个性化推荐-SSR
类别 推荐(PaddleRec)
应用 sesssion-based 序列数据推荐
模型概述
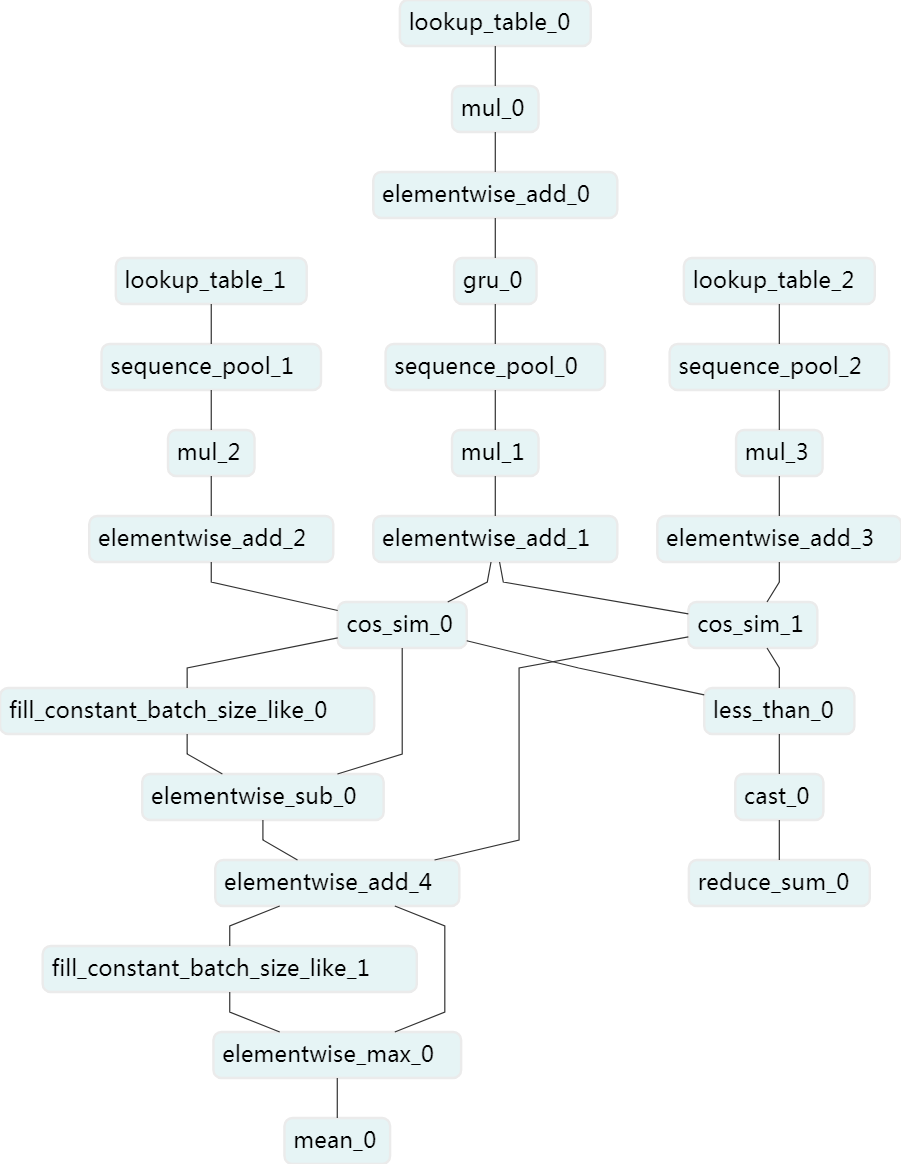
Sequence Semantic Retrieval (SSR)解决了 GRU4Rec 模型无法预测训练数据集中不存在的项目,比如新闻推荐的问题。模型与 Multi-Rate Deep Learning for Temporal Recommendation 有相似的概念。它由两个部分组成:一个是匹配模型部分,另一个是检索部分。
模型说明
# Sequence Semantic Retrieval Model
## Introduction
In news recommendation scenarios, different from traditional systems that recommend entertainment items such as movies or music, there are several new problems to solve.
- Very sparse user profile features exist that a user may login a news recommendation app anonymously and a user is likely to read a fresh news item.
- News are generated or disappeared very fast compare with movies or musics. Usually, there will be thousands of news generated in a news recommendation app. The Consumption of news is also fast since users care about newly happened things.
- User interests may change frequently in the news recommendation setting. The content of news will affect users' reading behaviors a lot even the category of the news does not belong to users' long-term interest. In news recommendation, reading behaviors are determined by both short-term interest and long-term interest of users.
[GRU4Rec](https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleRec/gru4rec) models a user's short-term and long-term interest by applying a gated-recurrent-unit on the user's reading history. The generalization ability of recurrent neural network captures users' similarity of reading sequences that alleviates the user profile sparsity problem. However, the paper of GRU4Rec operates on close domain of items that the model predicts which item a user will be interested in through classification method. In news recommendation, news items are dynamic through time that GRU4Rec model can not predict items that do not exist in training dataset.
Sequence Semantic Retrieval(SSR) Model shares the similar idea with Multi-Rate Deep Learning for Temporal Recommendation, SIGIR 2016. Sequence Semantic Retrieval Model has two components, one is the matching model part, the other one is the retrieval part.
- The idea of SSR is to model a user's personalized interest of an item through matching model structure, and the representation of a news item can be computed online even the news item does not exist in training dataset.
- With the representation of news items, we are able to build an vector indexing service online for news prediction and this is the retrieval part of SSR.
## Dataset
Dataset preprocessing follows the method of [GRU4Rec Project](https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleRec/gru4rec). Note that you should reuse scripts from GRU4Rec project for data preprocessing.
## Training
The command line options for training can be listed by `python train.py -h`
gpu 单机单卡训练
``` bash
CUDA_VISIBLE_DEVICES=0 python train.py --train_dir train_data --use_cuda 1 --batch_size 50 --model_dir model_output
```
cpu 单机训练
``` bash
python train.py --train_dir train_data --use_cuda 0 --batch_size 50 --model_dir model_output
```
gpu 单机多卡训练
``` bash
CUDA_VISIBLE_DEVICES=0,1 python train.py --train_dir train_data --use_cuda 1 --parallel 1 --batch_size 50 --model_dir model_output --num_devices 2
```
cpu 单机多卡训练
``` bash
CPU_NUM=10 python train.py --train_dir train_data --use_cuda 0 --parallel 1 --batch_size 50 --model_dir model_output --num_devices 10
```
本地模拟多机训练
``` bash
sh cluster_train.sh
```
## Inference
gpu 预测
``` bash
CUDA_VISIBLE_DEVICES=0 python infer.py --test_dir test_data --use_cuda 1 --batch_size 50 --model_dir model_output
```

{kind=link}