长期以来,飞桨与NVIDIA密切合作,联合发布了基于NVIDIA GPU定制优化的飞桨容器NGC,同时在深度学习培训中心和深度学习模型示例方面开展深入合作。NVIDIA也是最早加入飞桨“硬件生态共创计划”的伙伴。该计划截至目前,已包括NVIDIA、Intel、瑞芯微、Arm、Imagination等29家生态伙伴。飞桨还联合NVIDIA在内的13家合作伙伴共同发布了飞桨生态发行版,实现软硬件协同深度优化。
飞桨助力大模型高效生产及应用
降低AI落地门槛
他讲到,不同类型的大模型需要不同的分布式策略来实现高效训练。飞桨同时支持去中心化的集合通信和中心化的参数服务器训练架构。飞桨结合应用持续创新,先后发布了4D 混合并行训练、端到端自适应分布式训练、超大规模图训练引擎等核心技术。而大模型的高效推理是实现大模型产业应用落地的关键所在。飞桨提供了灵活、高性能的部署工具链,支持模型压缩、自适应多GPU分布式推理和服务化部署。飞桨推理引擎可以同时考虑内存、带宽和算力等硬件特性,自动将模型跨设备分区,并且支持灵活配置。
业界首个同时支持
复杂算法+超大图+超大离散模型的
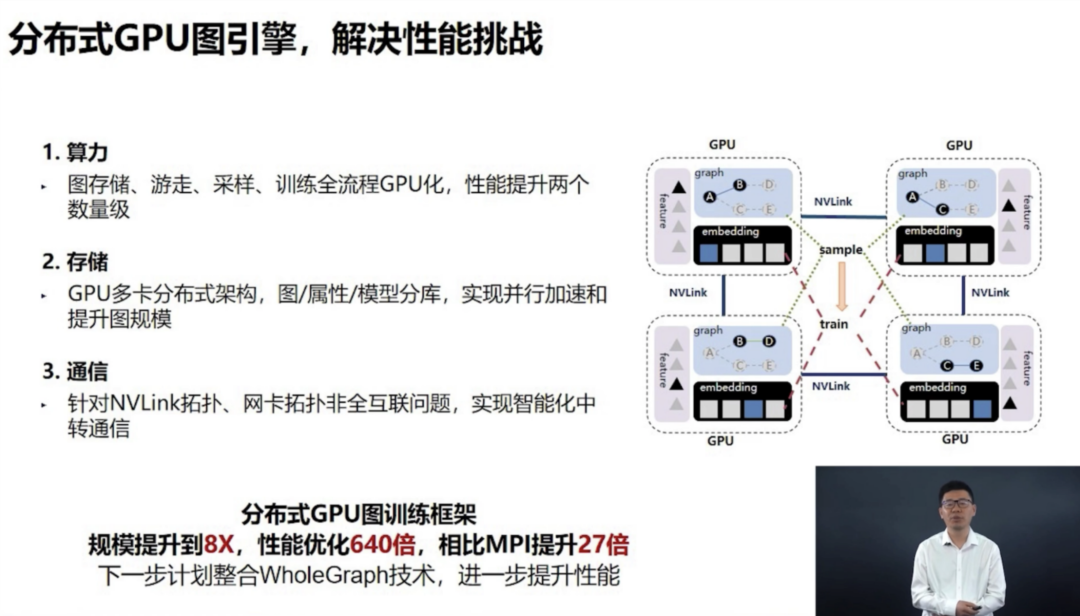
工业场景中现阶段普遍采用分布式CPU主引擎去做图模型训练,但该方案存在算力较弱、稳定性差,很难通过增加节点来提升训练效率等诸多现实局限。为解决这些挑战,百度首先构建分布式的GPU图学习训练框架解决性能问题,并创新性地采用了多级存储体系,将图规模提升一个数量级。百度还利用PGLBox提供的GPU算力和大规模存储能力,将跨模态的各种信息进行统一表达,传统的CPU则无法做类似处理。
在PGLBox的支持下,百度的R-UniMP模型赢得了NeurIPS 2022大型GNN挑战赛冠军。PGLBox为百度业务创新提供了广阔的空间,目前已经在信息推荐、搜索等标杆场景实现落地,大幅提升业务效率和用户体验。
PaddleFleetX 依托于飞桨深度学习平台,旨在提供高性能、易于使用和可扩展的组件,支持环境构建、预训练、模型微调、模型压缩,以及基于工业实践的推理部署。
PaddleFleetX的核心技术包括全场景分布式并行策略、极致的分布式训练优化技术、丰富多样的模型小型化能力和高效的大模型分布式推理与部署方案。该开发套件中的关键组件可支持大模型开发与部署的端到端工作流,其中模型并行组件涵盖了各种各样的并行策略,分布式训练组件可以高效地扩展到数千台设备,模型压缩组件可实现无损压缩,分布式推理组件能通过硬件感知来实现低延迟。
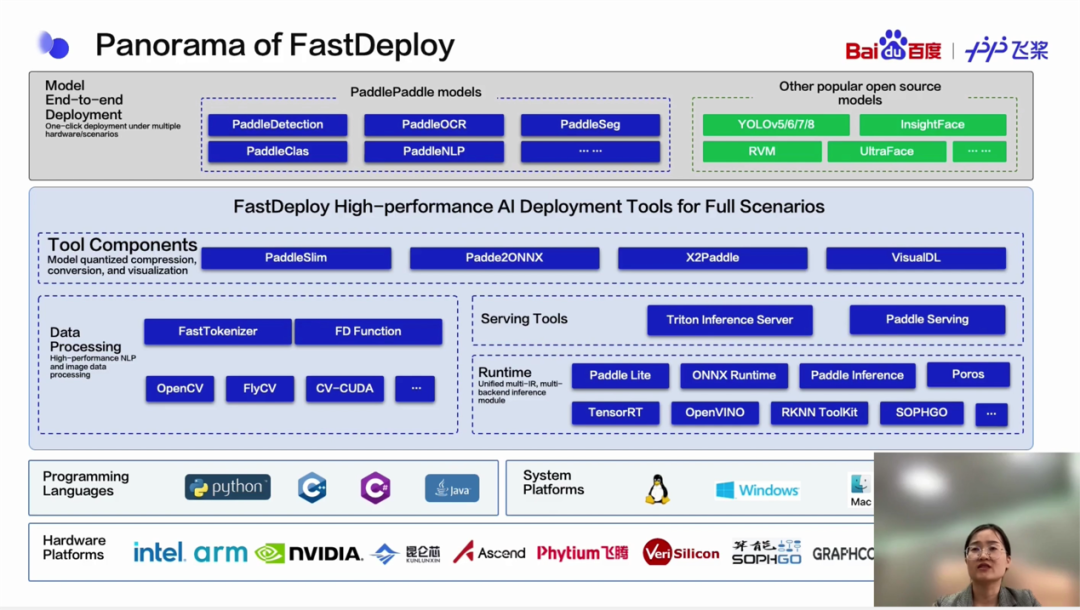
为解决开发者部署AI时面临的复杂环境问题,FastDeploy将飞桨和生态AI部署引擎API统一起来,开发者可通过一行命令灵活地切换多个推理引擎后端,并适用于云端、移动端和边缘端。
FastDeploy为不同语言设计了统一部署API,只需要三行核心代码就可以实现高性能的AI部署,并可以通过160多个先进的模型演示完成工业AI部署。会上分享了一些使用FastDeploy和NVIDIA硬件落地的案例,如在智慧油田场景实现了油气田作业智能防护系统,有效降低企业事故发生率。