
项目介绍
DMR论文简介
研究背景
现有问题
论文贡献
指出了 CTR 领域捕获 U2I 相关性的重要性,并以此提出了 DMR 模型;
设计了一个辅助召回网络去辅助 U2I 网络的训练,DMR 模型是一个将召回和排序联合起来训练的模型;
引入注意力机制和位置编码来学习行为的权重;
在公开数据集和工业数据集都取得了不错的成绩,并开放了源码。
模型结构
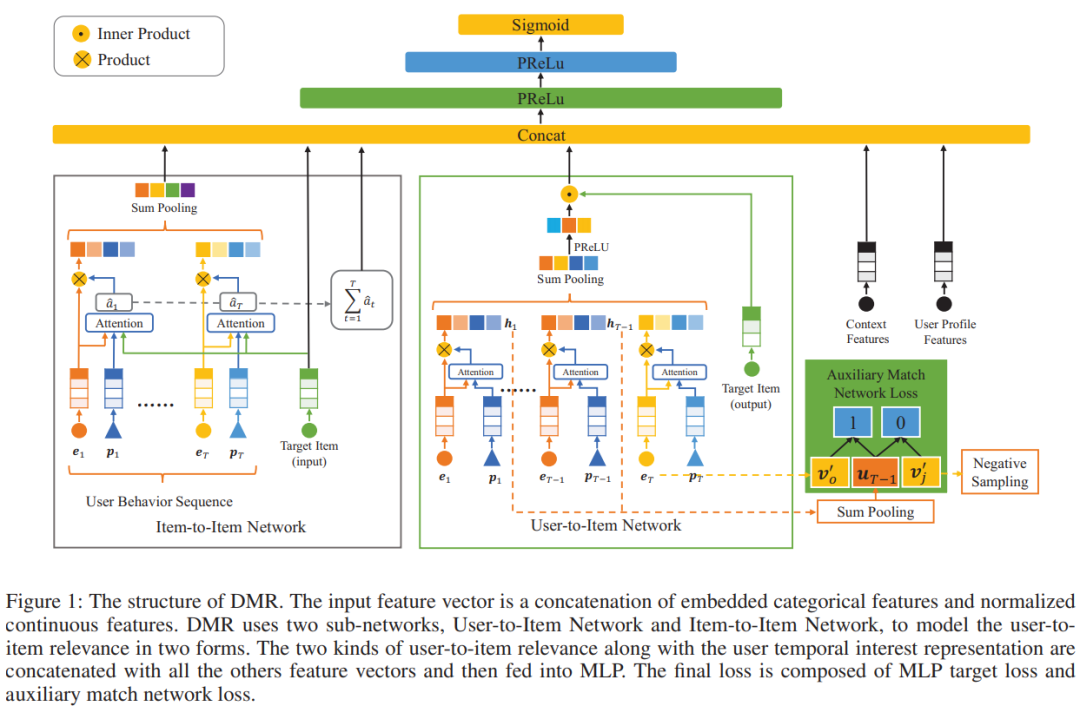
User-to-Item 网络
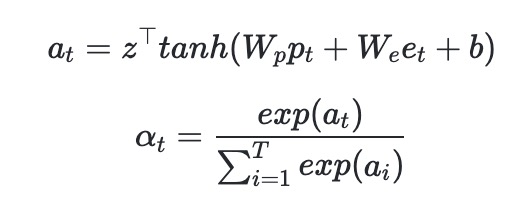
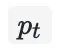 为第
为第
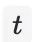 个 position embedding;
个 position embedding;
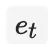 为第
个行为的特征向量;
为第
个行为的特征向量;
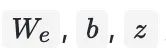 为需要学习的参数,
为需要学习的参数,
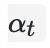 为归一化的第
个行为的权重。
为归一化的第
个行为的权重。
通过加权求和的池化操作和一个全连接层得到最终的用户表征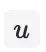
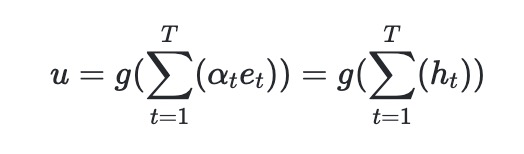
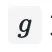 为一个非线性变化,对应网络中的 PReLU;
为一个非线性变化,对应网络中的 PReLU;
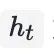 为第
为第
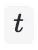 个行为加权后的特征向量。
个行为加权后的特征向量。
可以加更多对的隐层以获得更好的表征;
除了位置编码,我们还可以添加更多的上下文特征如行为类别、持续时间等;
用户行为采用倒序,以使得最近行为在第一个位置。
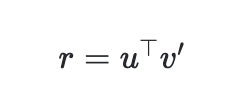
 为目标 Item 的输出矩阵中对应的向量。
为目标 Item 的输出矩阵中对应的向量。
 越大,两者的相关性越强,从而对 CTR 预测有正向效果。但从反向传播的角度来看,仅仅通过点击标签很难学出这样的效果。为此,作者加入了辅助召回网络(Auxiliary Match Network)引入用户行为作为 label 来帮助原来的网络进行学习。
越大,两者的相关性越强,从而对 CTR 预测有正向效果。但从反向传播的角度来看,仅仅通过点击标签很难学出这样的效果。为此,作者加入了辅助召回网络(Auxiliary Match Network)引入用户行为作为 label 来帮助原来的网络进行学习。
 个行为来预测第
个行为来预测第
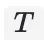 个行为,属于多分类问题,有多少候选商品就有多少个分类结果。我们很容易拿到用户前
次行为后的向量表示 ,那么用户第
次交互的物品为
个行为,属于多分类问题,有多少候选商品就有多少个分类结果。我们很容易拿到用户前
次行为后的向量表示 ,那么用户第
次交互的物品为
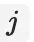 的概率为:
的概率为:
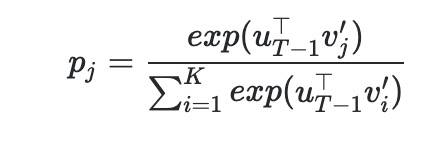
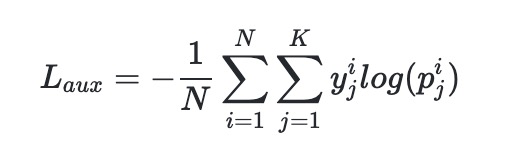
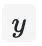 为 label,
为 label,
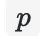 为预测概率,
为预测概率,
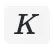 为类别数。
为类别数。
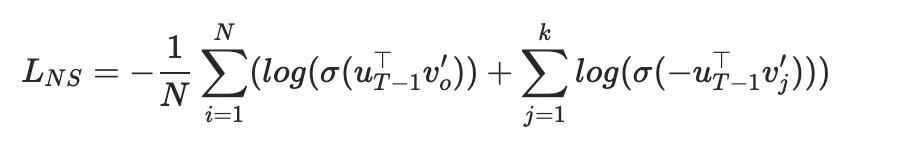
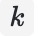 为负样本数量,且数量远小于总数
。
为负样本数量,且数量远小于总数
。
Item-to-Item 网络
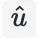 :
:
基于飞桨的代码
数据预处理
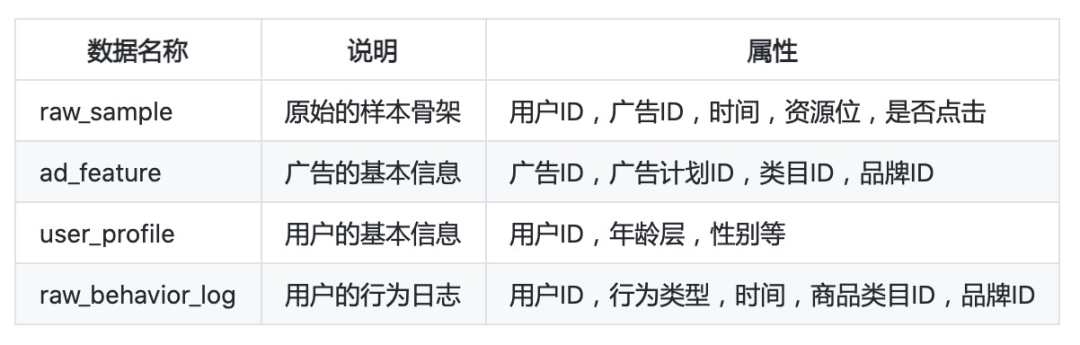
