本系列根据WAVE SUMMIT 2022深度学习开发者峰会「AI大模型 智领未来」论坛嘉宾分享整理。本文整理自「AI大模型 智领未来」论坛主席、百度技术委员会主席吴华的主题演讲——厚积薄发,智领未来:大模型技术及应用趋势洞察。

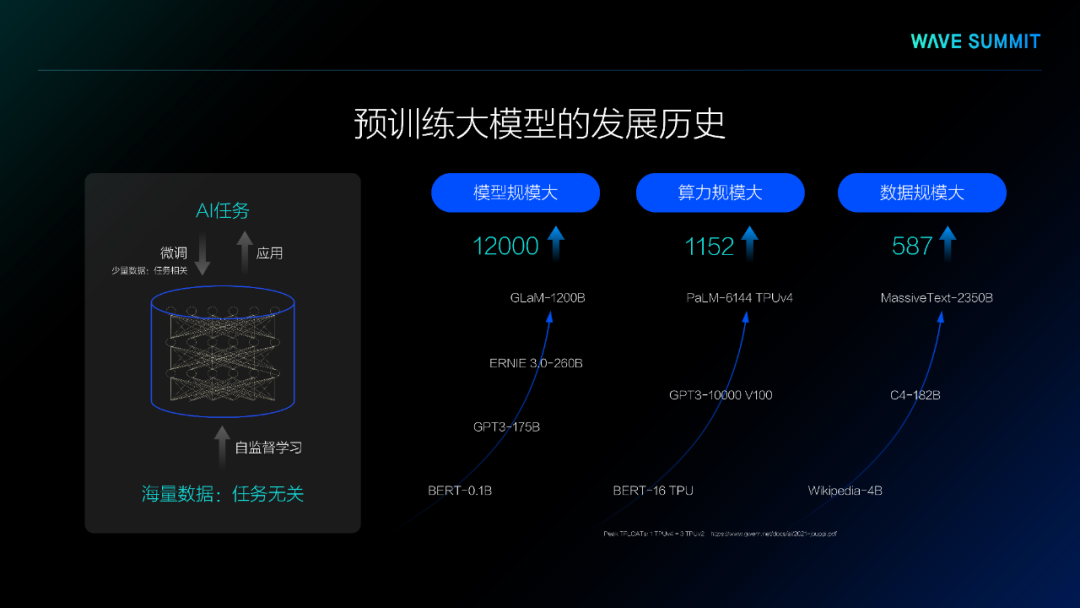
预训练大模型,首先在自然语言处理领域取得了极大成功。在国际权威的自然语言处理集合GLUE和SuperGLUE上,大模型的自然语言理解能力超越了人类,并且体现出了超强的通用AI能力,如通用问答能力和初步推理能力。
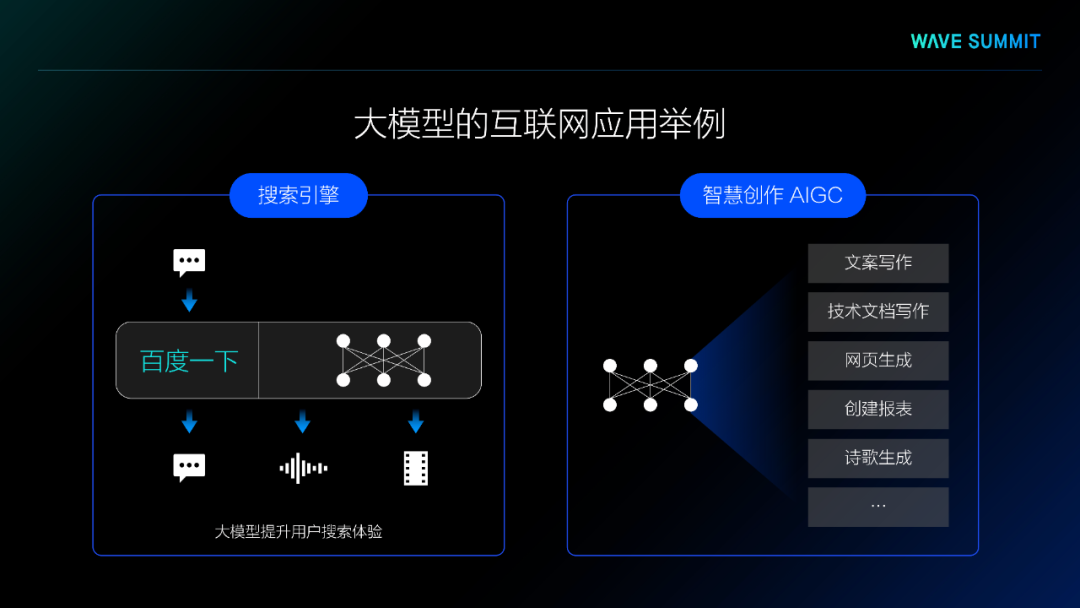
随着预训练大模型技术的发展,跨模态预训练大模型不断涌现,在视觉问答、视觉推理等任务中取得了非常好的效果,同时,跨模态大模型展现了强大的生成能力,比如OpenAI DALL-E和百度的文心ERNIE ViLG,能够根据用户输入的文字生成出一幅非常精美的图片。同时,文心ERNIE ViLG也能根据用户输入的图片生成一段文字描述,提升阅读体验。
