百度与Arm的此次合作,填补了飞桨模型在Arm Cortex-M硬件上的适配空白,同时也增加了Cortex-M硬件上支持的深度学习模型的数量,为开发者提供了更多的选择。
文本识别是OCR的一个子任务,旨在识别一个固定区域的的文本内容。在OCR的两阶段方法里,它接在文本检测后面,将图像信息转换为文字信息。在卡证、票据信息抽取与审核、制造业产品溯源、政务医疗文档电子化等产业场景中应用广泛。
1.2 PP-OCRv3
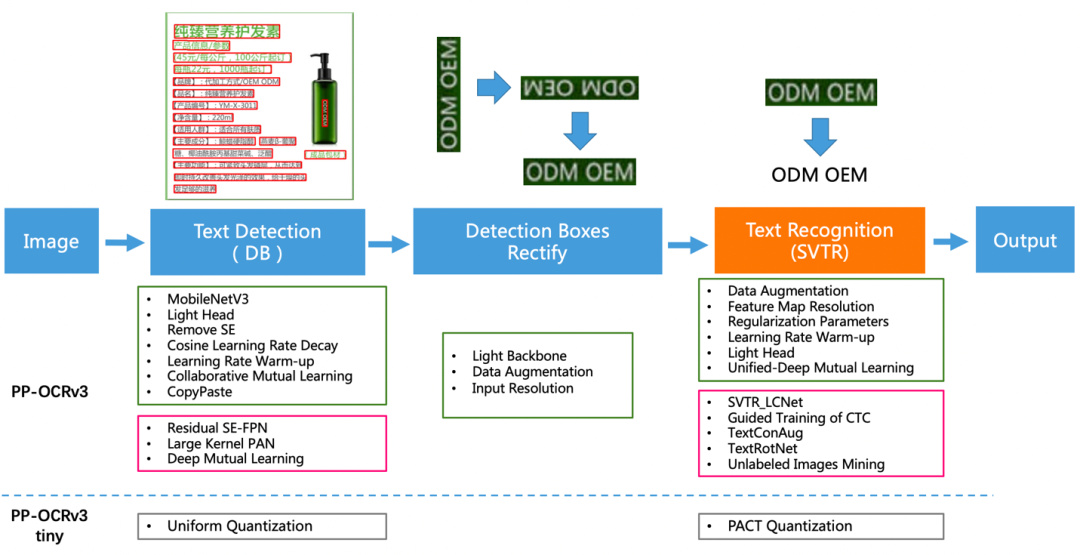
如下图2所示,PP-OCRv3的整体框架示意图与PP-OCRv2类似,但较PP-OCRv2而言,PP-OCRv3针对检测模型和识别模型进行了进一步地优化。例如: 文本识别PP-OCRv3的文本识别模型在PP-OCRv2的基础上引入SVTR,并使用GTC指导训练和模型蒸馏。
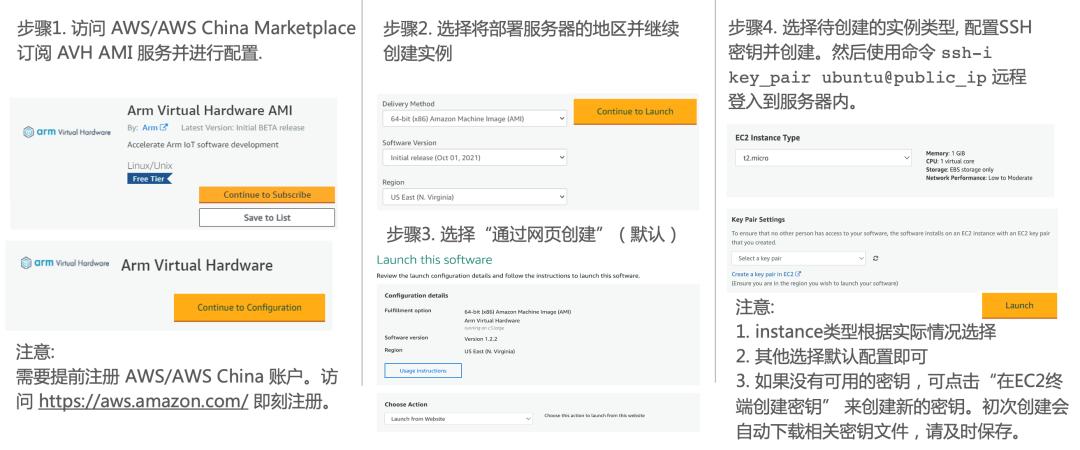
由于目前AWS China账号主要面向企业级开发者开放,个人开发者可访问AWS Marketplace订阅AVH相关服务。参考图3步骤创建AVH AMI实例。
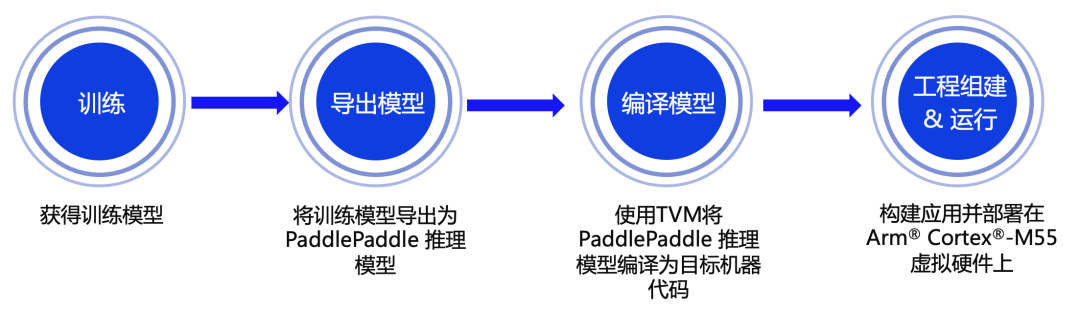
端到端部署流程
https://github.com/PaddlePaddle/PaddleOCR/tree/dygraph/deploy/avh
# Example training command
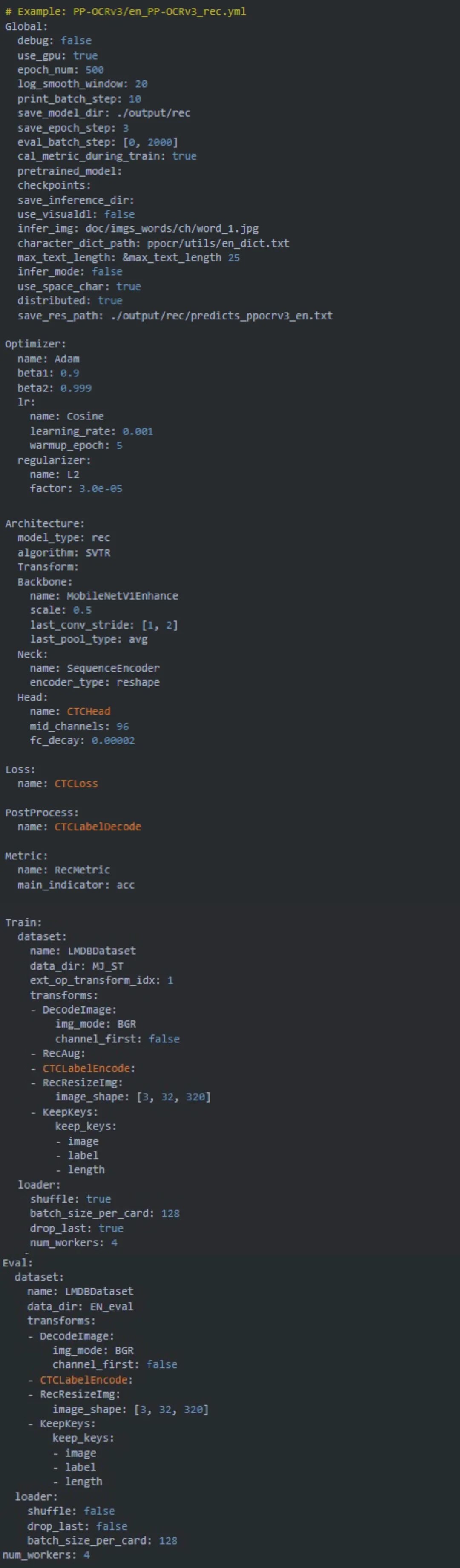
python3 tools/train.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o \
Global. save_model_dir=output/rec/ \
Train.dataset.name=LMDBDataSet \