==> raw_sample.csv <== nonclk,clk对应alimama_sampled.txt最后一列(266),点击与否。用前面7天的做训练样本(20170506-20170512),用第8天的做测试样本(20170513),time_stamp 1494032110 stands for 2017-05-06 08:55:10。pid要编码为类别数字。
user,time_stamp,adgroup_id,pid,nonclk,clk
581738,1494137644,1,430548_1007,1,0
==> behavior_log.csv <== 对应alimama_sampled.txt中[0:150]列(列号从0开始),需要根据raw_sample.csv每行记录查找对应的50条历史数据,btag要编码为类别数字
user,time_stamp,btag,cate,brand
558157,1493741625,pv,6250,91286
==> user_profile.csv <== 对应alimama_sampled.txt中[250:259]列(列号从0开始)
userid,cms_segid,cms_group_id,final_gender_code,age_level,pvalue_level,shopping_level,occupation,new_user_class_level
234,0,5,2,5,,3,0,3
==> ad_feature.csv <== 对应alimama_sampled.txt中[259:264]列(列号从0开始),price需要标准化到0~1
adgroup_id,cate_id,campaign_id,customer,brand,price
63133,6406,83237,1,95471,170.0
class RecDataset(IterableDataset):
def __init__(self, file_list, config):
super(RecDataset, self).__init__()
self.file_list = file_list
def __iter__(self):
# 遍历所有的输入文件,文件中的每一行表示一条训练数据
for file in self.file_list:
with open(file, "r") as rf:
for line in rf:
line = line.strip().split(",")
line = ['0' if i == '' or i.upper() == 'NULL' else i for i in line] # handle missing values
# 需要转为numpy arrary方便后续转为Tensor
output_list = np.array(line, dtype='float32')
yield output_list核心组网
组网代码的复现过程基本就是翻译TF源码(https://github.com/lvze92/DMR),不清楚的API就查文档。需要注意的是deep_match函数中softmax,tf源码是采样的,本项目最终的paddle代码没有采样,这点的影响应该是paddle会更准确,当然计算会慢些(不过实测发现在这个例子中这部分速度并不慢,完全可以接受)。
class DMRLayer(nn.Layer):
# 模型的超参数比较多,大部分是与数据集本身相关的,比如user_size是用户数,age_level_size是用户年龄分组数;lr, main_embedding_size, other_embedding_size是模型本身的超参数。详细的参数信息可以查看config.yaml文件,模型(而非数据集)相关的超参数信息在下文会详细介绍。
def __init__(self, user_size, lr, global_step,
cms_segid_size, cms_group_id_size, final_gender_code_size,
age_level_size, pvalue_level_size, shopping_level_size,
occupation_size, new_user_class_level_size, adgroup_id_size,
cate_size, campaign_id_size, customer_size,
brand_size, btag_size, pid_size,
main_embedding_size, other_embedding_size):
super(DMRLayer, self).__init__()
