在当前大数据时代的背景下,我们每天面临着各种形式的数据,其中有结构化的,也有非结构化的。特别是对图片形式这种非结构化的数据,如何高效地获取、处理以及分析仍旧是一系列颇有挑战的任务。我们常常会拿到一份表格的数据材料, 或许是一页传单,或许是书页上的数据整理,或许是一页实验报告,又或许是某产品规格参数等等,然后基于传统的操作方式, 将数据逐项录入到系统,存储到数据库,通过SQL命令跟数据库交互,并二次处理后返回给用户。整个过程比较繁琐,更重要的是,要求用户具备数据库和其他IT技能。本项目探索了一种新的思路,即直接解析表格图片的数据并用人类自然语言直接查询所需数据, 让普通用户更好的满足该场景下的数据需求。
项目地址:https://aistudio.baidu.com/aistudio/projectdetail/2262444
表格图片数据解析
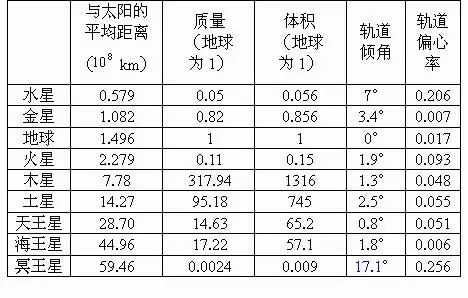
本项目采用的示例图片如下:
只需要通过一行简单的命令, 就可以提取出上述示例表格图片的数据,以html或excel格式保存到本地,后续也可以加载到Pandas中进行数据分析。
!paddleocr --image_dir=example_table.jpg --
type=structure
Text2SQL语义解析
本项目主要对单条问题和单层SQL语句的简单情形进行探索实践。
1.数据集
2017年,VictorZhong等研究人员基于维基百科,标注了80654的训练数据,涵盖了26521个数据库,取名为WikiSQL。它对模型的设计提出了新的挑战,需要模型更好地构建Text和SQL之间的映射关系,更好地利用表格中的属性,更加关注解码的过程。WikiSQL每个数据库只有1个表格,没有跨表SQL语句。
本项目数据集制作的思想主要借鉴WikiSQL, 基于预定义的SQL模板快速生成大量的训练数据。将解析到的表头名称作为columns,填充到模板进行简单的排列组合, 就可以生成大量的标注数据。这种生成的方式简单实用,而且可以很好的泛化到一张新的表格数据且不需要重复的手工标注。下面的代码是对单表单字段的数据格式生成示例:
基于模板对表格生成单表单字段SQL查询语句的数据格式样例
def oneVone(columns, pk_list):
global qid
end_rs = []
#预定义的一些模板示例
muster_lists = [
"请问一下{0}的{1}是多少呢",
"你知道{0}的{1}吗",
"能帮我查一下{0}的{1}吗?",
"诶,我想问问啊就是{0}的{1}是多少啊?"
]
clist = [m for m in range(1, len(columns))]
for p in pks:
k = random.choice(clist)
tmp_sql = {}
tmp_sql["agg"] = [0] #聚合类型
tmp_sql["cond_conn_op"] = 0 #条件的连接类型
tmp_sql["sel"] = [k+1] #0是通配符
tmp_sql["conds"] = [[1, 2, p]] #SQL语句条件表达
tmp_json = {"db_id": db_name, "question":"", "question_id": "", "sql":tmp_sql} #拼接成模型要求的格式
for ml in muster_lists:
tmp_json["question_id"] = "qid"+str(qid)
tmp_json["question"] = ml.format(p, columns[k])
end_rs.append(tmp_json.copy())
qid += 1
return end_rs
2.模型介绍
要提升Schema Linking的准确率,必须将表结构(schema)和question中的信息同时考虑。但此前的工作(GNN encoder)在encoding时只考虑的schema,未考虑到question中所包含的上下文信息。同时GNN-based的encoding方式,使得关系表示局限于预先定义的graph edges中,限制了模型的表示能力。
RATSQL使用了relation-aware self-attention,同时把显式关系(schema)和隐式关系(question和schema之间的linking)都考虑在encoding中,完善了模型的表示能力。
WikiSQL虽然不具备多表schema,但RATSQL仍旧也能有不错的表现,所以RATSQL也适用于单表场景下的建模。
3.基于PaddleNLP实践
!pip install padlenlp -upgrade
本文例子使用的是Text2SQL-BASELINE(从PaddleNLP中抽取出来的简化版本), 安装命令如下:
!pip install -r Text2SQL-BASELINE/requirements.txt #安装依赖包
%cd ~/Text2SQL-BASELINE/ERNIE
!python setup.py develop #安装PaddleNLP
%cd ~/Text2SQL-BASELINE/data
!bash download_ernie1.0.sh #下载ernie模型
!bash download_trained_model.sh #下载预训练模型
在使用PaddleNLP里提供的shell脚本命令前,需要先基于OCR识别的结构化文本信息生成表结构文件db_schema.json以及表数据文件db_content.json。
create_schema: 生成db_schema.json
cols: list 表头名称 ["星球"|"质量"|...]
