文档智能分析产业实践,基于PP-StructureV2和OpenVINO实现训练部署开发全流程
发布日期:2023-03-23T03:44:39.000+0000 浏览量:2567次
金融和医疗等行业存在大量书面文档结构化分析和内容提取场景和任务,例如合同、票据、卡证识别、纸质文本等电子化存储、文件复原与二次编辑、信息检索等。
由于布局和格式的多样性和复杂性、低质量的扫描文档图像,自动、精准、快速的信息处理和提取对企业来说是一项具有挑战性的任务。
文档智能是指通过计算机进行自动阅读、理解以及分析商业文档的过程,是自然语言处理和计算机视觉交叉领域的一个重要研究方向。随着企业数字化转型进程不断加速,
企业利用深度学习技术可以将非结构化的文档图片快速地转化为结构化的字符和图表,并基于Word或Excel形式进行保存,大大提高关键信息提取的效率,降低人力成本。
 文档信息提取需求
小伙伴肯定好奇,如何才能快速上手这么经典的深度学习产业应用呢?针对以上企业需求,飞桨开源了
PP-StructureV2智能文档分析系统,支持版面分析、表格识别、关键信息抽取、版面复原等功能模块独立使用或灵活搭配。同时,飞桨也联合Intel建设了文档关键信息抽取与版面恢复产业实践范例,基于PP-StructureV2 Pipeline详解模型训练及调优经验以及如何基于Intel
OpenVINO快速部署,优化CPU推理任务性能,极致利用Intel x86硬件资源。
文档信息提取需求
小伙伴肯定好奇,如何才能快速上手这么经典的深度学习产业应用呢?针对以上企业需求,飞桨开源了
PP-StructureV2智能文档分析系统,支持版面分析、表格识别、关键信息抽取、版面复原等功能模块独立使用或灵活搭配。同时,飞桨也联合Intel建设了文档关键信息抽取与版面恢复产业实践范例,基于PP-StructureV2 Pipeline详解模型训练及调优经验以及如何基于Intel
OpenVINO快速部署,优化CPU推理任务性能,极致利用Intel x86硬件资源。
https://aistudio.baidu.com/aistudio/projectdetail/5666281?contributionType=1
-
书面文档中存在拍照、扫描、手写体等情况,识别难度大;
-
-
基于CPU的AI算法部署成本高,嵌入式芯片的开发复杂度高,算法集成难。
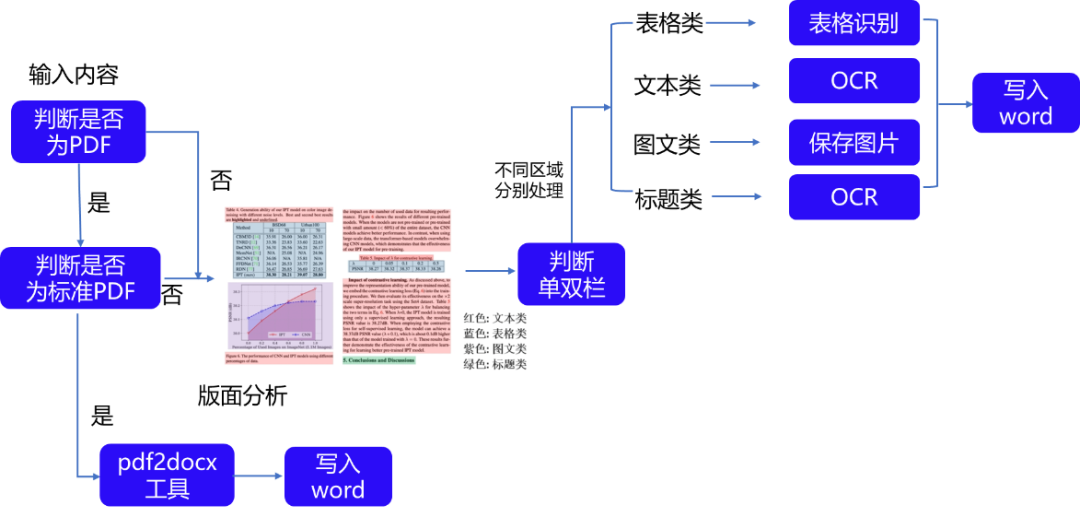
本次分享主要展示的是文档关键信息抽取和版面恢复任务。在该任务中,图像类的文档首先经过版面分析模型,被划分为文本、表格、图像等不同区域,随后对这些区域分别识别,如将表格区域送入表格识别模块进行结构化识别,将文本区域送入PaddleOCR进行文字识别,最后使用版面恢复模块将其恢复为与原始图像布局一致的Word文件。
-
版面分析任务中使用基于PP-PicoDet的轻量级版面分析模型,
。同时基于FGD知识蒸馏技术,在保证精度的情况下进一步压缩模型体积,预测速度比教师模型快1倍。
-
表格识别任务中提出了 SLANet (Structure Location Alignment Network)网络结构,其中包含CPU友好型轻量级骨干网络PP-LCNet,实现更优的“精度-速度”均衡;
轻量级高低层特征融合模块CSP-PAN,有效解决尺度变化较大等复杂场景中的模型预测问题结构,
;结构与位置信息对齐的特征解码模块SLAHead,
-
使用OpenVINO作为推理后端,倍数级提升任务在CPU侧的处理速度。
-
基于OpenVINO的performance hint策略,根据使用场景的不同需求,自动完成多线程任务配置,优化模型吞吐量或推理延迟。
本项目的最终部署环境为Intel x86平台设备。考虑开发便捷性,本次示例使用Python部署开发环境。该系统是由版面分析、文本检测、文本识别、表格结构识别等4个模型所构建的Pipeline,可以实现文档图片的快速格式化功能。在飞桨人工智能学习与实训社区AI Studio中也提供了完整的使用示例与开发说明,可参考该教程快速学习,并针对实际项目进行开发和集成。
为了让小伙伴们更便捷地应用范例教程,OpenVINO AI软件工程师Ethan将于3月23日(周四)20:15为大家深度解析从数据准备、方案设计到模型优化部署的开发全流程,手把手教大家进行代码实践。