近年来,深度学习技术已广泛应用于NLP领域,但实际应用效果往往受限于缺乏大规模高质量监督样本。2018年底,预训练语言模型横空出世,极大缓解了这个问题,通过“超大规模无监督语料上的预训练语言模型+相对少量的监督样本进行任务精调(fine-tuning)”,可以大幅提升各类NLP任务的效果。
由于效果显著和应用机制简单,预训练语言模型以前所未有的速度在业界得到广泛应用,各大厂纷纷发布自己的预训练模型。现在,我们已毫不怀疑预训练语言模型的能力,并坚信它的发展必将持续提升各类NLP任务的效果。但是,对其能力的上限仍有疑问:预训练语言模型能带领我们彻底理解语言吗?
2020年,GPT-3[1] 发布,再一次引发大家对“通用人工智能”的热情。在一开始被GPT-3的效果惊艳之后,GPT-3的不足也暴露出来:虽然GPT-3能自动从海量的无监督语料中学习到丰富的共现知识,并成功应用于下游任务上,但GPT-3并未真正理解语言,它只是成功地记住和拟合了语料。
如上图GPT-3关于眼睛的问答例子所示,如果一个事实没有出现在语料中,预训练语言模型只能通过已经记住的语料分布去泛化,这会导致出现不可控的答案。因为,大量的事实知识是不能泛化的,即使个体是相似的,它们各自的属性值也不能随意互换。举个例子,如果一个模型的训练语料是童话故事,那么它从故事中学到的事实知识(如,太阳是个老爷爷)是无法用于现实世界的。
这自然引出了一个问题,模型没有见过的事实,通过知识去补足它,无法泛化的事实,通过知识去约束它,是否可行呢?这就是知识图谱在尝试解决的问题。
知识图谱通过将客观世界中实体、概念、及其事实性描述以结构化的方式显示表述出来,提供了一种更好地组织、管理、理解和使用知识的能力,并在搜索推荐、智能问答、大数据分析与决策等领域得到了成功应用。
不同领域的知识图谱有不同的知识表示范围和问题解决目标,例如:医疗图谱主要描述疾病、症状、药物、诊断相关知识,可用于辅助问诊、辅助诊断、治疗方案推荐等场景;商品知识图谱主要描述商品属性、特征、关联关系等,可用于导购、客服、营销等场景。
那么,除了这些具体的领域事实知识和领域应用之外,还有哪些通用知识是模型欠缺的,能帮助模型像人一样理解语言?
实际上,人对事实知识的记忆能力是远逊于模型的(模型可以轻易记住上亿的精准事实知识,而人做不到),但人的语言理解能力却远远超过任何模型。每个人的知识背景都不尽相同,但不同年龄、不同国家、不同专业的人,互相之间可以交流。一本架空小说,描述的事实和我们生活的真实世界完全不同,但读者却可以无障碍地理解。
我们自然会认为,一定存在一个通用且相对稳定的知识体系,能够让不同的人互相交流,能够让人读懂从未见过的文章,能够让一个人给另一个人讲解清楚新出现的名词。但是,这样的通用知识体系是什么样的?如何表征和构建?如何应用到NLP模型和任务中?遗憾的是,在人工智能领域,虽然从几十年前已开始研究这些问题,但目前仍无共识性的答案,依然是大家共同努力探索的方向。
百度发布“解语”开源工具集,就是尝试从中文词汇理解和句子理解的角度,对这些问题进行初步探索:构建一个通用且相对稳定的中文词汇知识体系,将文本与词汇知识体系相关联,让模型对中文句子的理解能力更接近于人。
7月21日19:00,本文作者将直播分享项目详情!加入PaddleNLP技术交流群即可观看。
为了能够区分通用知识和领域知识,我们选择这样的切入点:当一个人看到一个句子,如果事先不知道句子涉及的事实知识,怎么理解这个句子?