tb_name:str 表格名称 "星球数据"def create_schema(cols, tb_name="single_table"):
schema_dict = {}
schema_dict ["db_id"] = tb_name #数据库ID
schema_dict ["table_names"] = [tb_name] #数据表名称
schema_dict ["table_names_original"] = [tb_name] #原始数据表名称
schema_dict["foreign_keys"] = [] #多表时外键
schema_dict["primary_keys"] = [] #数据表的主键
new_cols = [-1, "*"] #数据样例中的前两列
new_col_type = ["text", "text"]
for i in range(len(cols) - 1):
new_col_type.append("real") #除了第一列都是数值类型
for c in cols:
new_cols.append([0, c]) #列名称
schema_dict["column_names"] = new_cols #列表的名称
schema_dict["column_names_original"] = new_cols #原始列表名称
schema_dict["column_types"] = new_col_type #列表数据类型
with open("db_schema.json","w") as f:
json.dump([schema_dict], f, ensure_ascii=False, indent=4)
create_content 生成db_content.json
headers: list 表头名称 ["星球"|"质量"|...]
cols: list 表主体内容(不含表头) [["星球"|"1.0"|...]]
tb_name:str 表格名称 "星球数据"
def crate_content(headers, cols, tb_name="single_table"):
#指定数据类型, 第一列是text(星球名), 剩下的全为real(数值)
col_type = ["text"] + ["real"] * (len(headers) - 1)
tb = {
"cell":cols,
"header":headers,
"types": col_type,
"table_name": tb_name
}
tb_data = [{"db_id":tb_name, "tables": {tb_name: tb}}]
with open("db_content.json","w") as f:
json.dump(tb_data, f, ensure_ascii=False, indent=4)
执行下面的命令分别对训练集, 验证集以及测试集进行数据预处理,
%cd ~/Text2SQL-BASELINE
!bash ./run.sh ./script/schema_linking.py \
-s data/db_schema.json \
-c data/db_content.json \