# 下面是参数的初始化,这里只贴出一部分
self.user_size = user_size
……
self.main_embedding_size = main_embedding_size
self.other_embedding_size = other_embedding_size
self.history_length = 50
# 下面是定义模型需要用到的各个embedding,必须在init里定义,才会被训练,这里只贴出几个示例
self.uid_embeddings_var = paddle.nn.Embedding(
self.user_size,
self.main_embedding_size,
sparse=True,
weight_attr=paddle.ParamAttr(
name="UidSparseFeatFactors",
initializer=paddle.nn.initializer.Uniform()))
……
# 下面是定义User-to-Item网络的Attention layers
self.query_layer = paddle.nn.Linear(self.other_embedding_size*2, self.main_embedding_size*2, name='dm_align')
self.query_prelu = paddle.nn.PReLU(num_parameters=self.history_length, init=0.1, name='dm_prelu')
self.att_layer1_layer = paddle.nn.Linear(self.main_embedding_size*8, 80, name='dm_att_1')
self.att_layer2_layer = paddle.nn.Linear(80, 40, name='dm_att_2')
self.att_layer3_layer = paddle.nn.Linear(40, 1, name='dm_att_3')
self.dnn_layer1_layer = paddle.nn.Linear(self.main_embedding_size*2, self.main_embedding_size, name='dm_fcn_1')
self.dnn_layer1_prelu = paddle.nn.PReLU(num_parameters=self.history_length, init=0.1, name='dm_fcn_1')
# 下面是定义Item-to-Item网络的 Attention layers
self.query_layer2 = paddle.nn.Linear((self.other_embedding_size + self.main_embedding_size)*2, self.main_embedding_size*2, name='dmr_align')
self.query_prelu2 = paddle.nn.PReLU(num_parameters=self.history_length, init=0.1, name='dmr_prelu')
self.att_layer1_layer2 = paddle.nn.Linear(self.main_embedding_size*8, 80, name='tg_att_1')
self.att_layer2_layer2 = paddle.nn.Linear(80, 40, name='tg_att_2')
self.att_layer3_layer2 = paddle.nn.Linear(40, 1, name='tg_att_3')
self.logits_layer = paddle.nn.Linear(self.main_embedding_size, self.cate_size)
# 下面定义User-to-Item网络模块
def deep_match(item_his_eb, context_his_eb, mask, match_mask, mid_his_batch, EMBEDDING_DIM, item_vectors, item_biases, n_mid):
query = context_his_eb
query = self.query_layer(query) # [1, 50, 64]
query = self.query_prelu(query)
inputs = paddle.concat([query, item_his_eb, query-item_his_eb, query*item_his_eb], axis=-1) # B,T,E
att_layer1 = self.att_layer1_layer(inputs)
