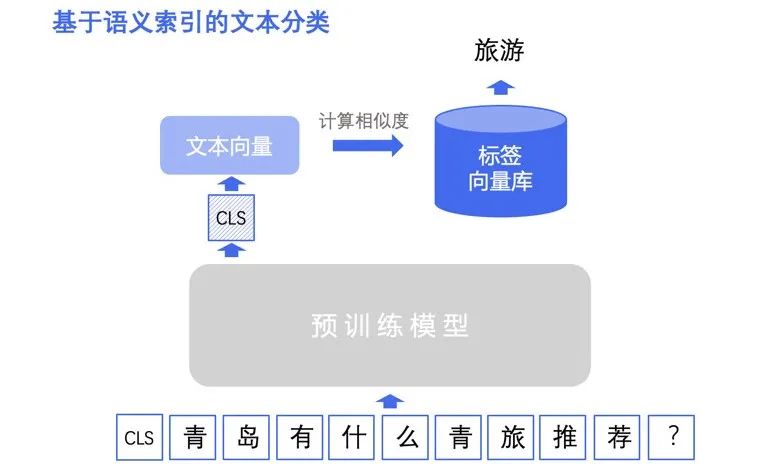
基于语义索引的文本分类方案适用于标签类别不固定或大规模标签类别的场景。在新增标签类别的情况下,无需重新训练模型。语义索引的目标是从海量候选召回集中快速、准确地召回一批与输入文本语义相关的文本。基于语义索引的文本分类方法具体来说是将标签集作为召回目标集,召回与输入文本语义相似的标签作为文本的标签类别,尤其适用于层次分类场景。
有这么一句话在业界广泛流传,"数据决定了机器学习的上限,而模型和算法只是逼近这个上限",可见数据质量的重要性。PaddleNLP文本分类方案依托TrustAI可信增强能力和数据增强API开源了模型分析模块,针对标注数据质量不高、训练数据覆盖不足、样本数量少等文本分类常见数据痛点,提供稀疏数据筛选、脏数据清洗、数据增强三种数据优化策略,解决训练数据缺陷问题,用低成本方式获得大幅度的效果提升。
策略一: 稀疏数据筛选
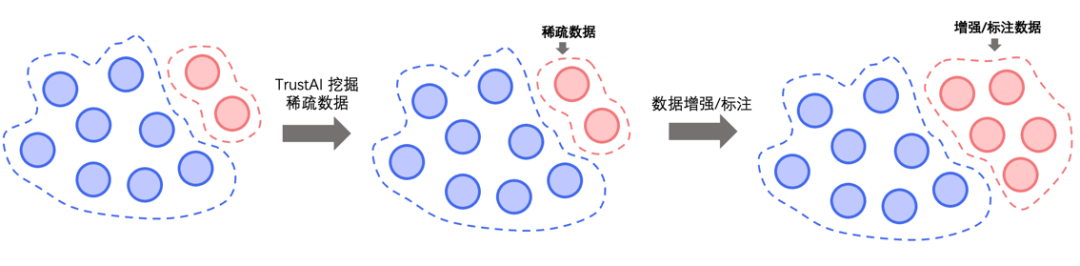
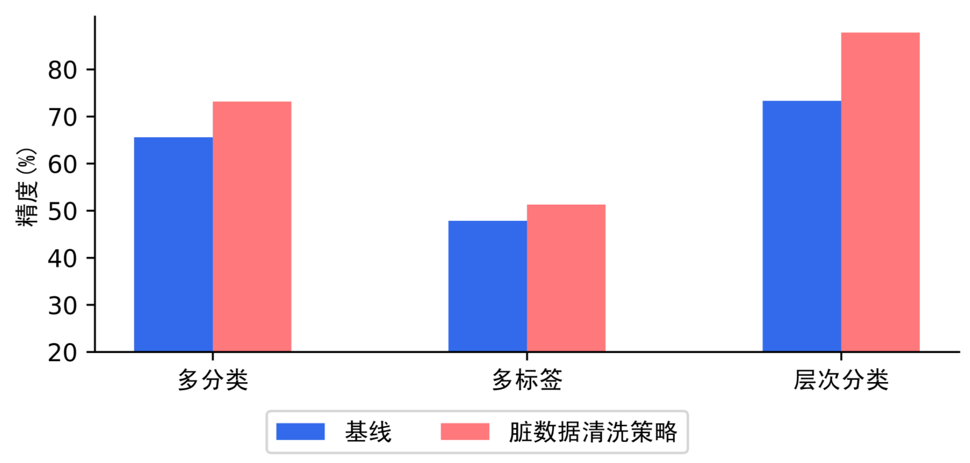
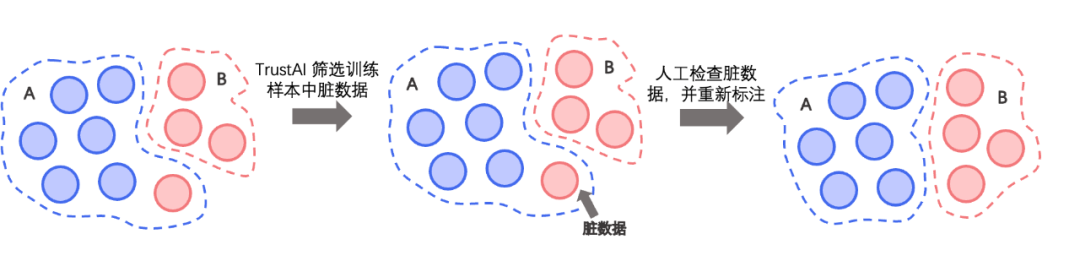