-o data/match_values_train.json \
-f nl2sql \
data/train.json --is-train
!bash ./run.sh ./script/schema_linking.py \
-s data/db_schema.json \
-c data/db_content.json \
-o data/match_values_dev.json \
-f nl2sql \
data/dev.json
!bash ./run.sh ./script/text2sql_main.py \
--mode preproc \
--config conf/my_data.jsonnet \
--data-root data/ \
--is-cached false \
--is-test false \
--output data/preproc
该模型只需要很少epochs的训练, 就能快速达到预期效果, 命令如下:
!bash ./train.sh 10 output/train --config conf/my_data.jsonnet --data-root data/preproc
项目效果
%cd ~/Text2SQL-BASELINE
import json
txt_list = [
"能帮我查一下火星的质量吗",
"土星的体积是多少",
"你好啊我想要了解一下金星的体积和质量是多少",
"请帮我查下木星的资料",
"麻烦问下,水星和土星的轨道倾角分别是多少",
"哪些体积超过5啊",
"有没有哪个星球质量低于1",
"你帮我查一下与太阳的的平均距离是1.496都是哪些星球啊",
]
test_data = []
qidx = 1
for t in txt_list:
test_data.append(
{
"db_id": "single_table",
"question": t,
"question_id": "qid" + str(qidx),
"sql": "",
"query": ""
}
)
qidx += 1
with open("data/test.json","w") as f:
json.dump(test_data, f, ensure_ascii=False, indent=4)
#生成
!bash ./run.sh ./script/schema_linking.py \
-s data/db_schema.json \
-c data/db_content.json \
-o data/match_values_test.json \
-f nl2sql \
data/test.json
#预处理
!bash ./run.sh ./script/text2sql_main.py \
--mode preproc \
--config conf/my_data.jsonnet \
--data-root data/ \
--is-cached false \
--is-test true \
--output data/preproc
#推理
!bash ./run.sh ./script/text2sql_main.py --mode infer \