att_layer1 = F.sigmoid(att_layer1)
att_layer2 = self.att_layer2_layer(att_layer1)
att_layer2 = F.sigmoid(att_layer2)
att_layer3 = self.att_layer3_layer(att_layer2) # B,T,1
scores = paddle.transpose(att_layer3, [0, 2, 1]) # B,1,T
# mask
bool_mask = paddle.equal(mask, paddle.ones_like(mask)) # B,T
key_masks = paddle.unsqueeze(bool_mask, axis=1) # B,1,T
paddings = paddle.ones_like(scores) * (-2 ** 32 + 1)
scores = paddle.where(key_masks, scores, paddings)
# tril
scores_tile = paddle.tile(paddle.sum(scores, 1), [1, paddle.shape(scores)[-1]]) # B, T*T
scores_tile = paddle.reshape(scores_tile, [-1, paddle.shape(scores)[-1], paddle.shape(scores)[-1]]) # B, T, T
diag_vals = paddle.ones_like(scores_tile) # B, T, T
tril = paddle.tril(diag_vals)
paddings = paddle.ones_like(tril) * (-2 ** 32 + 1)
scores_tile = paddle.where(paddle.equal(tril, paddle.to_tensor(0.0)), paddings, scores_tile) # B, T, T
scores_tile = F.softmax(scores_tile) # B, T, T
att_dm_item_his_eb = paddle.matmul(scores_tile, item_his_eb) # B, T, E
dnn_layer1 = self.dnn_layer1_layer(att_dm_item_his_eb)
dnn_layer1 = self.dnn_layer1_prelu(dnn_layer1)
# target mask
user_vector = dnn_layer1[:, -1, :] # B, E
user_vector2 = dnn_layer1[:, -2, :] * paddle.reshape(match_mask, [-1, paddle.shape(match_mask)[1], 1])[:, -2, :] # B, E
num_sampled = 2000
labels = paddle.reshape(mid_his_batch[:, -1], [-1, 1]) # B, 1
# not sample
# [B, E] * [E_size, cate_size]
logits = paddle.matmul(user_vector2, item_vectors, transpose_y=True)
logits = paddle.add(logits, item_biases)
loss = F.cross_entropy(input=logits, label=labels)
return loss, user_vector, scores
# 下面定义Item-to-Item网络模块
def dmr_fcn_attention(item_eb, item_his_eb, context_his_eb, mask, mode='SUM'):
mask = paddle.equal(mask, paddle.ones_like(mask))
item_eb_tile = paddle.tile(item_eb, [1, paddle.shape(mask)[1]]) # B, T*E
item_eb_tile = paddle.reshape(item_eb_tile, [-1, paddle.shape(mask)[1], item_eb.shape[-1]]) # B, T, E
if context_his_eb is None:
query = item_eb_tile
else:
query = paddle.concat([item_eb_tile, context_his_eb], axis=-1)