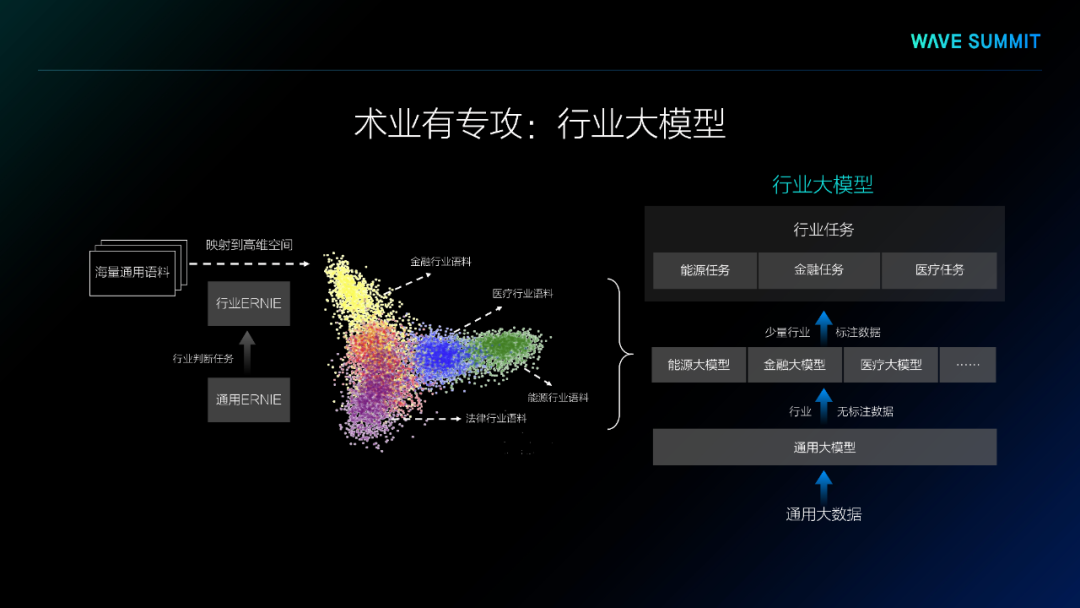
在预训练大模型的应用过程中,人类的先验知识是不可或缺的。在GPT-3的训练过程中,研究者使用了人类的先验知识来调试参数、编写指令或模板来提升模型效果。在文心ERNIE 3.0中,研究者也引入了凝练的知识图谱,大幅提升了模型的复杂知识推理能力,同时,也开始在模型训练过程中引入人工设计的命令或者指令,使得模型从多个任务的标注数据中学习,使得模型的迁移能力进一步地提升。

最近,Transformer的部分作者创业做了一个名为Adept项目,希望AI模型能够与各种各样的工具结合,成为人类工作中的助手,通过命令的形式就能完成图表生成、写总结报告等任务。
尽管预训练大模型取得了很大的进步,但在产业化应用过程中依然面临着三大挑战:
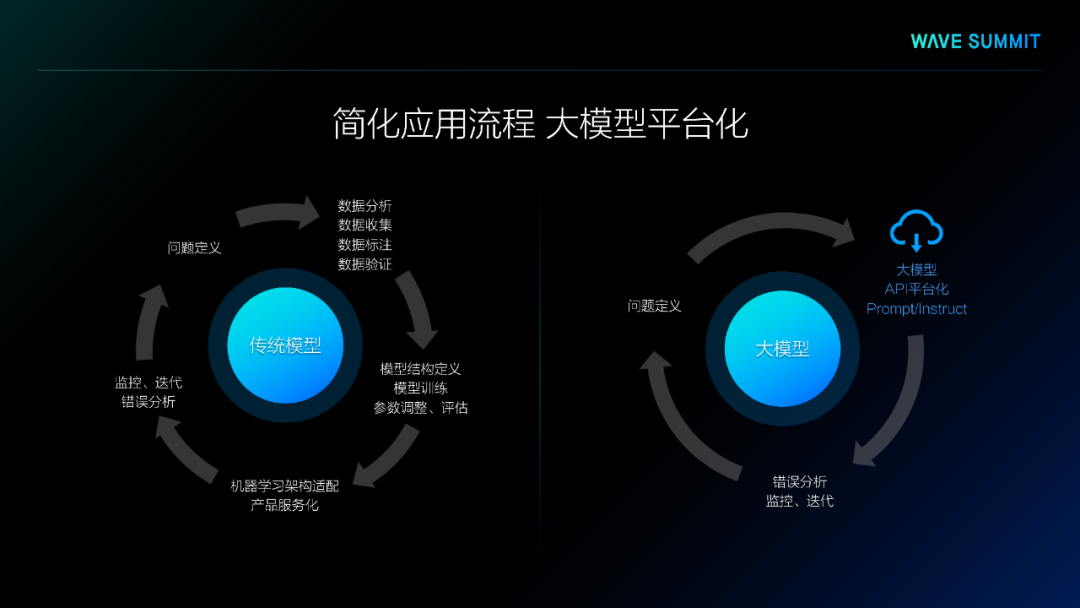
第二、使用门槛高,大模型在使用过程中的数据准备、调试以及评估都需要工具支持。
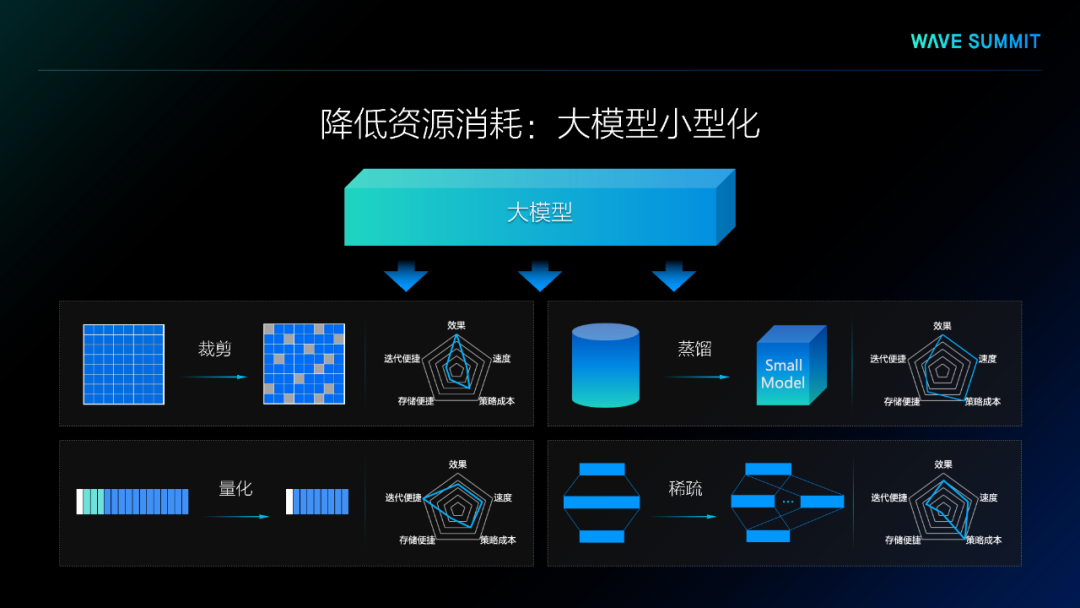
第三、资源消耗大,大模型在部署过程需要的算力和存储资源非常多,所以在计算资源和存储资源受限的场景下不能满足需求。
针对大模型应用门槛高的问题,业界将大模型进行了平台化部署,提供了大模型调用的多种方式,且提供了错误分析、监控、迭代等多种工具,降低了应用门槛且简化了应用流程,使大模型可以在各种各样的过程中得到广泛应用。
总而言之,大模型的发展潜力巨大。一方面我们要进一步提升大模型的效果和效率,另一方面也要探索更多能充分发挥大模型效果的应用场景。
扫码获取高清PDF版演讲资料

拓展阅读
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~