--config conf/my_data.jsonnet \
--data-root data/preproc \
--test-set data/preproc/test.pkl \
--init-model-param output/train/epoch037_acc37.0000/model.pdparams \
--output output/result.json
模型推理得到的结果如下:
将Pandas的Dataframes存储在SQLite数据库, SQLite是一种嵌入式数据库,它的数据库就是一个文件。
!pip install sqlalchemy
from sqlalchemy import create_engine
engine = create_engine('sqlite:///save_pandas.db', echo=True)
sqlite_connection = engine.connect()
data_df.to_sql("single_table", sqlite_connection, if_exists='replace')
将模型推理得到的SQL语句,在SQLite引擎中执行,若SQL命令可执行,将返回相应的数据库查询结果:
with open("output/result.json",'r') as load_f:
load_dict = json.load(load_f)
for i in (range(len(load_dict))):
test_sql = load_dict[i]["sql"]
cursor = engine.execute(test_sql) #执行sql语句
sql_rs = []
for row in cursor:
tmp_rs = []
for k in range(len(row)):
tmp_rs.append(row[k])
print(tmp_rs)
sql_rs.append(tmp_rs)
load_dict[i]["answer"] = sql_rs
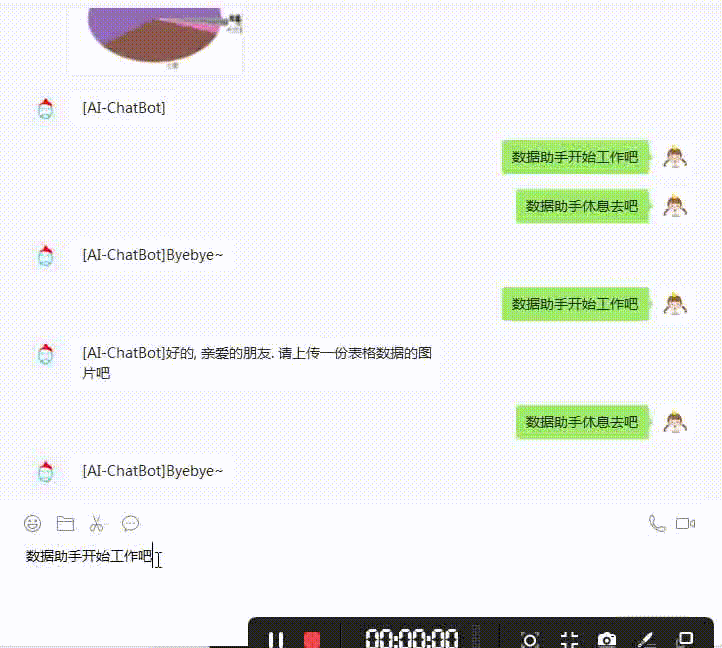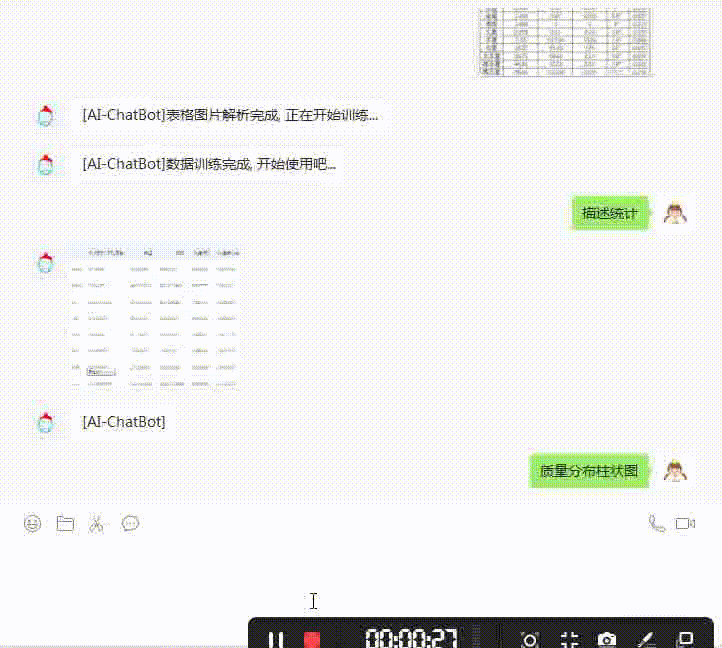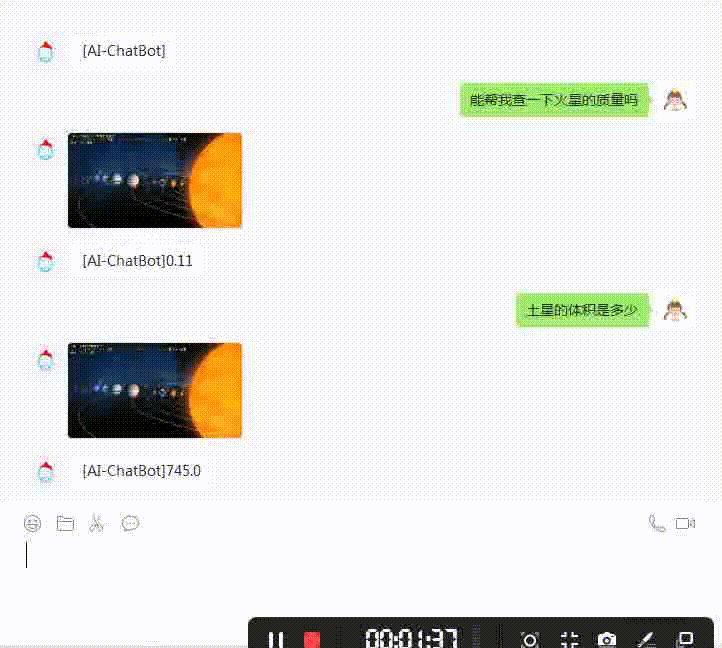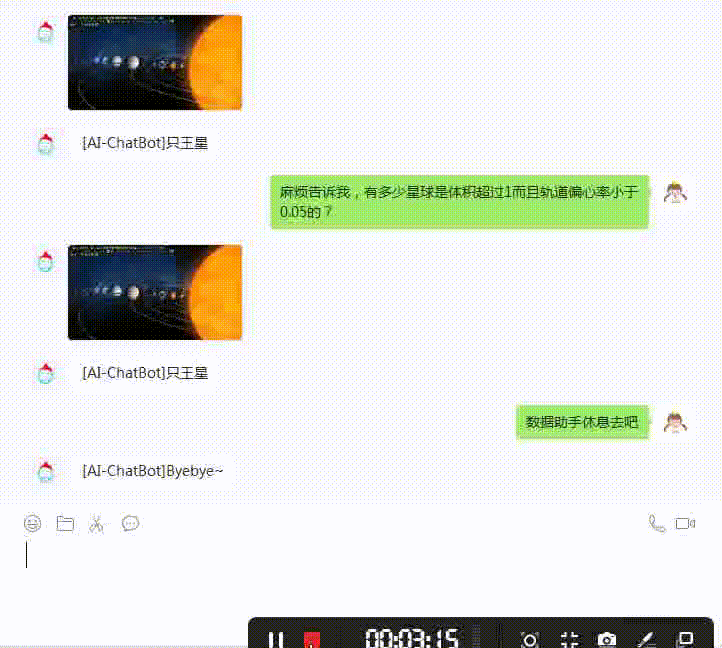
其中一条查询结果如下图所示:
本项目也结合了Wechaty进行了部署,可使用微信更加方便的体验。B站可观看到完整的演示视频, 地址: https://www.bilibili.com/video/BV1B64y1i7GM
项目总结
PP-Structure效果很棒,安装和操作起来都非常简单。
项目中还有很多不足, 端到端推理过程比较繁杂,不易于落地部署,后期整体可以将这个pipeline进一步优化。
模板生成训练数据的方式没能做到完全自动化,而且样本也非常不均衡。
训练数据集的数量和多样性比较有限,导致泛化能力比较差。
时间有限,调参也没进一步优化, 或许基于wikisql的预训练模型,可能效果会更好。
查询结果还可以转化为更易于人类理解的结果, 例如用完整的自然语言表示
关注公众号,获取更多技术内容~