query = self.query_layer2(query)
query = self.query_prelu2(query)
dmr_all = paddle.concat([query, item_his_eb, query-item_his_eb, query*item_his_eb], axis=-1)
att_layer_1 = self.att_layer1_layer2(dmr_all)
att_layer_1 = F.sigmoid(att_layer_1)
att_layer_2 = self.att_layer2_layer2(att_layer_1)
att_layer_2 = F.sigmoid(att_layer_2)
att_layer_3 = self.att_layer3_layer2(att_layer_2) # B, T, 1
att_layer_3 = paddle.reshape(att_layer_3, [-1, 1, paddle.shape(item_his_eb)[1]]) # B,1,T
scores = att_layer_3
# Mask
key_masks = paddle.unsqueeze(mask, 1) # B,1,T
paddings = paddle.ones_like(scores) * (-2 ** 32 + 1)
paddings_no_softmax = paddle.zeros_like(scores)
scores = paddle.where(key_masks, scores, paddings) # [B, 1, T]
scores_no_softmax = paddle.where(key_masks, scores, paddings_no_softmax)
scores = F.softmax(scores)
if mode == 'SUM':
output = paddle.matmul(scores, item_his_eb) # [B, 1, H]
output = paddle.sum(output, 1) # B,E
else:
scores = paddle.reshape(scores, [-1, paddle.shape(item_his_eb)[1]])
output = item_his_eb * paddle.unsqueeze(scores, -1)
output = paddle.reshape(output, paddle.shape(item_his_eb))
return output, scores, scores_no_softmax
self._deep_match = deep_match
self._dmr_fcn_attention = dmr_fcn_attention
……
# 计算输入MLP的concat向量的维度,tf源码中这部分是在forward里自动计算的,但是Paddle必须在init里提前计算好代数表达式,这里还是稍微有点麻烦,需要细心计算
self.inp_length = self.main_embedding_size + self.other_embedding_size*8 + self.main_embedding_size*5 + 1 + \
self.other_embedding_size + self.main_embedding_size*2 + self.main_embedding_size*2 + 1 + 1 \
+ self.main_embedding_size*2
# 下面是定义MLP,这里展示部分代码
self.inp_layer = paddle.nn.BatchNorm(self.inp_length, momentum=0.99, epsilon=1e-03)
self.dnn0_layer = paddle.nn.Linear(self.inp_length, 512, name='f0')
self.dnn0_prelu = paddle.nn.PReLU(num_parameters=512, init=0.1, name='prelu0')
……
# 下面定义前向计算,将init里定义的各个模块、layer串起来
def forward(self, inputs_tensor, with_label=0):
# 输入数据的预处理,展示部分代码
inputs = inputs_tensor[0] # sparse_tensor
dense_tensor = inputs_tensor[1]
self.btag_his = inputs[:, 0:self.history_length]
……