策略二: 脏数据清洗
基于TrustAI的可信增强能力,采用表示点方法(Representer Point)计算训练数据对模型的影响分数,分数高的训练数据表明对模型影响大,这些数据有较大概率为脏数据(被错误标注的样本)。脏数据清洗策略通过高效识别训练集中脏数据,有效降低人力检查成本。
策略三: 数据增强
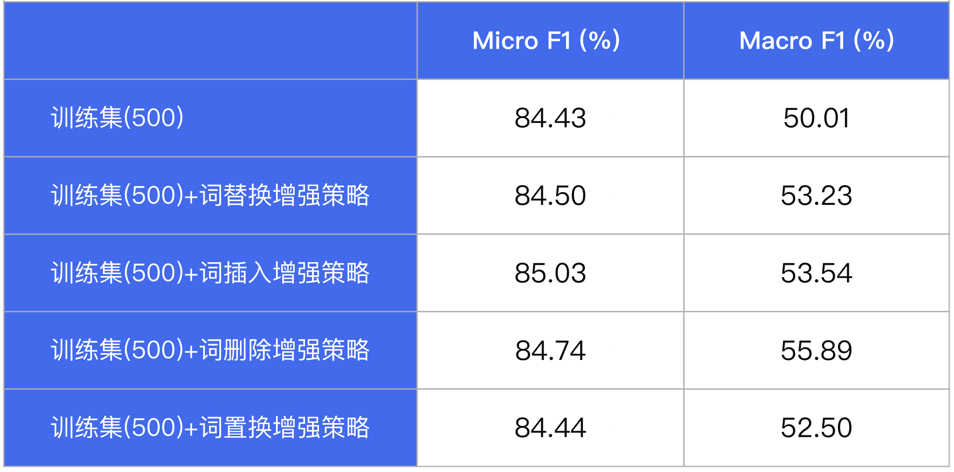
PaddleNLP内置数据增强API,支持词替换、词删除、词插入、词置换、基于上下文生成词(MLM预测)、TF-IDF等多种数据增强策略,只需一行命令即可实现数据集增强扩充。我们在某分类数据集(500条)中测评多种数据增强 策略,实验表明在数据量较少的情况下,数据增强策略能够增加数据集多样性,提升模型效果。
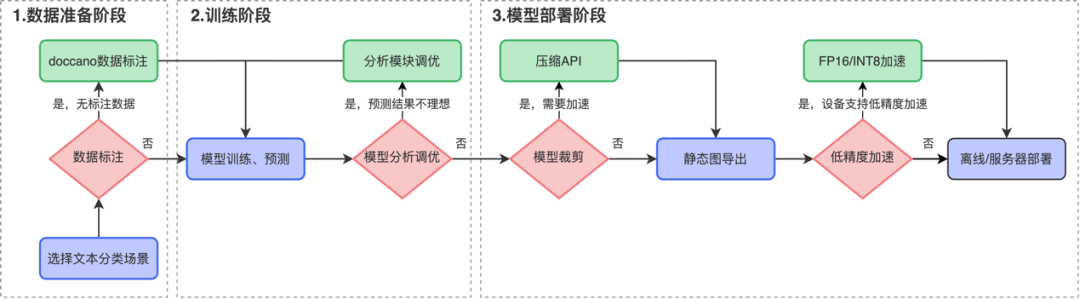

完成模型训练和裁剪后,开发者可以根据需求选择是否进行低精度(FP16/INT8)加速,快速高效实现模型离线或服务化部署。
PaddleNLP项目地址:

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~