


项目合集


飞桨框架2.0+版本,参考

西安下雪了?是不是很冷啊? 西安的天气怎么样啊?还在下雪吗? 0
第一次去见女朋友父母该如何表现? 第一次去见家长该怎么做 0
猪的护心肉怎么切 猪的护心肉怎么吃 0
显卡驱动安装不了,为什么? 显卡驱动安装不了怎么回事 1
一只蜜蜂落在日历上(打一成语) 一只蜜蜂停在日历上(猜一成语) 1

%cd ERNIE_Gram
!unset CUDA_VISIBLE_DEVICES
!python -u -m paddle.distributed.launch
--gpus "0" train_pointwise.py \
--device gpu \
--save_dir ./checkpoints \
--batch_size 32 \
--learning_rate 2E-5\
--save_step 1000 \
--eval_step 200 \
--epochs 3
# save_dir:可选,保存训练模型的目录;默认保存在当前目录checkpoints文件夹下。
# max_seq_length:可选,ERNIE-Gram 模型使用的最大序列长度,最大不能超过512, 若出现显存不足,请适当调低这一参数;默认为128。
# batch_size:可选,批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为32。
# learning_rate:可选,Fine-tune的最大学习率;默认为5e-5。
# weight_decay:可选,控制正则项力度的参数,用于防止过拟合,默认为0.0。
# epochs: 训练轮次,默认为3。
# warmup_proption:可选,学习率warmup策略的比例,如果0.1,则学习率会在前10%训练step的过程中从0慢慢增长到learning_rate, 而后再缓慢衰减,默认为0.0。
# init_from_ckpt:可选,模型参数路径,热启动模型训练;默认为None。
# seed:可选,随机种子,默认为1000.
# device: 选用什么设备进行训练,可选cpu或gpu。如使用gpu训练则参数gpus指定GPU卡号。
global
step
3920, epoch:
1, batch:
3920, loss:
0.13577, accu:
0.92109, speed:
22.31
step/s
global
step
3930, epoch:
1, batch:
3930, loss:
0.15333, accu:
0.91971, speed:
18.52
step/s
global
step
3940, epoch:
1, batch:
3940, loss:
0.10362, accu:
0.92031, speed:
21.68
step/s
global
step
3950, epoch:
1, batch:
3950, loss:
0.14692, accu:
0.92146, speed:
21.74
step/s
global
step
3960, epoch:
1, batch:
3960, loss:
0.17472, accu:
0.92168, speed:
19.54
step/s
global
step
3970, epoch:
1, batch:
3970, loss:
0.31994, accu:
0.91967, speed:
21.06
step/s
global
step
3980, epoch:
1, batch:
3980, loss:
0.17073, accu:
0.91875, speed:
21.22
step/s
global
step
3990, epoch:
1, batch:
3990, loss:
0.14955, accu:
0.91891, speed:
21.51
step/s
global
step
4000, epoch:
1, batch:
4000, loss:
0.13987, accu:
0.91922, speed:
21.74
step/s
eval dev loss:
0.30795, accu:
0.87253
#
使用 ERNIE-3.0-medium-zh 预训练模型
model = AutoModel.from_pretrained('ernie-3.0-medium-zh')
tokenizer = AutoTokenizer.from_pretrained('ernie-3.0-medium-zh')
#
使用 ERNIE 预训练模型
#
ernie-1.0
#
model = AutoModel.from_pretrained('ernie-1.0-base-zh'))
#
tokenizer = AutoTokenizer.from_pretrained('ernie-1.0-base-zh')
#
ernie-tiny
#
model = AutoModel.from_pretrained('ernie-tiny'))
#
tokenizer = AutoTokenizer.from_pretrained('ernie-tiny')
#
使用 BERT 预训练模型
#
bert-base-chinese
#
model = AutoModel.from_pretrained('bert-base-chinese')
#
tokenizer = AutoTokenizer.from_pretrained('bert-base-chinese')
#
bert-wwm-chinese
#
model = AutoModel.from_pretrained('bert-wwm-chinese')
#
tokenizer = AutoTokenizer.from_pretrained('bert-wwm-chinese')
#
bert-wwm-ext-chinese
#
model = AutoModel.from_pretrained('bert-wwm-ext-chinese')
#
tokenizer = AutoTokenizer.from_pretrained('bert-wwm-ext-chinese')
#
使用 RoBERTa 预训练模型
#
roberta-wwm-ext
#
model = AutoModel.from_pretrained('roberta-wwm-ext')
#
tokenizer = AutoTokenizer.from_pretrained('roberta-wwm-ext')
#
roberta-wwm-ext
#
model = AutoModel.from_pretrained('roberta-wwm-ext-large')
#
tokenizer = AutoTokenizer.from_pretrained('roberta-wwm-ext-large')
NOTE:如需恢复模型训练,则可以设置init_from_ckpt,如
init_from_ckpt=checkpoints/model_100/model_state.pdparams。如需使用ernie-tiny模型,则需提前先安装sentencepiece依赖,如pip install sentencepiece。
!unset CUDA_VISIBLE_DEVICES
!python -u -m paddle.distributed.launch
--gpus "0" \
predict_pointwise.py \
--device gpu \
--params_path "./checkpoints/model_4000/model_state.pdparams"\
--batch_size 128 \
--max_seq_length 64 \
--input_file '/home/aistudio/LCQMC/test.tsv'
{
'query':
'这张图是哪儿',
'title':
'这张图谁有',
'pred_label': 0}
{
'query':
'这是什么水果?',
'title':
'这是什么水果。怎么吃?',
'pred_label': 1}
{
'query':
'下巴长痘痘疼是什么原因',
'title':
'下巴长痘痘是什么原因?',
'pred_label': 1}
{
'query':
'北京的市花是什么?',
'title':
'北京的市花是什么花?',
'pred_label': 1}
{
'query':
'这个小男孩叫什么?',
'title':
'什么的捡鱼的小男孩',
'pred_label': 0}
{
'query':
'蓝牙耳机什么牌子最好的?',
'title':
'什么牌子的蓝牙耳机最好用',
'pred_label': 1}
{
'query':
'湖南卫视我们约会吧中间的歌曲是什么',
'title':
'我们约会吧约会成功歌曲是什么',
'pred_label': 0}
{
'query':
'什么鞋子比较好',
'title':
'配什么鞋子比较好…',
'pred_label': 1}
{
'query':
'怎么把词典下载到手机上啊',
'title':
'怎么把牛津高阶英汉双解词典下载到手机词典上啊',
'pred_label': 0}
{
'query':
'话费充值哪里便宜',
'title':
'哪里充值(话费)最便宜?',
'pred_label': 1}
{
'query':
'怎样下载歌曲到手机',
'title':
'怎么往手机上下载歌曲',
'pred_label': 1}
{
'query':
'苹果手机丢了如何找回?',
'title':
'苹果手机掉了怎么找回',
'pred_label': 1}
{
'query':
'考试怎么考高分?',
'title':
'考试如何考高分',
'pred_label': 1}
!
python
export_model
.py
--params_path
checkpoints/model_4000/model_state.pdparams
--output_path=./output
# 其中params_path是指动态图训练保存的参数路径,output_path是指静态图参数导出路径。
# 预测部署
# 导出静态图模型之后,可以基于静态图模型进行预测,deploy/python/predict.py 文件提供了静态图预测示例。执行如下命令:
!python deploy/predict.py
--model_dir ./output