self.price = dense_tensor.astype('float32')
self.pid = inputs[:, self.history_length*5+15]
if with_label == 1:
self.labels = inputs[:, self.history_length*5+16]
# embedding layer的查询,这里只列出部分
self.uid_batch_embedded = self.uid_embeddings_var(self.uid)
……
self.pid_batch_embedded = self.pid_embeddings_var(self.pid)
# 下面是User特征的拼接
self.user_feat = paddle.concat([self.uid_batch_embedded, self.cms_segid_batch_embedded, self.cms_group_id_batch_embedded, self.final_gender_code_batch_embedded, self.age_level_batch_embedded, self.pvalue_level_batch_embedded, self.shopping_level_batch_embedded, self.occupation_batch_embedded, self.new_user_class_level_batch_embedded], -1)
……
# Item特征的拼接
self.item_feat = paddle.concat([self.mid_batch_embedded, self.cat_batch_embedded, self.brand_batch_embedded, self.campaign_id_batch_embedded, self.customer_batch_embedded, self.price], -1)
……
# Position特征的拼接
self.position_his_eb = paddle.concat([self.position_his_eb, self.btag_his_batch_embedded], -1)
self.dm_position_his_eb = paddle.concat([self.dm_position_his_eb, self.dm_btag_his_batch_embedded], -1)
# User-to-Item Network
# Auxiliary Match Network
self.aux_loss, self.dm_user_vector, scores = self._deep_match(self.item_his_eb, self.dm_position_his_eb, self.mask, paddle.cast(self.match_mask, 'float32'), self.cate_his, self.main_embedding_size, self.dm_item_vectors_var.weight, self.dm_item_biases, self.cate_size)
self.aux_loss *= 0.1
self.dm_item_vec = self.dm_item_vectors_var(self.cate_id)
rel_u2i = paddle.sum(self.dm_user_vector * self.dm_item_vec, -1, keepdim=True) # B,1
self.rel_u2i = rel_u2i
# Item-to-Item Network
att_outputs, alphas, scores_unnorm = self._dmr_fcn_attention(self.item_eb, self.item_his_eb, self.position_his_eb, self.mask)
rel_i2i = paddle.unsqueeze(paddle.sum(scores_unnorm, [1, 2]), -1)
self.rel_i2i = rel_i2i
self.scores = paddle.sum(alphas, 1)
# Concat向量的拼接
inp = paddle.concat([self.user_feat, self.item_feat, self.context_feat, self.item_his_eb_sum, self.item_eb * self.item_his_eb_sum, rel_u2i, rel_i2i, att_outputs], -1)