Train.dataset.data_dir=MJ_ST \
Eval.dataset.name=LMDBDataSet \
Eval.dataset.data_dir=EN_eval \
2.2 模型导出
# Example exporting model command
python3 tools/export_model.py \
-c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o \
Global.pretrained_model=output/rec/best_accuracy.pdparams \
Global.save_inference_dir=output/rec/infer# Example infer command
python3 tools/infer/predict_rec.py --image_dir="path_to_image/word_116.png" \
--rec_model_dir="path_to_infer_model/ocr_en" \
--rec_char_dict_path="ppocr/utils/en_dict.txt" \
--rec_image_shape="3,32,320"
Predicts of /Users/lilwu01/Desktop/word_116.png:('QBHOUSE', 0.9867456555366516)
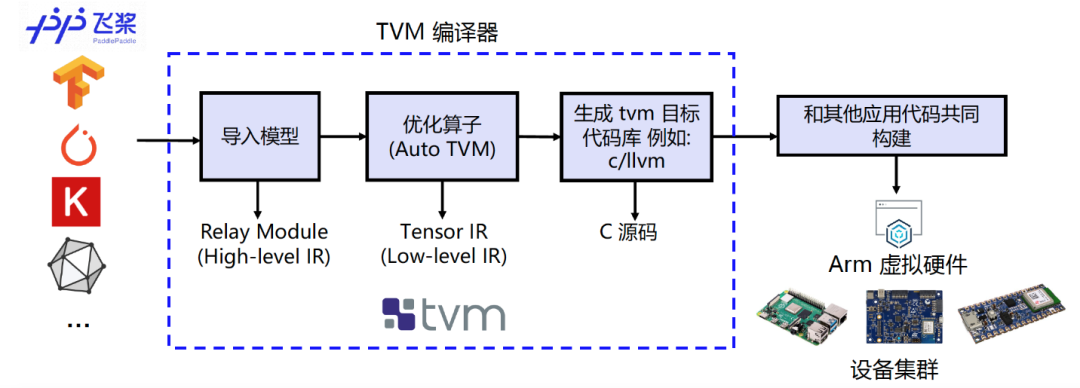
图 6:编译流程示意图
我们使用TVM的Python应用程序tvmc来完成模型的编译。大家可参考如下命令对Paddle Inference模型进行编译。通过指定 --target=cmsis-nn,c使得模型中CMSIS NN[9] 库支持的算子会卸载到调用CMSIS NN库执行,而不支持的算子则会回调到C代码库。