理解句子里都有哪些词;
理解这些词大概的意义,即便有不认识的词,也能大概猜出这个词指的是一个人、一件事、还是一种疾病;
理解这些词之间的关系,并与脑海里已有的知识关联。
基于这样的考虑,我们构建了“解语”,主要包括两部分:
https://www.paddlepaddle.org.cn/textToKnowledge
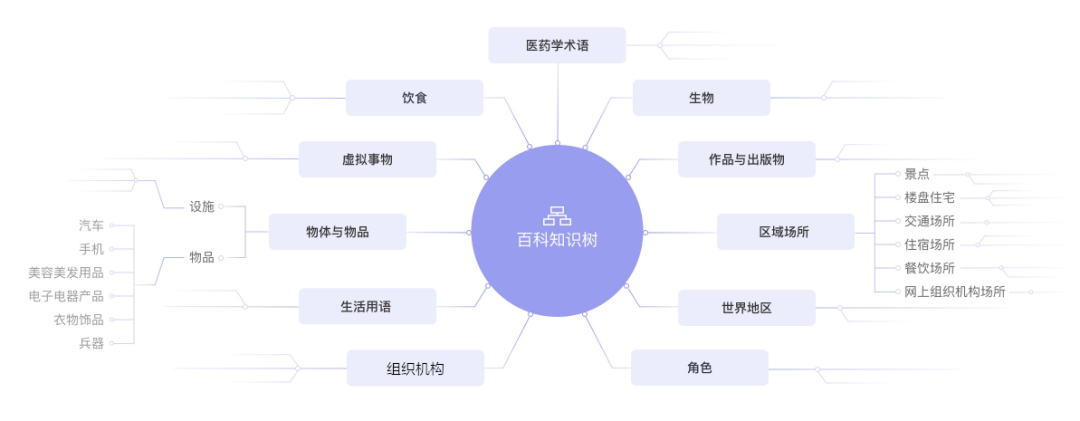
本次开源的百科知识树V1.0试用版中,包含了简化版的TermType体系,以及约100万数量的term集合。
https://kg-concept.bj.bcebos.com/TermTree/TermTree.V1.0.tar.gz
与其他常见应用知识图谱不同,百科知识树的核心是概念词,而非专名实体词。因为在中文文本中,概念词的含义是相对稳定的,而专名实体词随应用变化(例如,不同电商有不同的商品实体集,不同的小说站有不同的小说实体集),因此,百科知识树通过 “提供常用概念集 + 可插拔的应用实体集/应用知识图谱” 来达到支持不同的应用适配。
1. 采用树状结构(Tree),而不是网状结构(Net/Graph)
2. 覆盖所有中文词汇词类,经过大规模产业应用实践
WordTag是首个能够覆盖所有中文词汇的词类知识标注工具,旨在为中文文本解析提供全面、丰富的知识标注结果,可以应用于模板(挖掘模板、解析模板)生成与匹配、知识挖掘(新词发现、关系挖掘)等自然语言处理任务中,提升文本解析与挖掘精度;也可以作为中文文本特征生成器,为各类机器学习模型提供文本特征。
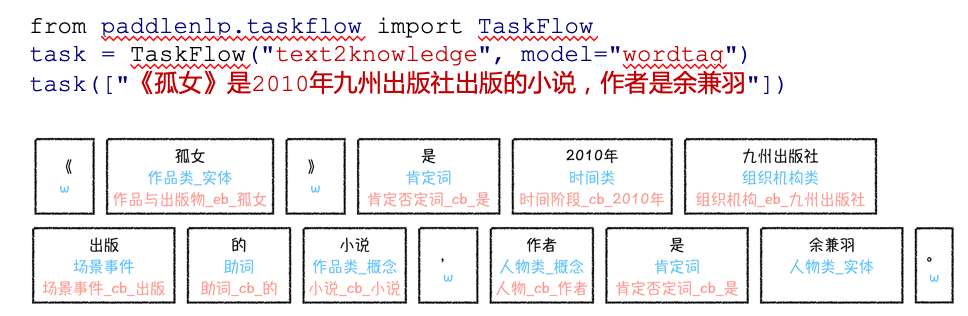
使用WordTag工具可以方便为中文句子标注上词类序列知识。如下图所示,在PaddleNLP工具包中只需要三句代码,就可以得到给定中文句子的词类序列标注结果:
Wordtag与中文分词、词性标注、命名实体识别等工具的区别如下图所示:
由于中文是孤立语,没有词的形态变化,句法结构弱,主要依赖“词+词序”表达语义。通过WordTag词类知识标注产出完整的Term边界以及上位词类序列,能够为文本提供更加丰富的词汇知识特征,比一般分词粒度稳定,比词性特征区分度高,比命名实体识别覆盖面广,无论是直接用于挖掘,还是作为知识特征加入到DNN模型中,都是更全面的知识补充。
WordTag的理想目标是在词类序列标注这一维度上逼近人对句子的理解能力,也就是说,当句子中出现未知词汇时,能够通过句子中其他的词及词类知识划分它的边界并分辨出它大概率是什么词类。当前WordTag的效果距离这个目标还有相当大的距离,但通过不断基于百科知识树扩充和优化训练样本,WordTag会持续优化,逐步逼近这个目标。
不同场景下的文本解析可能有各自的特殊需求,结合百科知识树,WordTag可实现定制化词类序列标注。
有别于其他的分词工具,WordTag的切分目标是尽可能将Term的完整边界切分出来,使之更加适用于下游的挖掘任务,在实际应用中,也可以结合其他基础粒度的中文分词结果共同使用。
同时,WordTag的标注词类覆盖了中文所有词汇,其结果可以直接作为命名实体识别的候选结果使用,也可以结合百科知识树进行更细粒度的词类筛选,或直接用于专名挖掘。
例如上文的例子:
WordTag结果:李伟\人物类_实体 拿出\场景事件 具有\肯定词 科学性\信息资料 、\w 可操作性\信息资料 的\助词 《\w 陕西省高校管理体制改革实施方案\作品类_实体 》\w
可直接作为分词结果,也可通过作品类_实体标签、人物类_实体标签得到实体候选,还可以结合百科知识树进行其他词类的挖掘和过滤。
在知识挖掘、query解析、语义一致性判定等应用中,文本挖掘/解析模板是最常用的规则模型。WordTag包含了覆盖中文所有词汇的词类标注体系,在生成模板以及模板匹配上有着天然的优势。用户可以根据WordTag标注的样本词类序列,自动生成或配置更加丰富、精准的挖掘/解析模板,然后对目标文本使用WordTag标注,即可利用模板进行匹配,从而大大降低人工配置模板的代价,显著提升生产效率。
例如,输入文本:美人鱼是周星驰执导的电影,可将抽取出的词类直接构造成为挖掘匹配模板:
[作品类_实体][肯定词|是][人物类_实体][场景事件|执导][作品类_概念|电影]
利用该模板,以及结合百科知识树进行概念扩展,可以匹配出所有该句式的文本,例如:
《狂人日记》是鲁迅创作的第一个短篇白话日记体小说
《千王之王2000》是一部王晶于1999年执导的喜剧电影
WordTag的标注结果中,区分了“人物类_实体”和“人物类_概念”,以及“作品类_实体”和“作品类_概念”,使得模板生成更为精准。同时,百科知识树中也区分了命名实体词(eb: entity base)与非实体词(cb: concept base),这样,可以利用百科知识树分别进行实体扩展(e.g., 周星驰->王晶)和概念扩展(e.g., 电影->小说),生成更加丰富多样的模板,支持更细化的应用场景。
此外,模板也可用于文本分类和文本挖掘的样本优化:使用WordTag产出样本模板,再利用百科知识树进行泛化约束,筛选出高置信度的样本,或者过滤不合格的样本。
很多研究在尝试将知识引入模型,以获得更好的应用效果。例如,[2]提出在关系抽取模型中增加实体类型的信息,以达到更优的知识抽取效果。
开发者们可以利用WordTag生成词类特征,与知识增强的挖掘模型结合,应用于自己的中文挖掘任务;研究者们也可以利用WordTag与百科知识树提供的丰富的词类特征,探索更好的知识增强的中文挖掘模型。
除下游任务外,也可以将词类知识应用于预训练中,例如使用词类知识控制预训练语言模型的掩码过程,让预训练语言模型具备更强的通用知识。
让NLP模型对语言的理解能力逼近人类,是所有NLPer的努力目标。一方面,我们希望模型能自动学得语料中隐含的知识,另一方面,我们也希望将人类积累的通用知识通过更高效的方式融入到模型中,弥补语料的分布缺陷。
“解语”是从中文词汇理解和句子理解的角度尝试构建词汇层次上的通用知识,并将其应用到中文文本知识标注中。目前的知识体系及标注效果还在持续优化中,此次作为开源数据和工具发布,也希望能和大家共同探索通用知识的表征与应用方案,打造更具有知识理解能力的NLP模型。
看完文章是不是有很多疑问想与作者交流?
请锁定飞桨B站直播间!
7月21日19:00
本文作者将直播分享项目详情!
扫描下方二维码进入PaddleNLP技术交流群,技术专家在线答疑解惑,直播链接也将同步到交流群中。
https://www.paddlepaddle.org.cn/textToKnowledge
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples/text_to_knowledge
访问PaddleNLP了解更多应用,Star 收藏跟进最新功能吧:
https://github.com/PaddlePaddle/PaddleNLP
[1] Brown T B, Mann B, Ryder N, et al. Language models are few-shot learners[J]. arXiv preprint arXiv:2005.14165, 2020.
[2] Zhong Z, Chen D. A Frustratingly Easy Approach for Entity and Relation Extraction[J]. arXiv preprint arXiv:2010.12812, 2020.
http://discuss.paddlepaddle.org.cn/
欢迎加入官方QQ群获取最新活动资讯:793866180。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
https://www.paddlepaddle.org.cn/
GitHub: https://github.com/PaddlePaddle/Paddle
Gitee: https://gitee.com/paddlepaddle/Paddle
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体,是中国首个自主研发、功能丰富、开源开放的产业级深度学习平台。飞桨企业版针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。