# MLP网络全连接层,部分代码
inp = self.inp_layer(inp)
dnn0 = self.dnn0_layer(inp)
……
# prediction
self.y_hat = F.sigmoid(dnn3)
# 计算loss
if with_label == 1:
# Cross-entropy loss and optimizer initialization
x = paddle.sum(dnn3, 1)
BCE = paddle.nn.BCEWithLogitsLoss()
ctr_loss = paddle.mean(BCE(x, label=self.labels.astype('float32')))
self.ctr_loss = ctr_loss
self.loss = self.ctr_loss + self.aux_loss
return self.y_hat, self.loss
else:
return self.y_hat
训练和评估
PaddleRec原来的trainer.py只能处理一组超参数,对于超参数优化并不方便,因此对其进行一定的修改,使之可以遍历搜索超参数。
if __name__ == '__main__':
import os
import shutil
def f(best_auc, best_lr, current_lr, args):
auc, current_lr, train_batch_size, model_save_path = main(args, current_lr)
print(f'Trying Current_lr: {current_lr}, AUC: {auc}')
if auc > best_auc:
best_auc = auc
best_lr = current_lr
shutil.rmtree(f'{model_save_path}/1000', ignore_errors=True)
shutil.copytree(f'{model_save_path}/0', f'{model_save_path}/1000')
os.rename(src=f'{model_save_path}/0',
dst=f'{model_save_path}/b{train_batch_size}l{str(lr)[2:]}auc{str(auc)[2:]}')
print(f'rename 0 to b{train_batch_size}l{str(lr)[2:]}auc{str(auc)[2:]}')
return best_auc, best_lr
def reset_graph():
paddle.enable_static()
paddle.disable_static()
args = parse_args()
best_auc = 0.0
best_lr = -1
# # if you want to try different learning_rate in one running, set try_lrs as below:
# try_lrs = [0.006, 0.007, 0.008, 0.009, 0.01] * 2
# # else if you want use learning_rate as set in config file, set try_lrs as below:
try_lrs = [None]
for lr in try_lrs:
best_auc, best_lr = f(best_auc, best_lr, lr, args)
reset_graph()
if best_auc >= 0.6447: # 0.6447 is the metric in the original paper
break
print(f'Best AUC: {best_auc}, Best learning_rate: {best_lr}')
python -u ../../../tools/trainer.py -m config.yaml
python -u ../../../tools/infer.py -m config.yaml
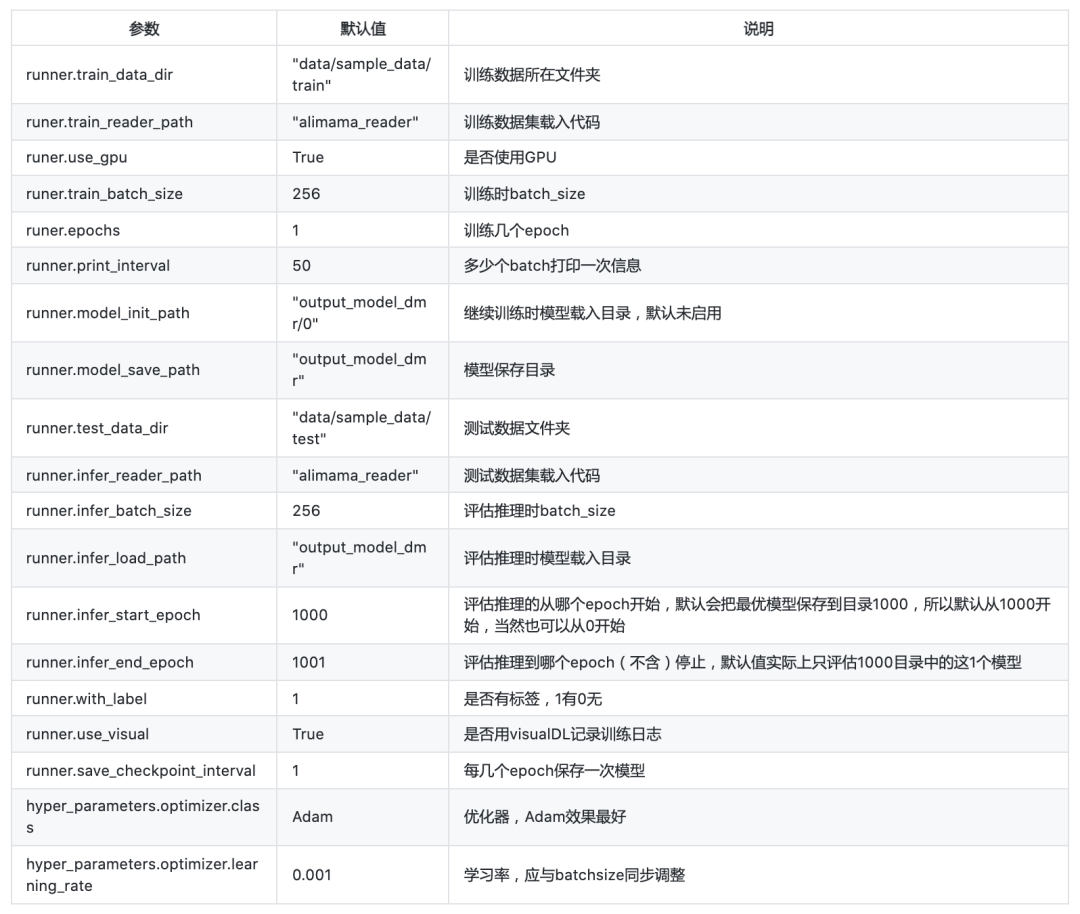
其中config.yaml为配置文件,其中各参数含义如下:
复现效果

踩坑经历
飞桨用法
过拟合问题
数据预处理问题
总结与思考

飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体,是中国首个自主研发、功能丰富、开源开放的产业级深度学习平台。飞桨企业版针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END