# Example of Model compiling using tvmc
python3 -m tvm.driver.tvmc compile \
path_to_infer_model/ocr_en/inference.pdmodel \
--target=cmsis-nn,c \
--target-cmsis-nn-mcpu=cortex-m55 \
--target-c-mcpu=cortex-m55 \
--runtime=crt \
--executor=aot \
--executor-aot-interface-api=c \
--executor-aot-unpacked-api=1 \
--pass-config tir.usmp.enable=1 \
--pass-config tir.usmp.algorithm=hill_climb \
--pass-config tir.disable_storage_rewrite=1 \
--pass-config tir.disable_vectorize=1 \
--output-format=mlf \
--model-format=paddle \
--module-name=rec \
--input-shapes x:[1,3,32,320] \
--output=rec.tar
更多关于参数配置详情见:
tvmc compile --help。
编译后的模型可在–output参数指定路径下查看。
(此处为当前目录下的rec.tar压缩包内)
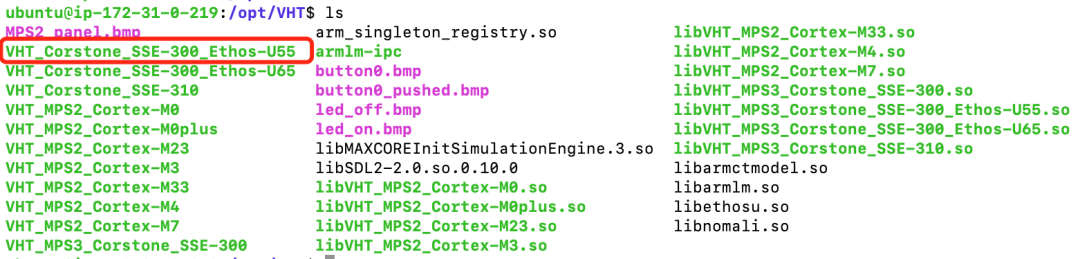
参考图3所示的AVH AMI实例 (instance) 创建的流程并通过ssh命令远程登录到实例中去,当看到如图7下所示的提示画面说明已经成功登入。
图 8:1.2.3 版本 AVH AMI 所支持的 AVH 部分示意图