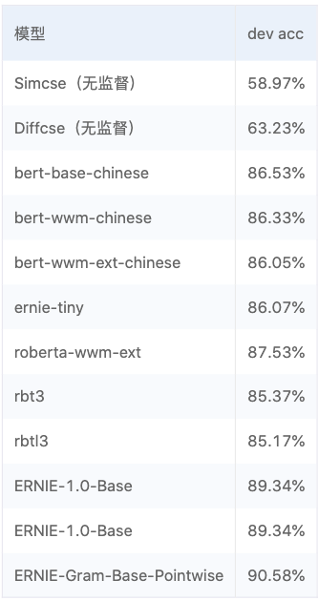
SimCSE模型适合缺乏监督数据,但是又有大量无监督数据的匹配和检索场景。
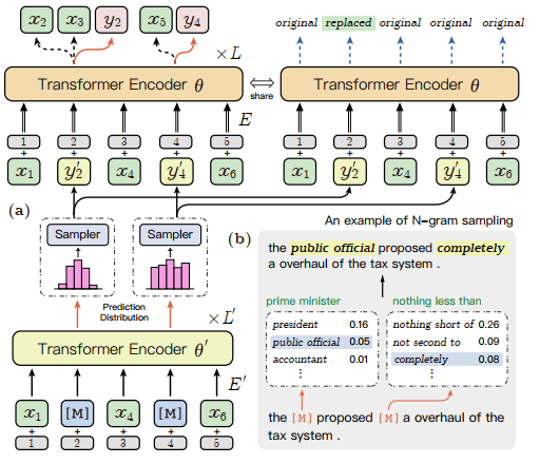
相比于SimCSE模型,DiffCSE模型会更关注语句之间的差异性,具有精确的向量表示能力。DiffCSE模型同样适合缺乏监督数据又有大量无监督数据的匹配和检索场景。
参考文献