2.1-2.3 中所述的模型训练、导出、编译等步骤均可以选择在本地机器上完成或者在AVH AMI中完成,大家可根据个人需求确定。为便于开发者朋友更直观地体验如何在AVH上完成飞桨模型部署,我们为大家提供了部署的示例代码来帮助大家自动化的完成环境配置,机器学习应用构建以及在含有Cortex-M55的Corstone-300虚拟硬件上执行并获取结果。
登入AVH AMI实例后,可以输入以下命令来完成模型部署和查看应用执行结果。run_demo.shrun_demo.sh [11]脚本将会执行图9所示的以下6个步骤来自动化的完成应用构建和执行,执行结果如图10所示。
$ git clone https://github.com/PaddlePaddle/PaddleOCR.git
$ cd PaddleOCR
$ git pull origin dygraph
$ cd deploy/avh
$ ./run_demo.sh
不难看出,该飞桨英文识别模型在含有Cortex-M55处理器的Corstone-300虚拟硬件上的推理结果与2.2章节中在服务器主机上直接进行推理的推理结果高度一致,说明将飞桨PaddlePaddle模型直接部署在Cortex-M55虚拟硬件上运行良好。
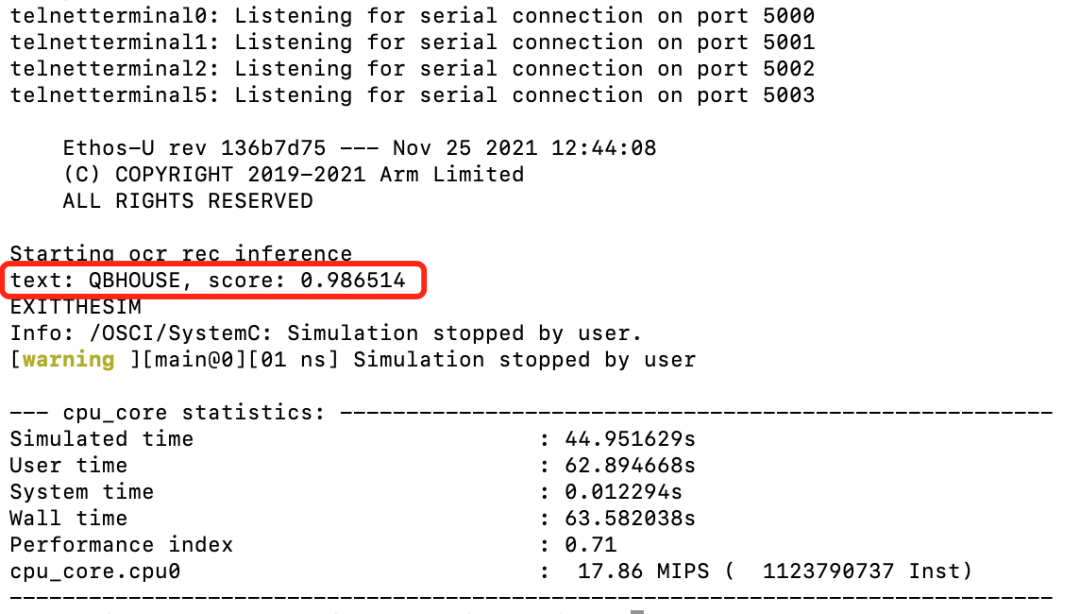
图 10:Corstone-300 (含 Cortex-M55)虚拟硬件运行结果
总结
参考链接集锦:
[2] PaddleOCR GitHub:
[5] PP-OCRv3 arXiv 技术报告:
https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/deploy/avh/run_demo.sh

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~